원래 공부해야하는 영상은 사실 GPT2 from scratch인데,
예전에 공부한 것을 까먹어서...다시 작성을 해본다.
아주 힘든 일이 되겠지만, 그래도 처음부터 공부하는 게 맞는 거 같다!!
예전에 김성범 교수님의 강의를 들었었는데, 이번에도 기억을 되살리기 위해 그분 강의를 듣고자 한다!
RNN
시계열 데이터
데이터가 시간에 따라 얻어졌다면, 시간의 영향을 받을 것이다.
시간의 영향을 받게 되는 이런 데이터를 시계열 데이터!
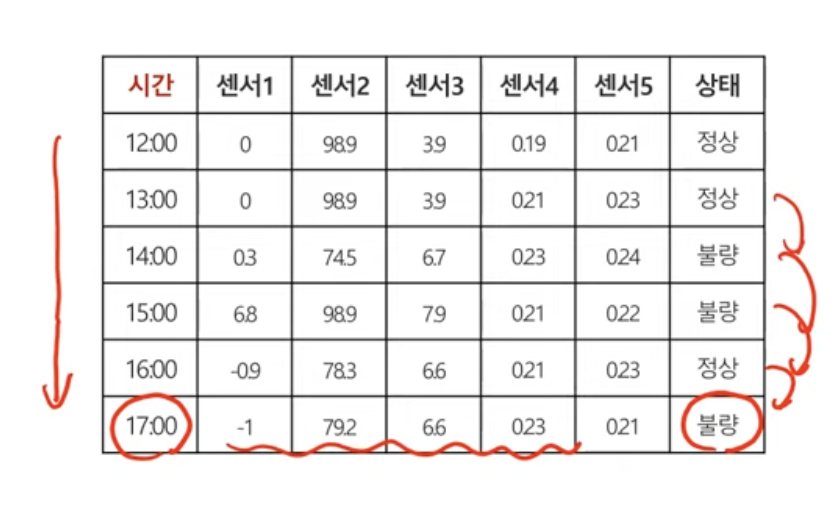
선형회귀,로지스틱회귀,뉴럴네트워크
선형 회귀 모델은 가중치들을 결합해서 f(X)를 만들어내는 것이고,
로지스틱 회귀 모델은 선형회귀 값을 이용해 0~1사이의 확률값을 만들어내는 것이다.
마지막으로 뉴럴 네트워크 모델은 로지스틱 회귀 모델을 여러번 결합한 것이다. 여기서 보면, 로지스틱 회귀 모델이 안쪽에서 두번 그리고 바깥쪽에서 한번 이렇게 되어서 총 3번이 들어간 것을 알 수 있다.
이건 인풋값은 X1,X2고 은닉층(hidden layer)는 두개의 노드가 존재하고 마지막 출력층에는 한개의 노드가 존재한다.
하지만, RNN계열 모델을 다룰 때에는 
뒤집어서 보는 게 편하다고 한다.
DNN 모델
독립이라고 가정할 때: 각각 시점의 정보들만 이용해서 hidden vector를 구한다. 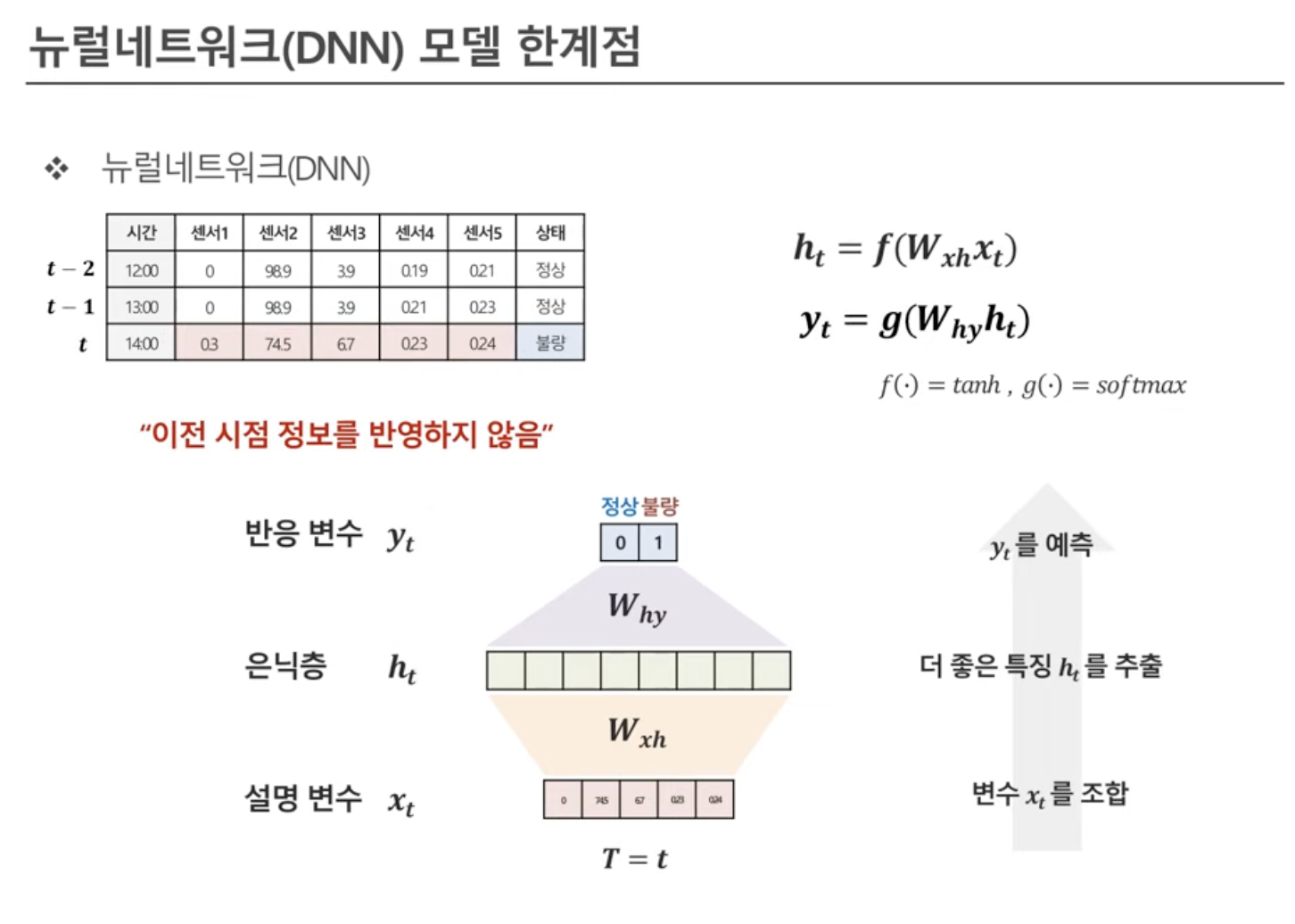
독립인 데이터들은 이전 시점의 정보를 전혀 반응하지 않는다.
RNN 모델의 필요성
독립이 아니라고 가정할 때: 이전 시점의 정보를 당연히 반영해야 한다.
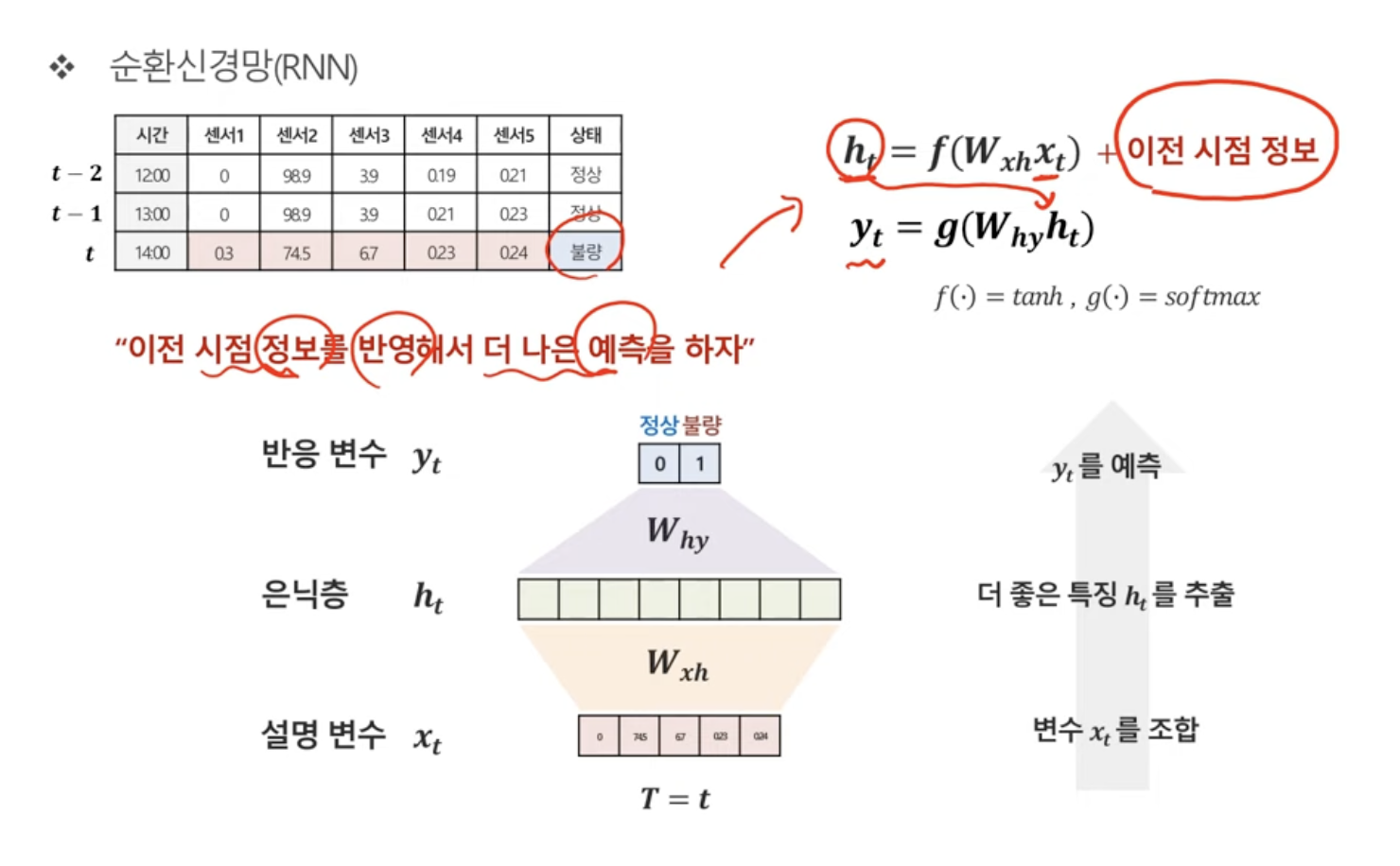
그럼 어떻게 이전 시점의 정보를 반영할까?
RNN 모델
t시점의 상태를 예측한다고 할 때,
t-1 시점의 정보를 사용하는 방법은 다음과 같다.
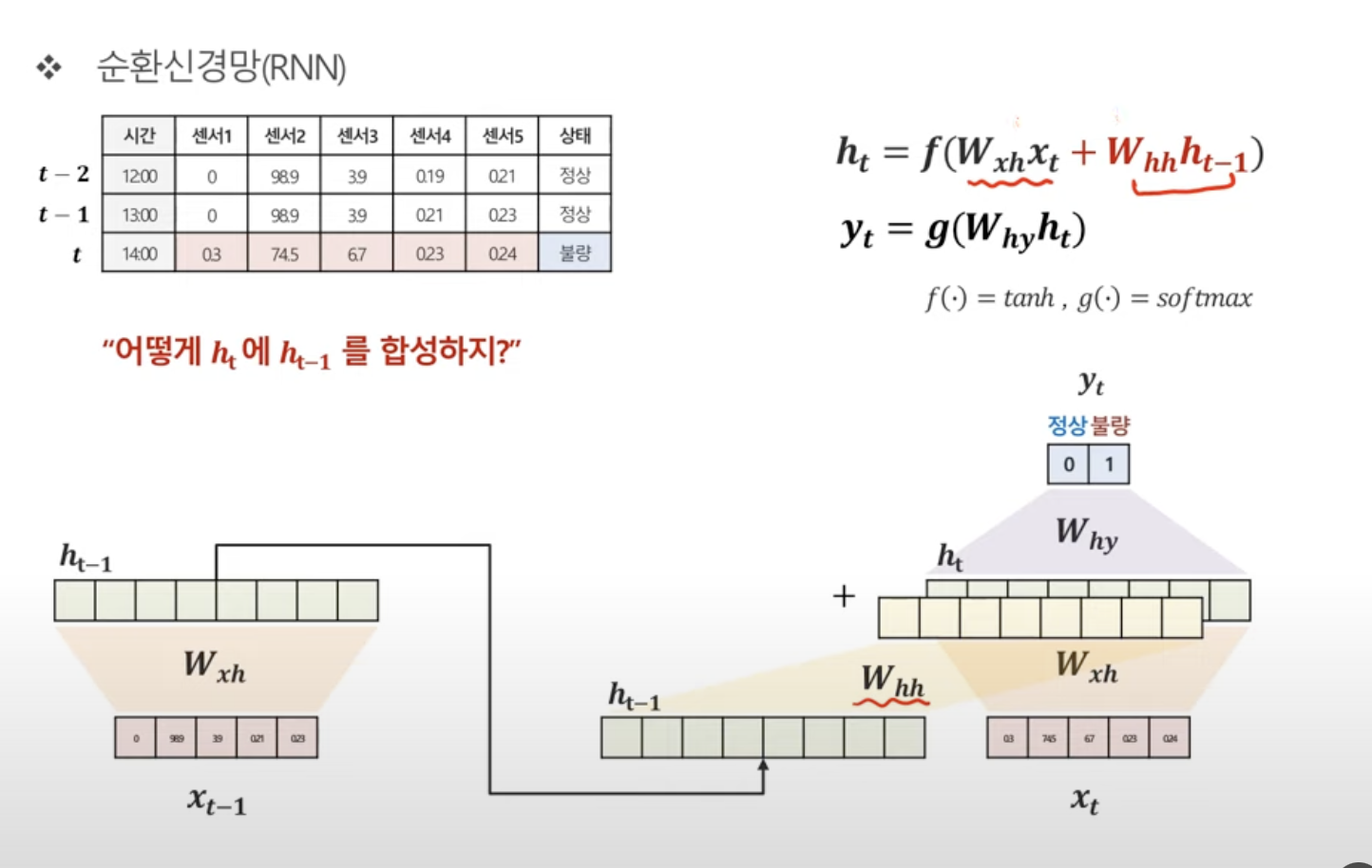
t시점의 h구하기
1. t-1시점의 hidden vector구하기
2. t-1시점의 hidden vector에 가중치 곱하기
3. t 시점의 hidden vector구하기
4. 2번과 3번을 합치고 활성화 함수 적용시키기 (tanh)
t시점의 y구하기
1. t시점의 h에 가중치를 곱한다.
2. 활성화 함수 적용시키기 (softmax)
단순 궁금점...
과연 더하는 것만으로도 t-1시점의 정보가 반영이 되는 걸까? 왜 더하는 것일까? 곱하는 방법도 있을텐데. 그리고 왜 이전시점의 hidden vector를 현시점의 hidden vector에 더하기 위해서는 가중치를 곱해야하는 걸까?!
: 가중치 행렬은 , 이전 시점의 hidden state의 각 요소가 현 시점의 hidden state에 얼마나 중요한지를 반영합니다. 이를 통해 모델이 학습을 통해 중요한 패턴을 인식하고, 덜 중요한 정보를 걸러낼 수 있습니다.
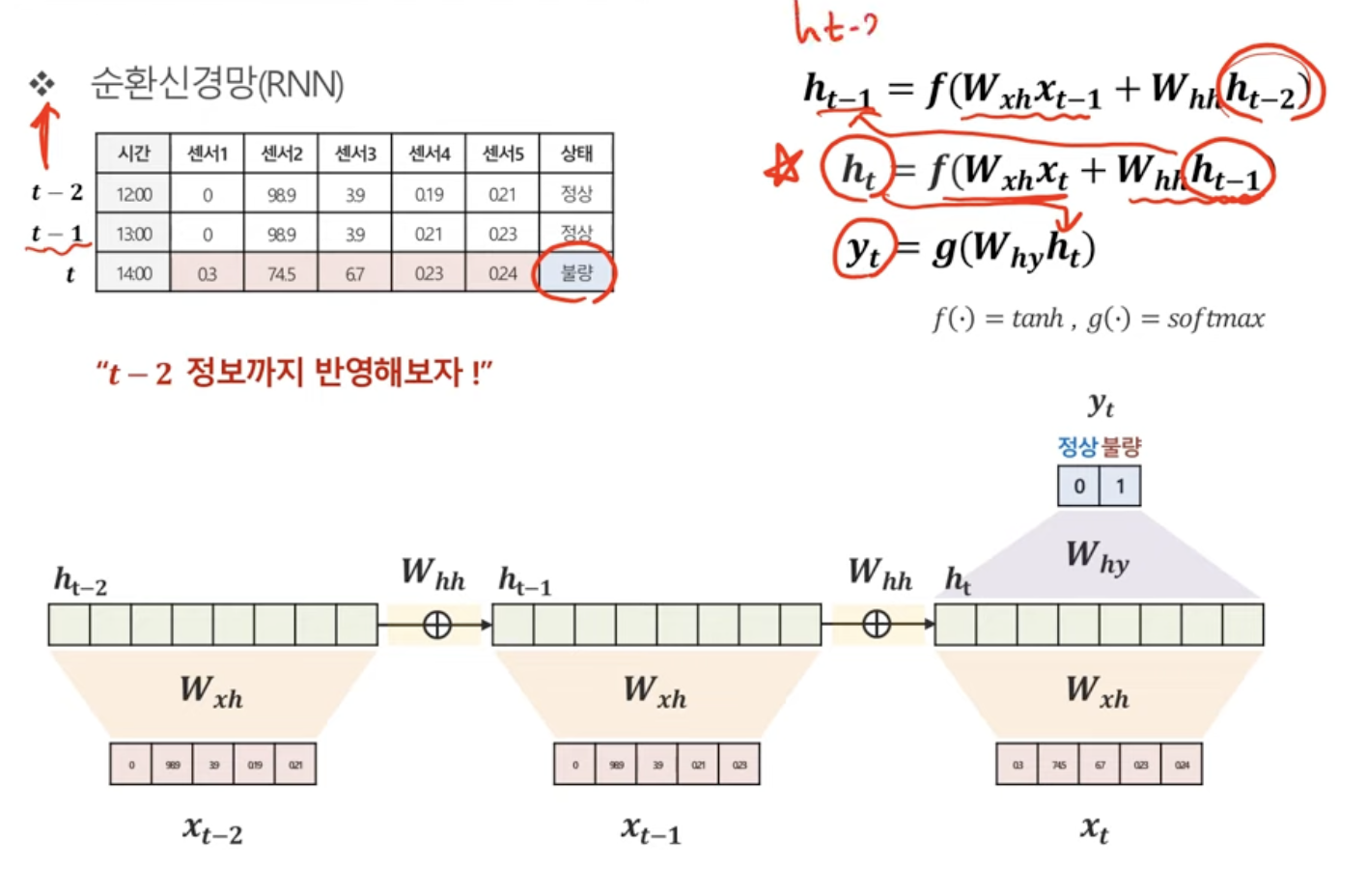
t시점의 상태를 예측한다고 할 때,
t-1 시점과 t-2 시점의 정보를 사용하는 방법은 다음과 같다.
t시점의 h구하기
1. t-1시점의 hidden vector구하기
2. t-1시점의 hidden vector에 가중치 곱하기
3. t 시점의 hidden vector구하기
4. 2번과 3번을 합치고 활성화 함수 적용시키기 (tanh)
t-1시점의 h구하기
1. t-2시점의 hidden vector구하기
2. t-2시점의 hidden vector에 가중치 곱하기
3. t-1 시점의 hidden vector구하기
4. 2번과 3번을 합치고 활성화 함수 적용시키기 (tanh)
계속해서 이전의 정보를 포함시키고 있음.
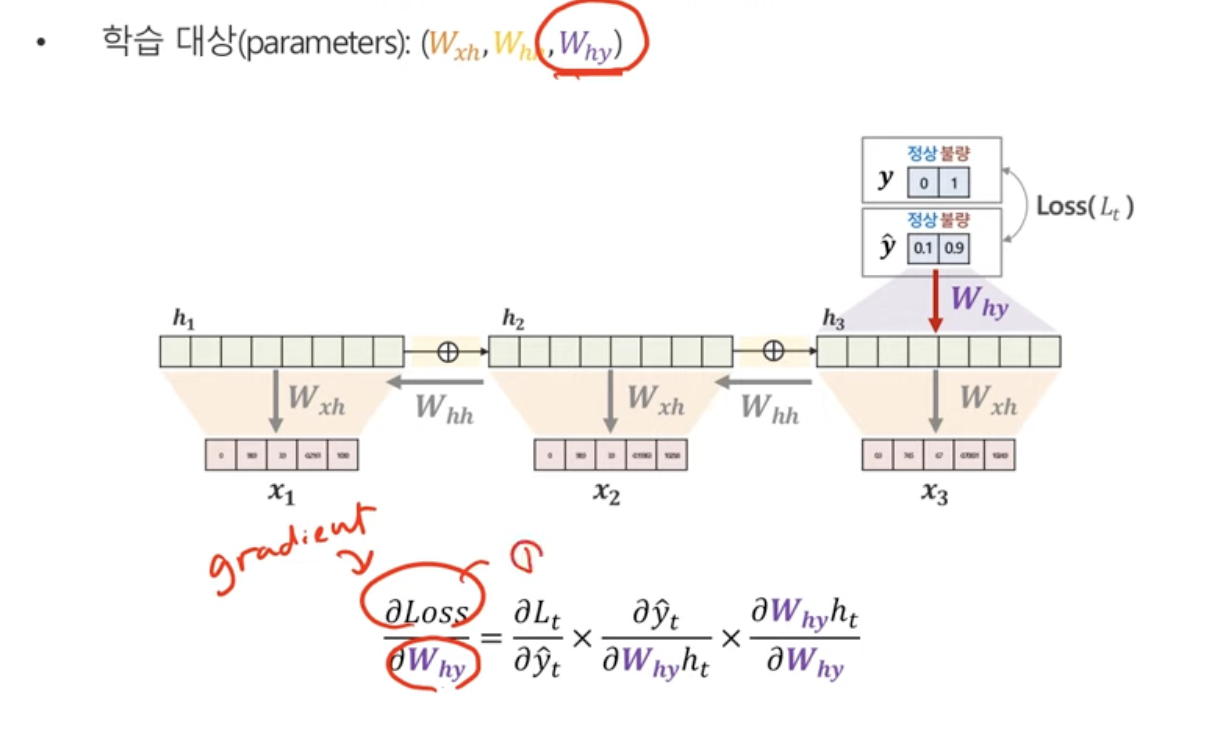
RNN에서 추정해야하는 파라미터
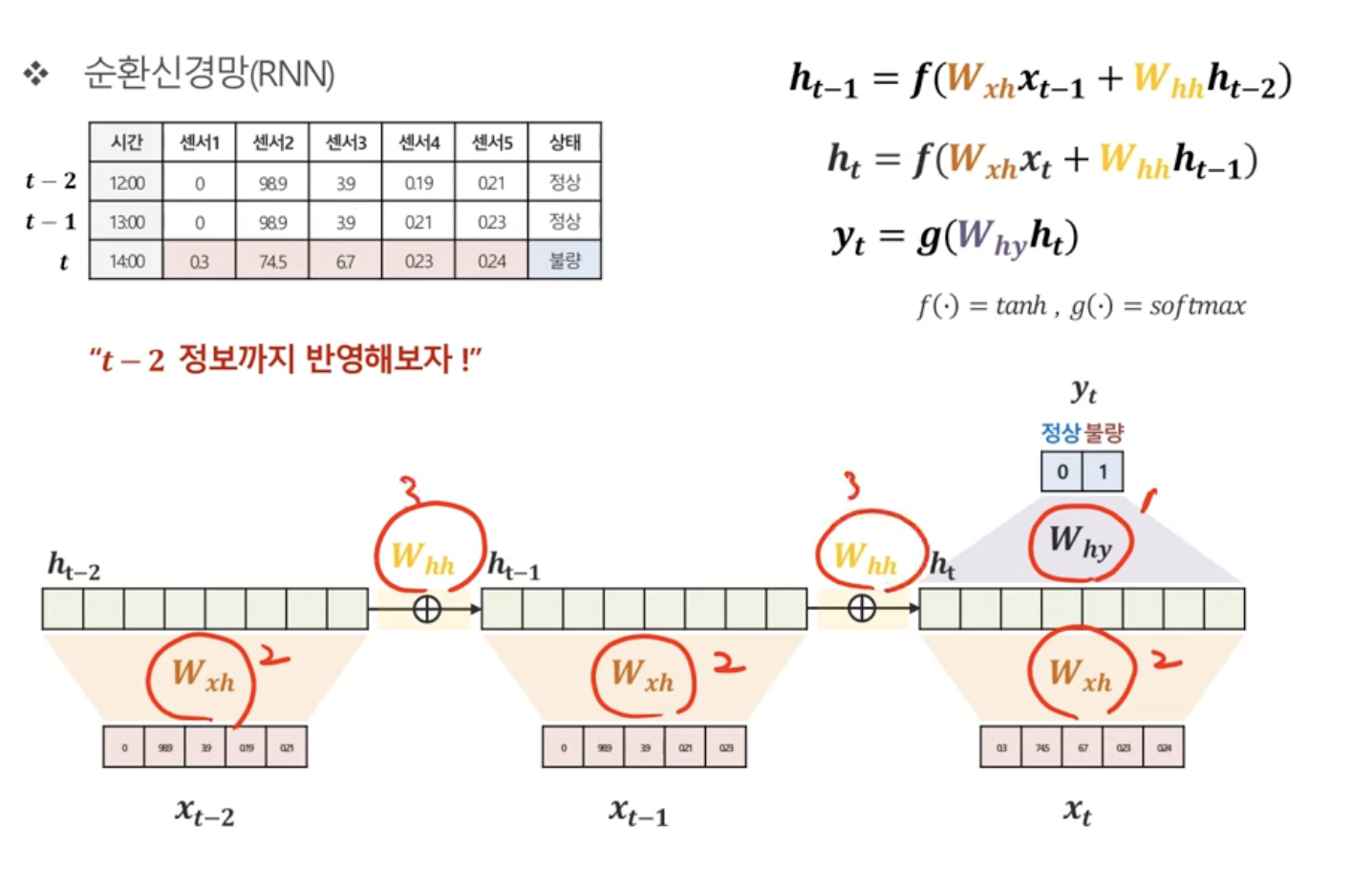
이렇게 3가지 종류의 파라미터를 예측하면 됨.
Why는 h에서 y로 갈때의 가중치
Wxh는 x에서 h로 갈때의 가중치
Whh는 h에서 h로 갈때의 가중치
중요한 건, 모든 시점마다 파라미터가 같다는 것!
즉, 시점에 관계없이 동일한 값을 갖고 있는 파라미터다!
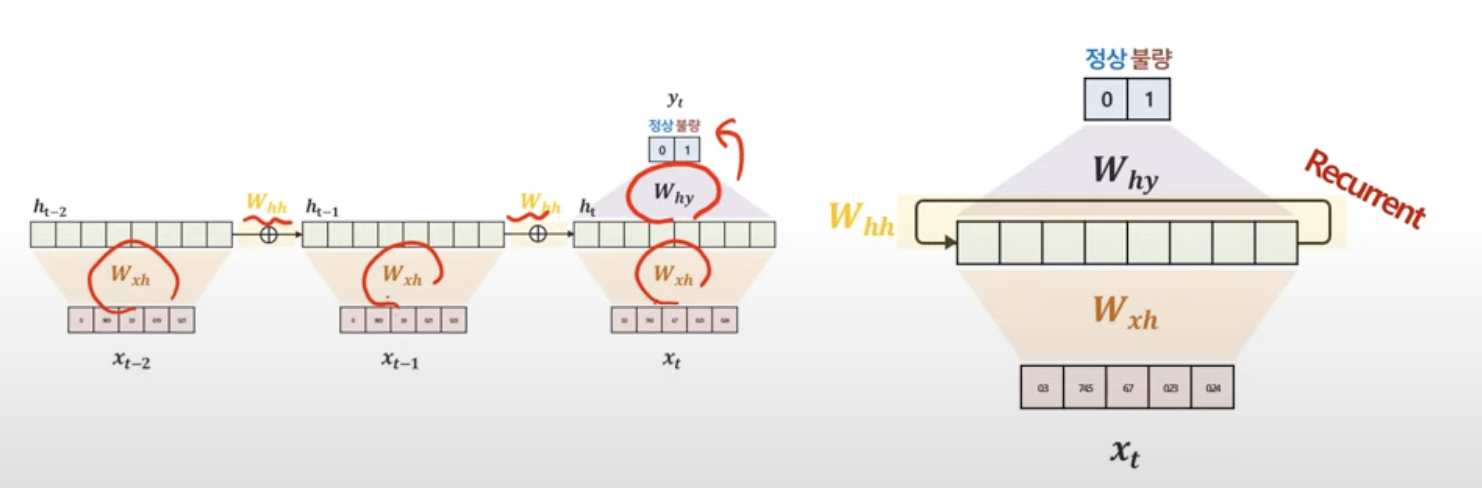
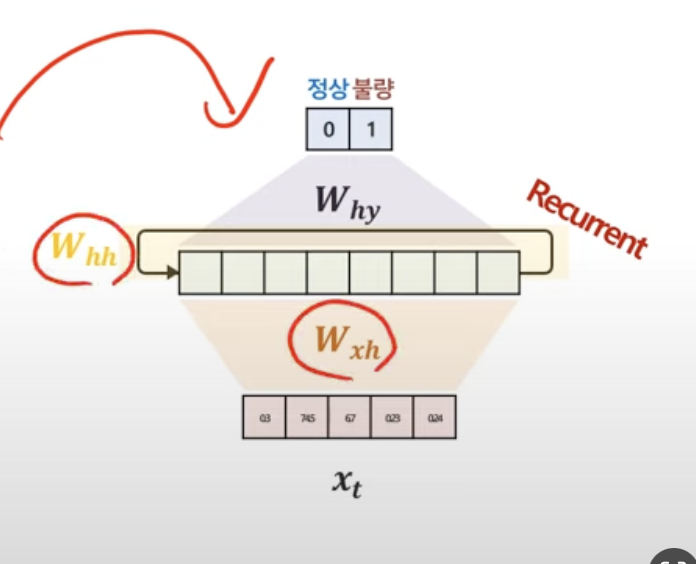
그렇다면, 시점에 관계없이 동일한 값이라면...이걸 한꺼번에 표현할 수 없을까??해서
아래처럼 표현한다.
RNN 구조 다양성
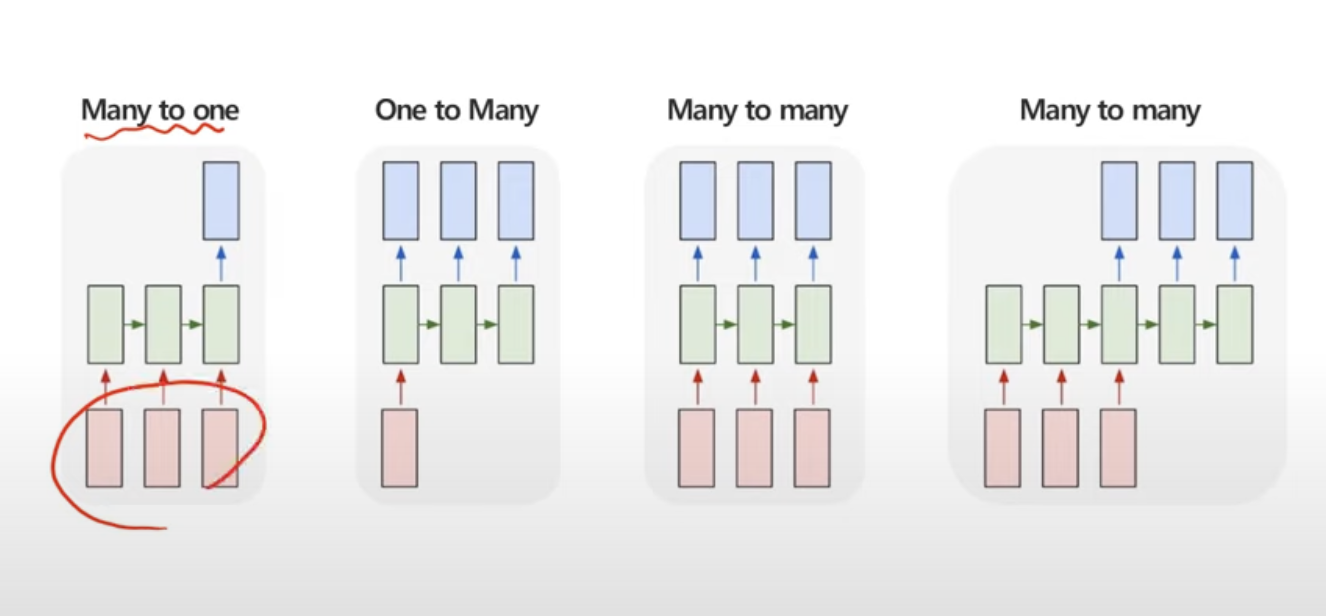
Many to One 구조
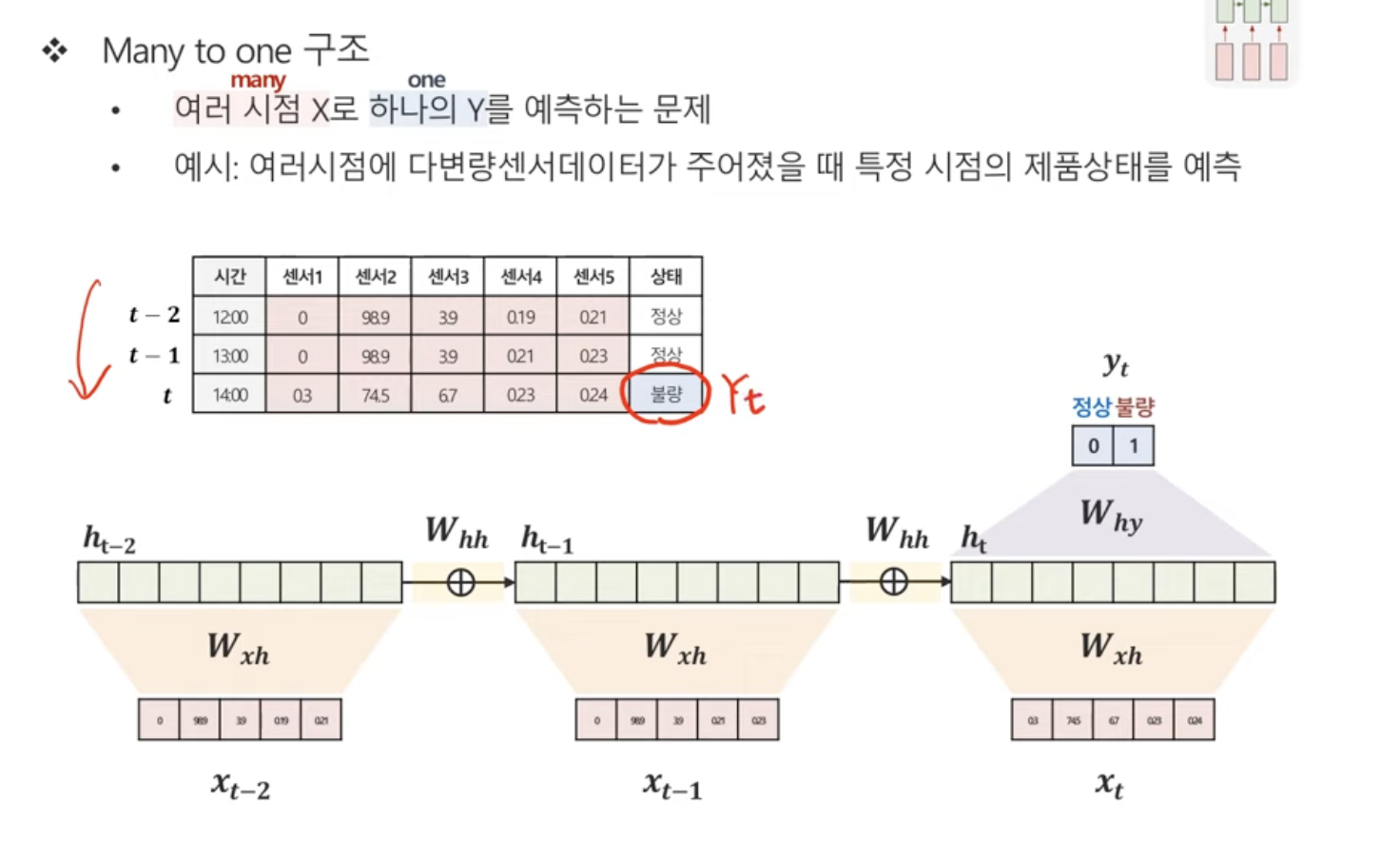
현시점의 X와 가중치를 곱한 것 + 이전 시점의 hidden state와 가중치를 곱한 것
One to Many 구조
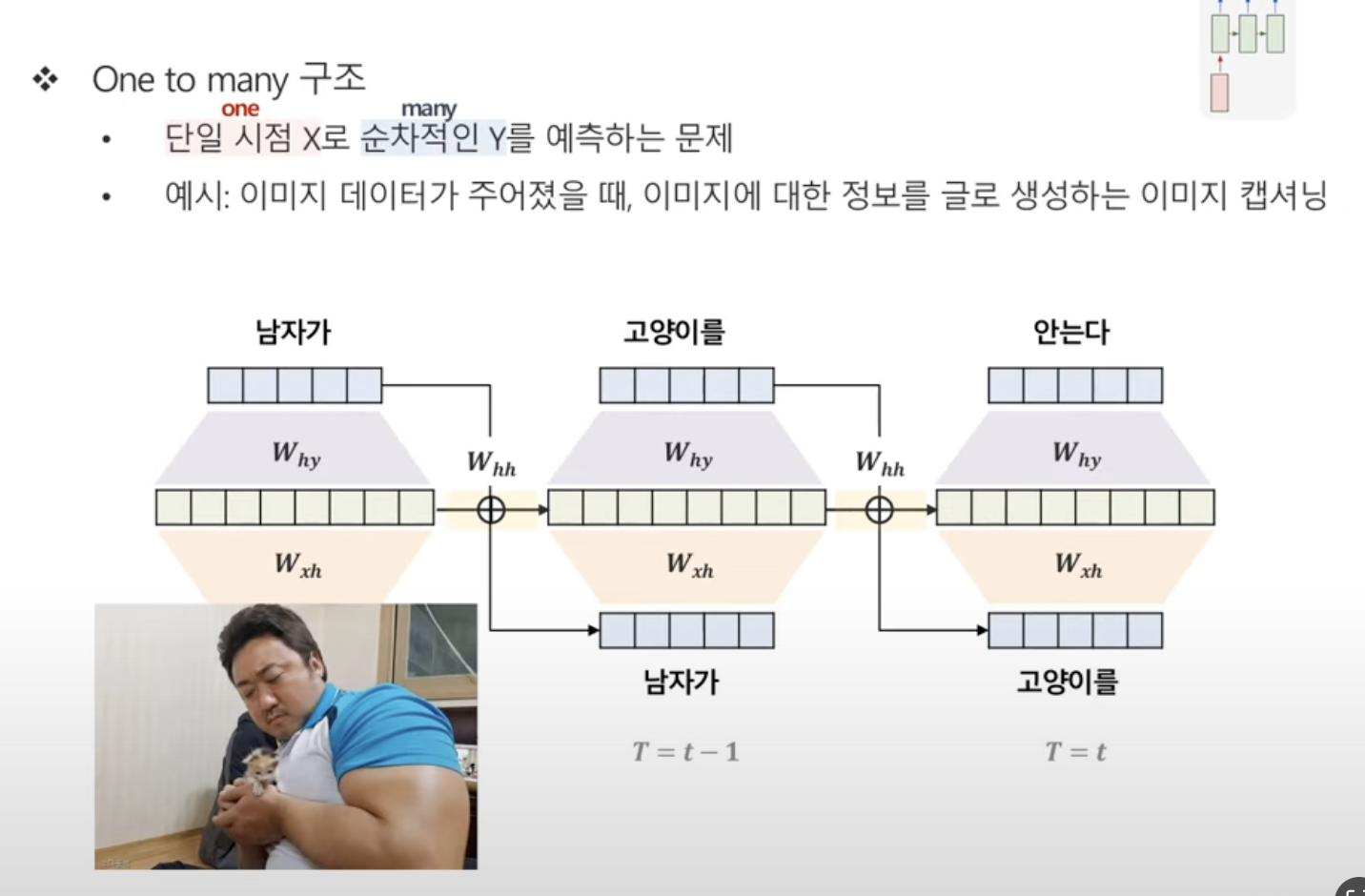
단일 시점 X로 순차적인 Y를 예측하는 문제이다.
현시점의 X(이전시점의 y)와 가중치를 곱한 것 + 이전 시점의 hidden state를 곱한 것
- 특이점은, 매 시점마다 X가 없는 것이 아니라, 이전 시점의 결과값을 활용한다는 것!!
Many to Many 구조
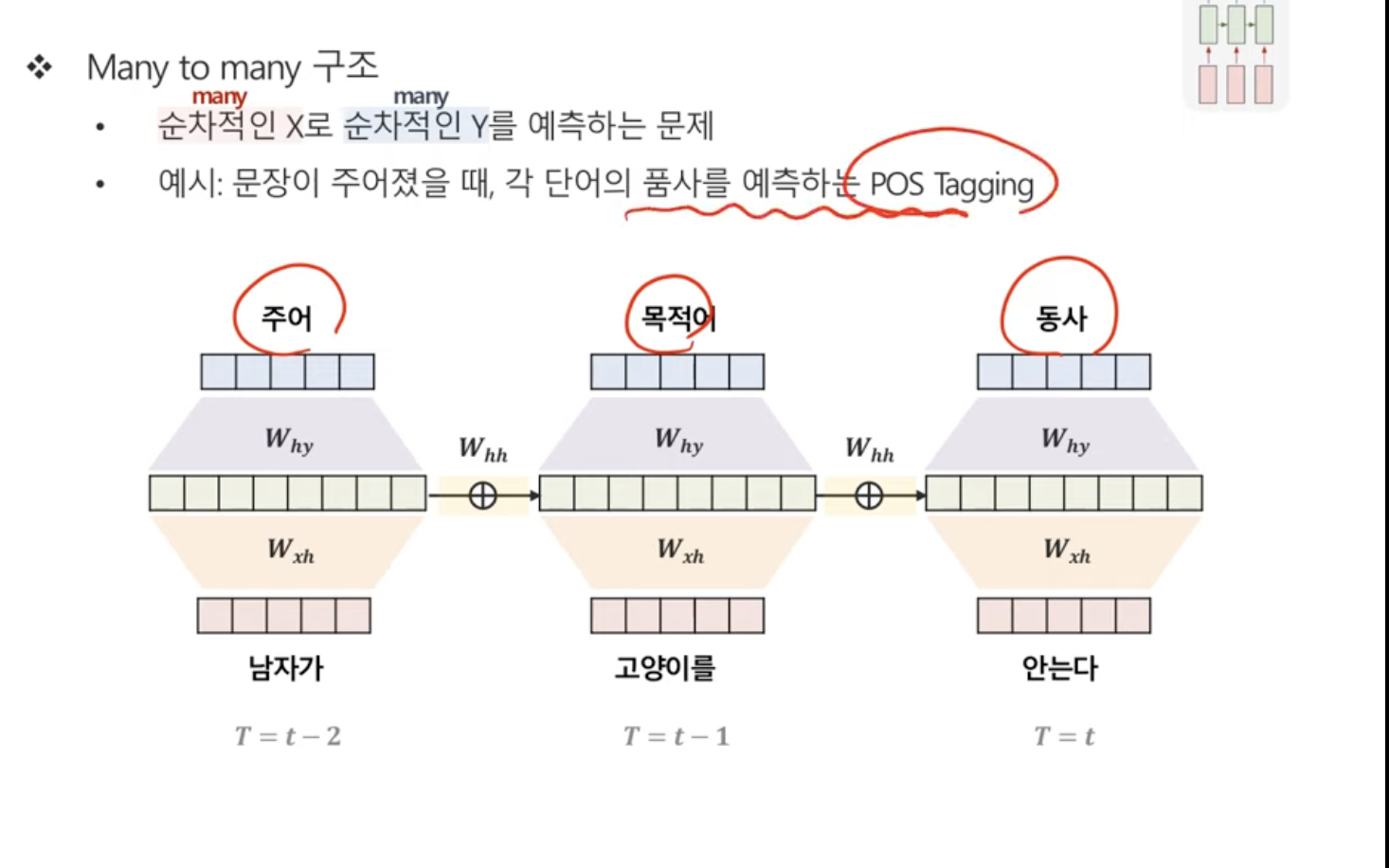
Many to One과 동일.예시로는 POS tagging이 있다.
Many to Many 구조(Many to One + One to Many)
위의 Many to Many와 다른 점은, 일대일 대응형식으로 값이 나오는 것이 아니라, 입력 X를 다 받아들인다음에 y를 생성한다.
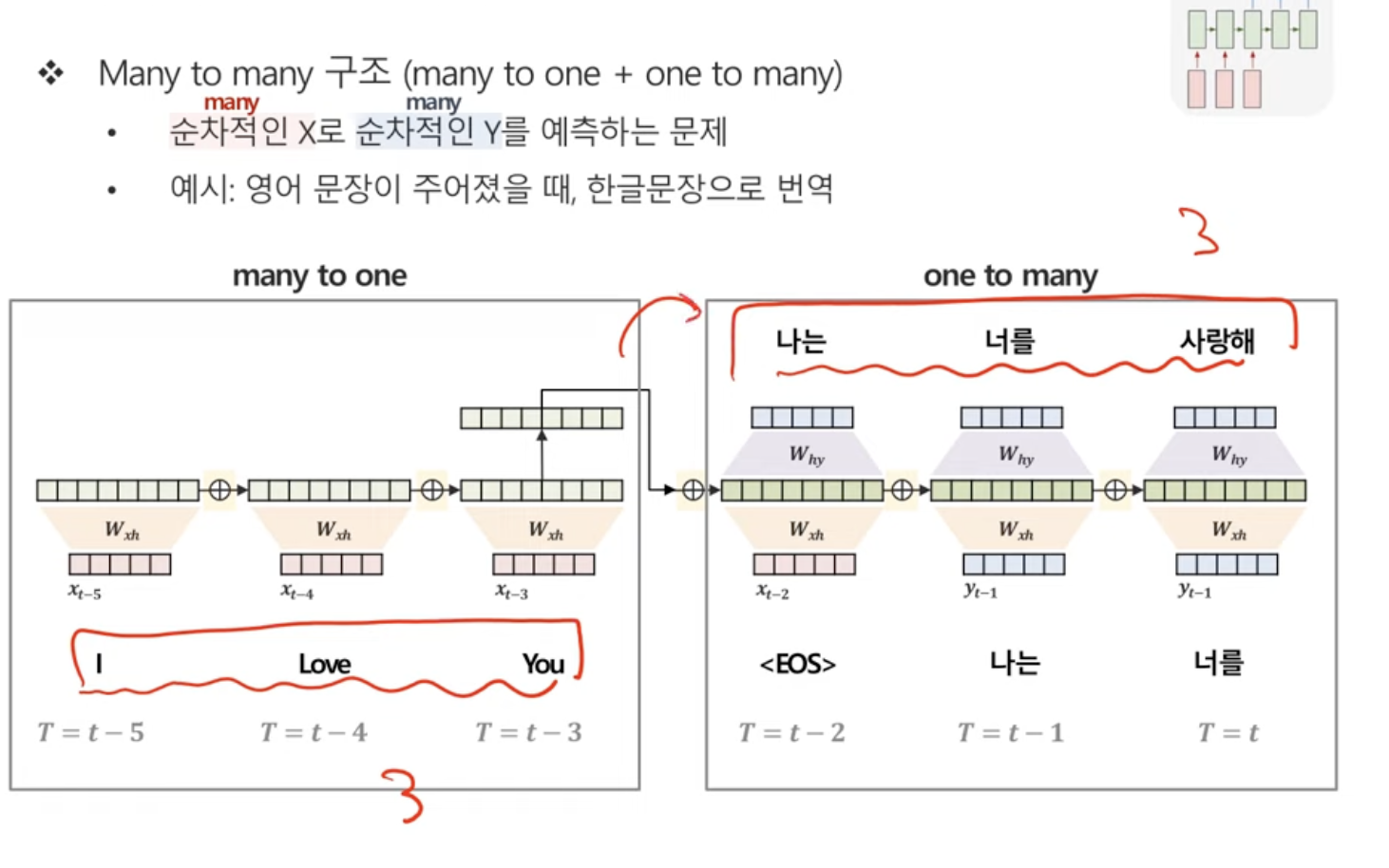
이러한 Many to Many의 구조를 Seqence to Sequence라고 한다! 그 유명한 Seq2Seq!!
이때 앞부분을 Encoder라고 하고, 뒷부분을 Decoder라고 한다. Attention에서 그 유명한ㅎㅎ
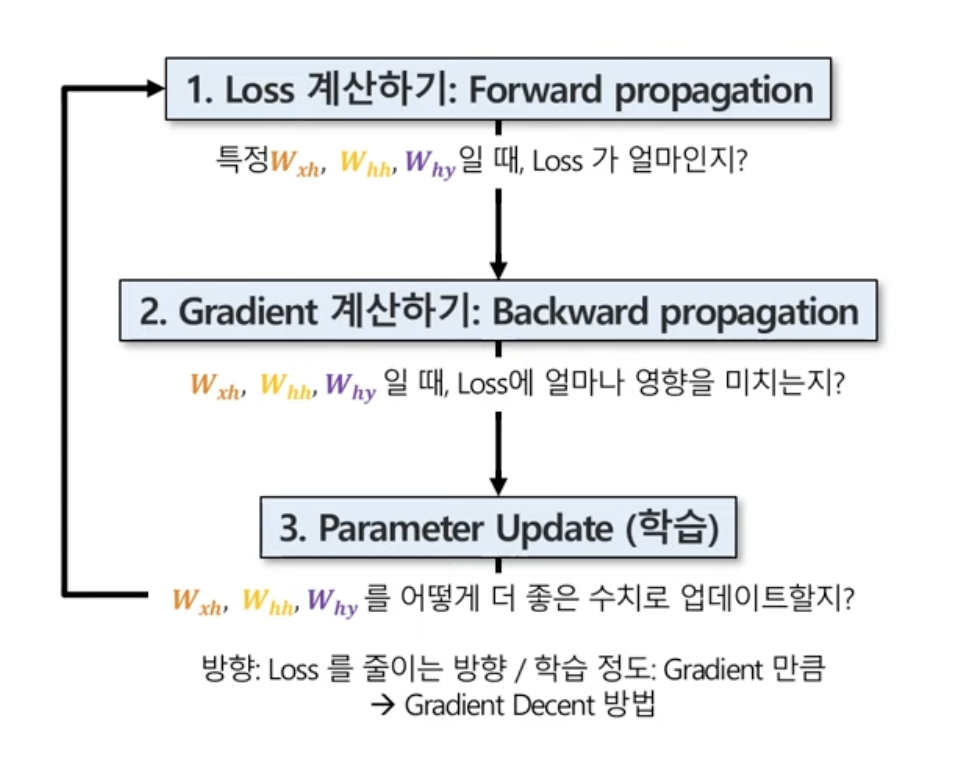
파라미터들을 어떻게 학습시키지?
전제 : 해당 파라미터들은 매 시점마다 공유하는 구조. 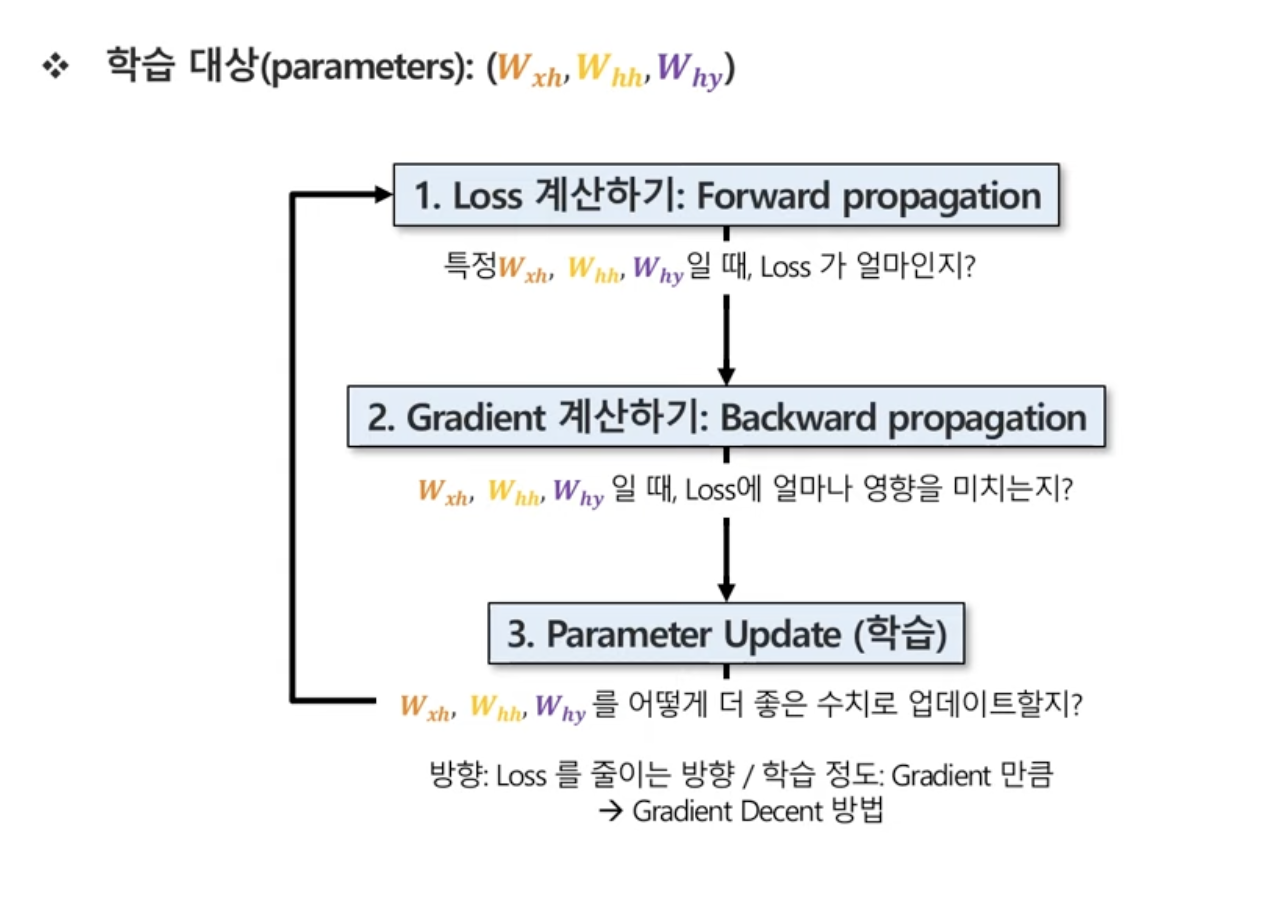
1. Loss 계산하기 : Forward Propagation
Loss = t에서의 실제 y값 - t에서의 예측된 y값
만약 , Many to One이라면?
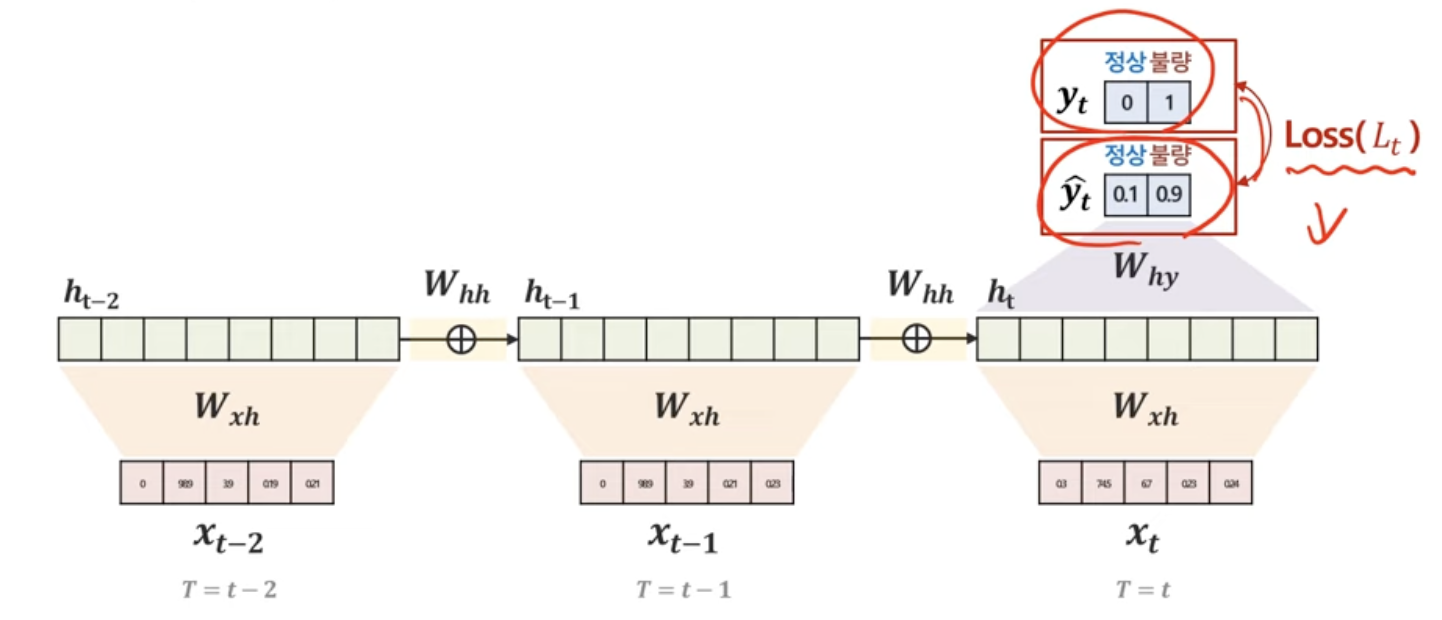
만약, Many to Many라면?
Average of loss로!
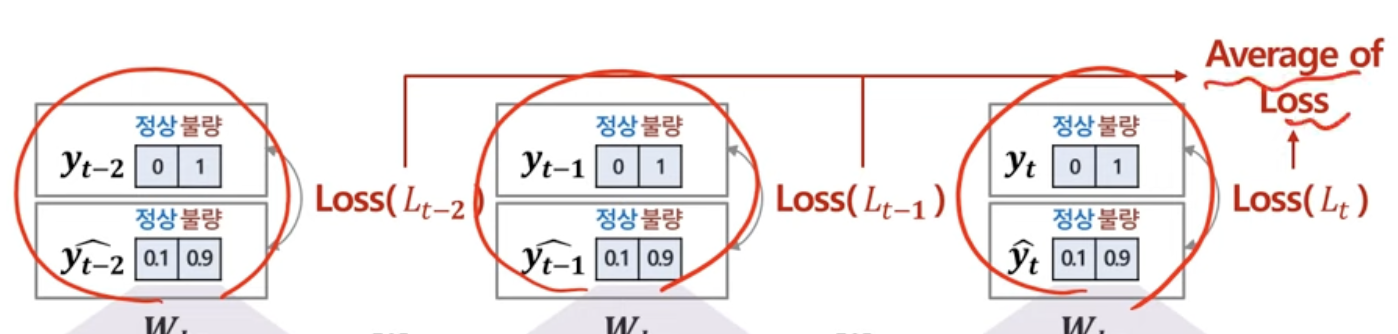
2. gradient 계산하기 : Backward Propagation
경사하강법을 이용하되, chain rule을 활용해서 쉽게!
- h에서 y로의 gradient
- h에서 h로의 gradient
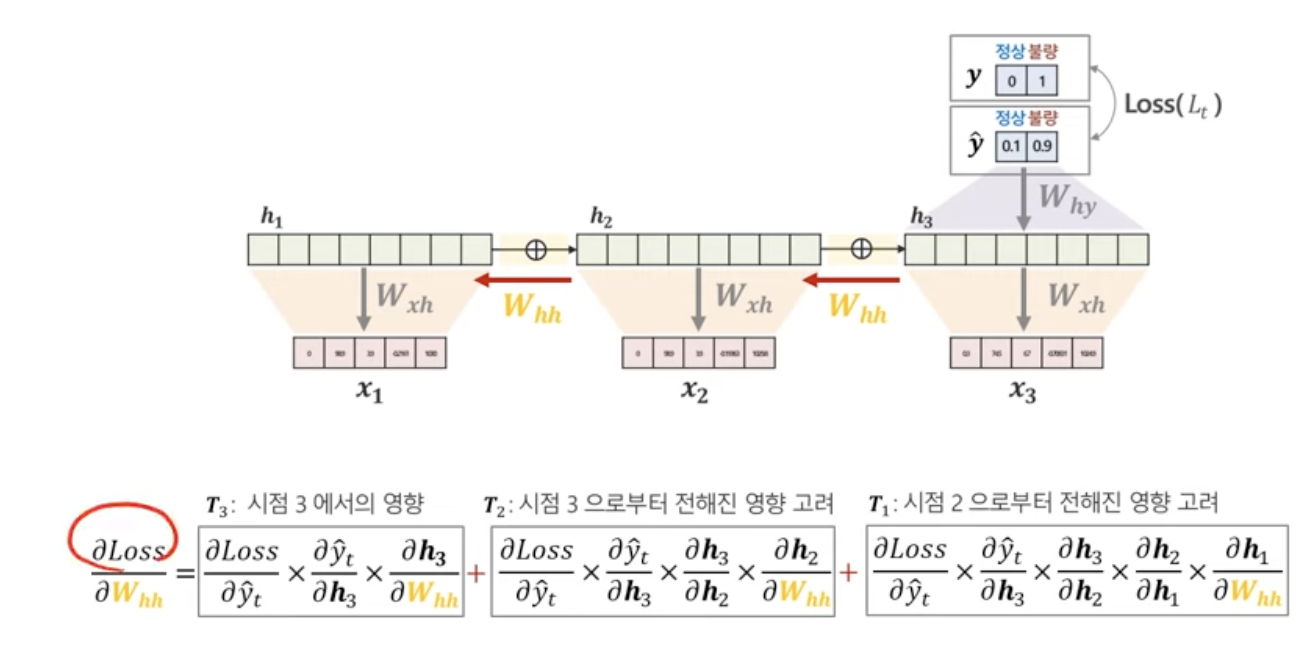
h에서 y로의 gradient와는 다르게 매 시점마다! 고려를 해야한다는 것이 특징. 당연히 한번만 적용된 게 아니니까
3번째 시점에서도 h에서 h로의 graident가 쓰였고,(첫번째 식)
2번째 시점에서도 h에서 h로의 graident가 쓰였고,(두번째 식)
1번째 시점에서도 h에서 h로의 graident가 쓰였다!!(세번째 식)
- x에서 h로의 gradient
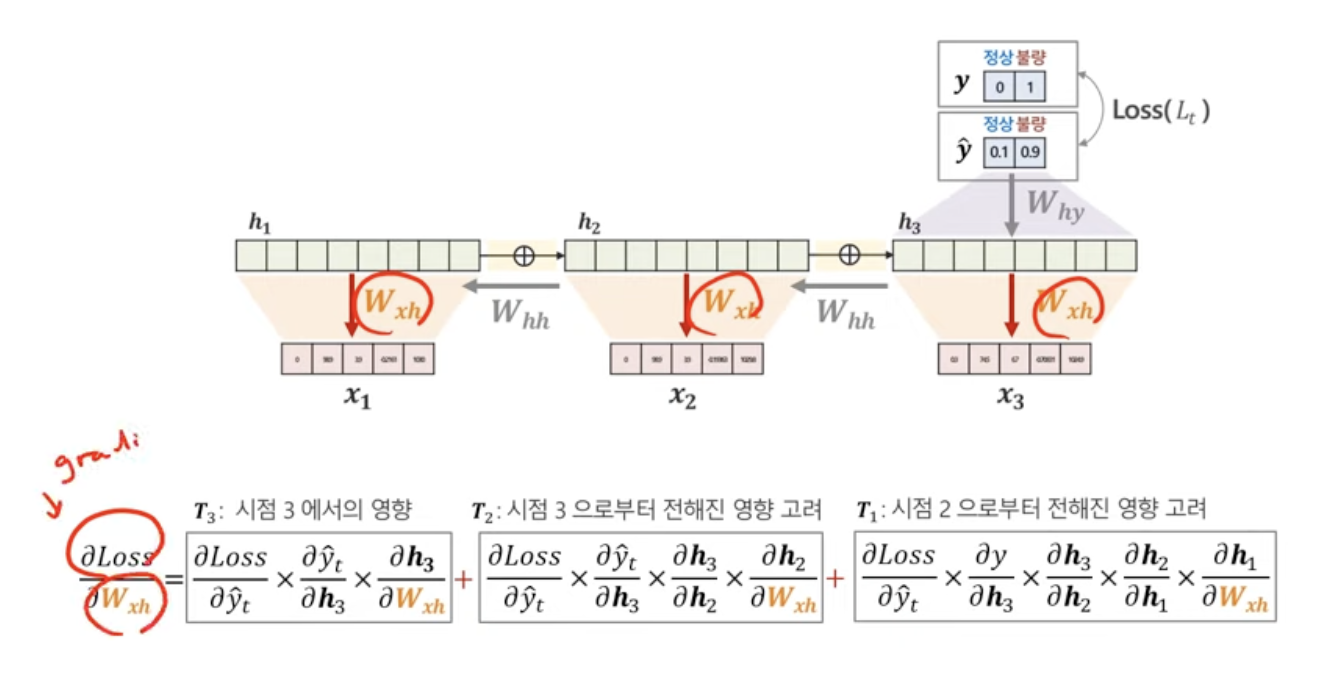
h에서 y로의 gradient와는 다르게 매 시점마다! 고려를 해야한다는 것이 특징. 당연히 한번만 적용된 게 아니니까!
3번째 시점에서도 x에서 h로의 gradient가 쓰였고,(첫번째 식)
2번째 시점에서도 x에서 h로의 gradient가 쓰였고,(두번째 식)
1번째 시점에서도 x에서 h로의 gradient가 쓰였고,(세번째 식)
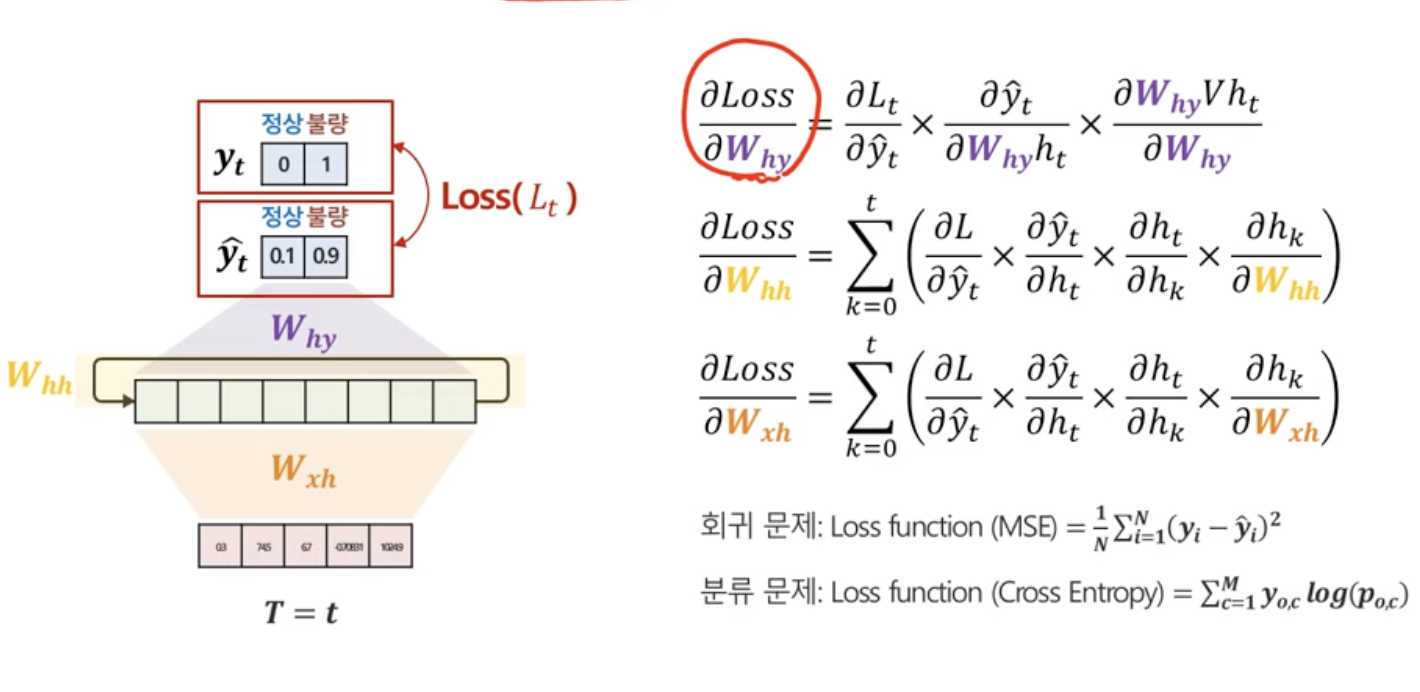
종합해서 보자면, 각시점마다 계산해주는 Whh와 Wxh는 시그마로 표현되는 걸 알 수 있다.
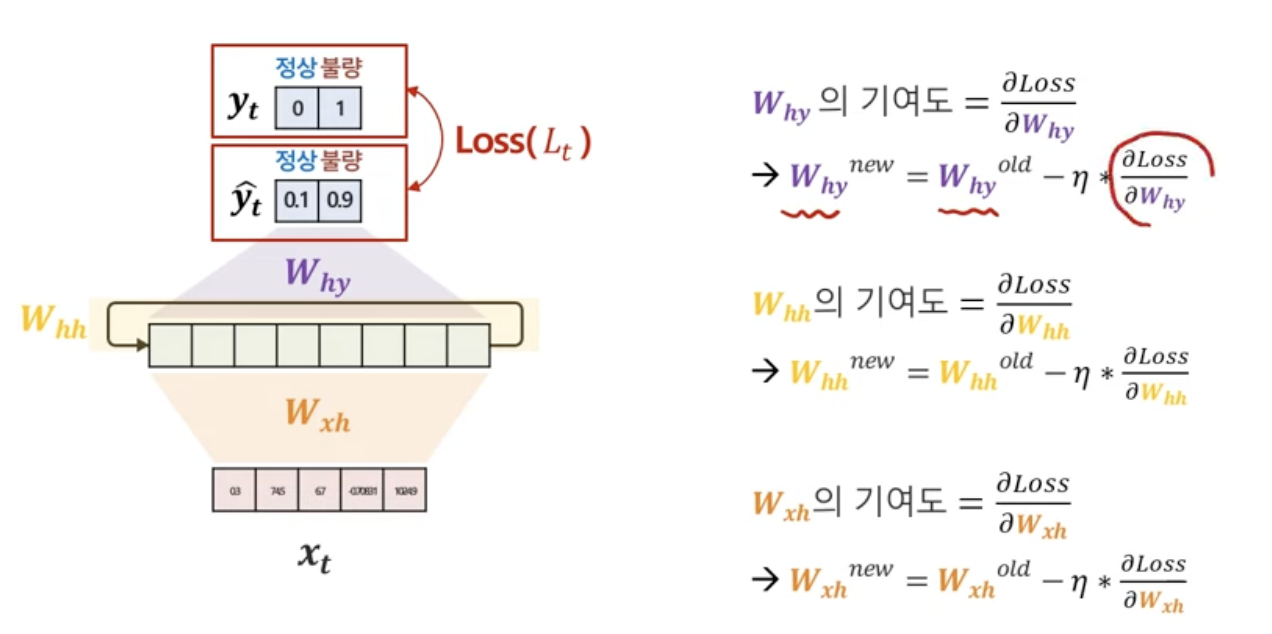
3. Parameter Update
그냥 신경망에서 gradient update하는 방법과 똑.같.다
RNN의 한계점
장기 의존성 문제.
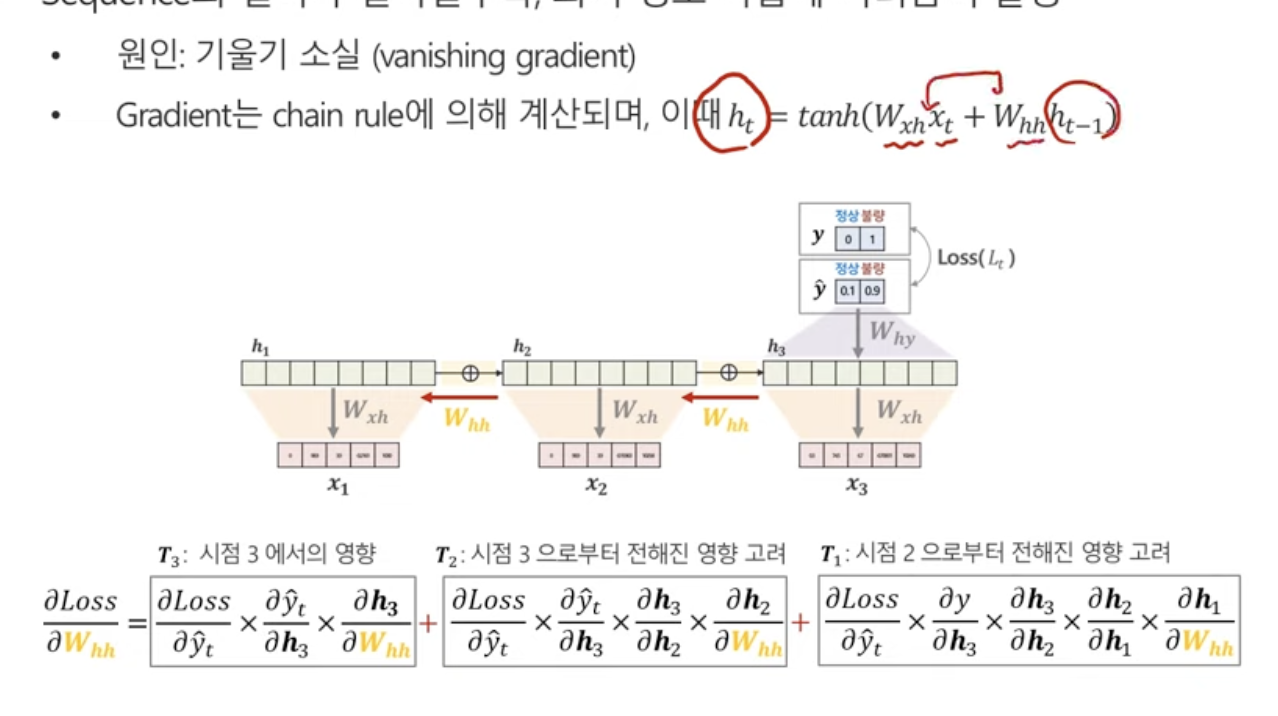
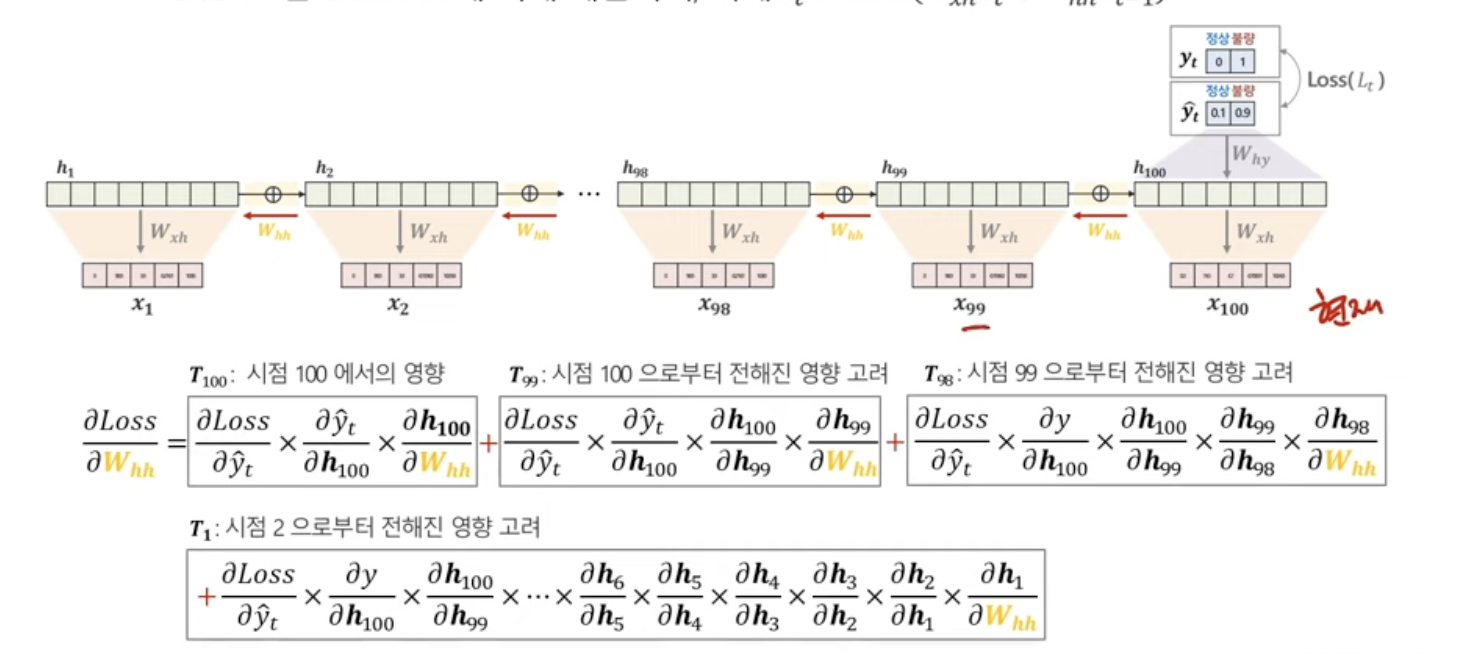
시점1로부터 전해진 영향을 고려해봤을 때,,,시점1로부터의 영향은 곱하기가 일단 많다...
곱하기가 많은 게 그럼 도대체 어떤 문제인건데? 뭐가 문제인건데?
Vanishing Gradient
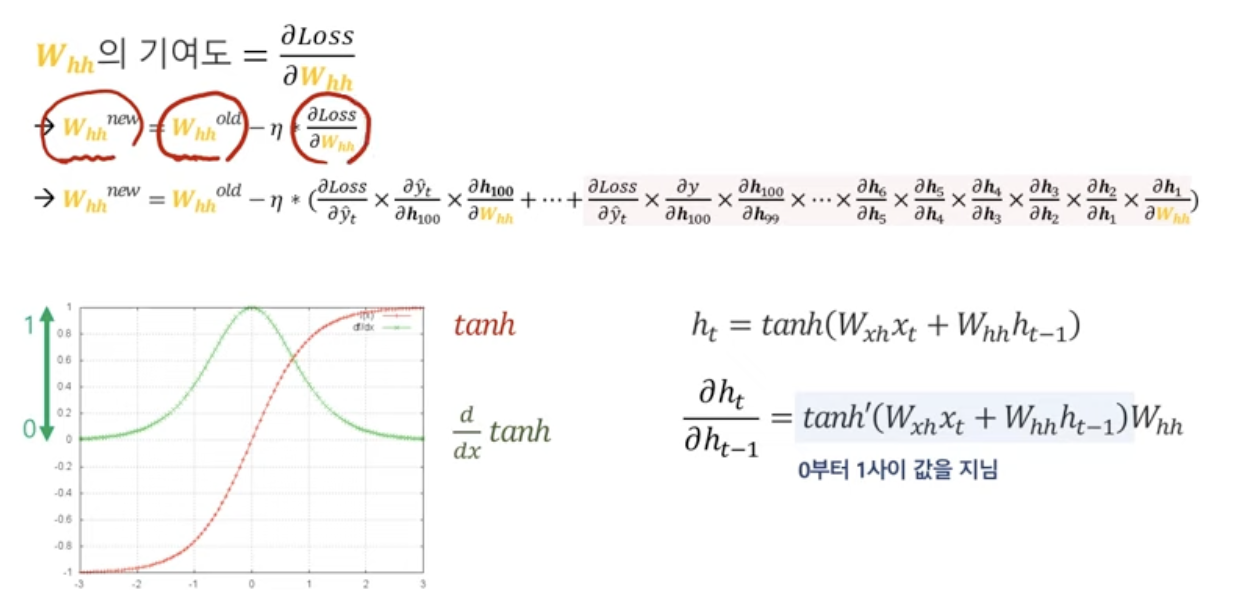
- gradient 계산 과정
일단, chain rule에 의해서 t시점에서의 hidden state를 t-1시점의 hidden state로 미분한다. 그럼 이 미분값은 하이퍼볼릭탄젠트를 미분한 것이니까... 0에서 1사이의 값을 지닌다...ㅎㅎ
tanh의 미분값은 0~1사이다.
그렇다면, 0.4x0.1x0.12x... = 거의 0...?
그니까, 가까운 시점의 gradient는 계산이 되는데 먼 시점의 gradient는 계산이 안되는 거다...
- parameter update 과정
당연히, 기존의 파라미터 - learning rate x gradient 인데,
그럼 이전의 정보를 반영하지 않은 채로 그냥 최근의 시점의 정보만 반영해서 update되는 불상사가 발생할 것 아닌가...!
이렇게 되면 뭐 RNN의 의미가 있나...!!! accuracy도 낮을테고...
그래서 등장한 것이 바로바로 LSTM!!
LSTM
RNN을 회로도로 표현하기
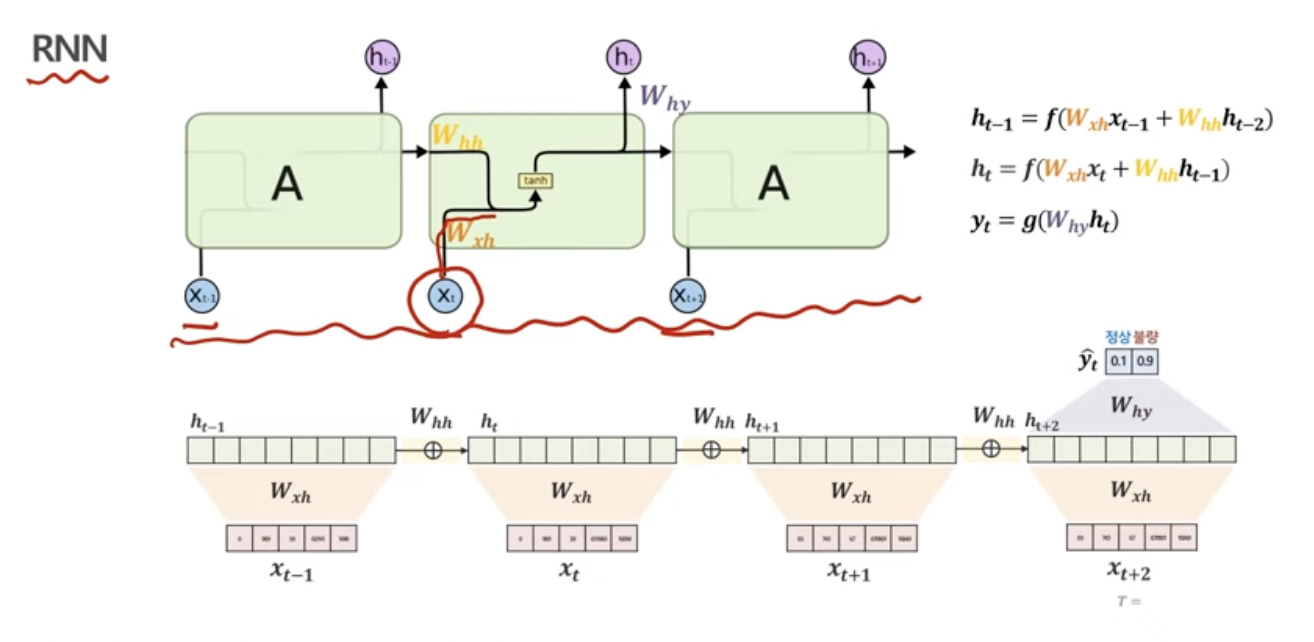
LSTM을 회로도로 표현하기
여기서는, Gate들이 등장하는데, 이건 기존 RNN에는 없는 개념들이다!
근데, hidden state에서 hidden vector가 등장했던 것처럼 똑같이 vector의 일종이라고 보면 된다!
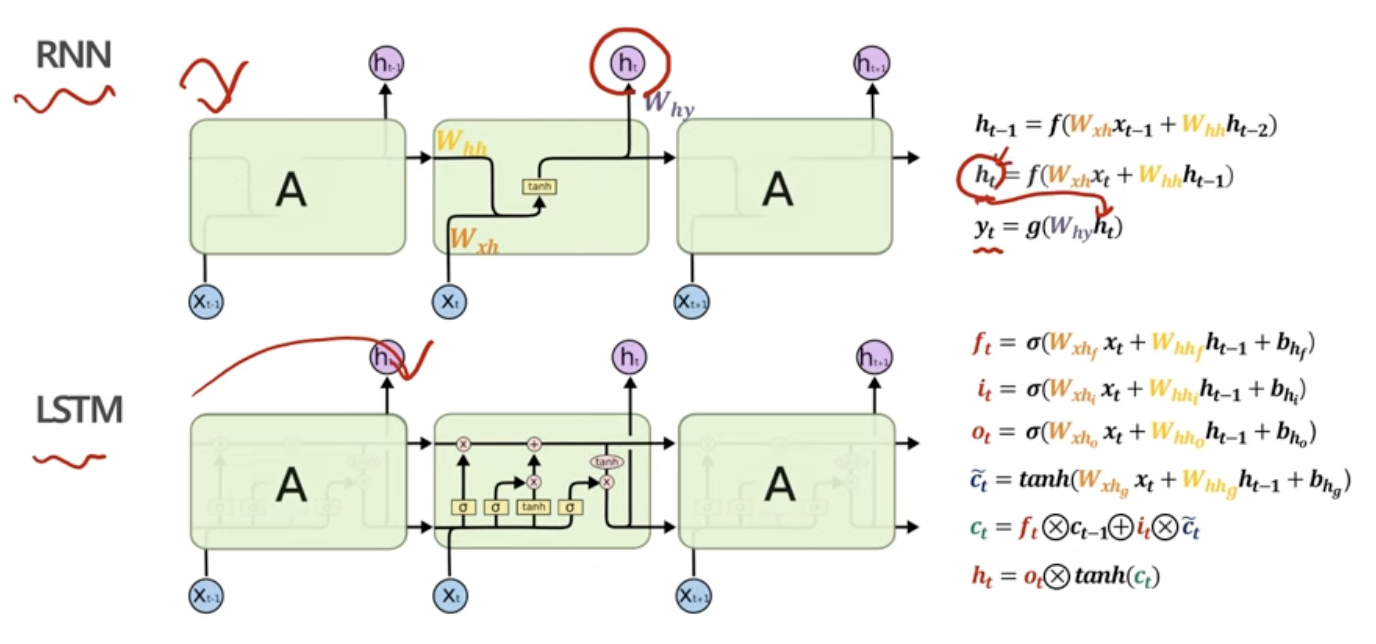
아까 RNN에서 문제가 되었던 지점이 바로 무엇인가? 바로 hidden vector였다.
gradient계산을 위해 chain rule을 적용하는 과정에서 ht를 ht-1로 미분했을 때 tanh'값이 나와서 계속 0.xxx가 곱해지는 게 문제였다.

그래서 그 문제를 해결하기 위해서,
1. hidden vector를 복잡하게 구한다.(by forget,input,output gate)
그러면 일반적인 rnn이 가지고 있었던 vanishing gradient 문제를 해결할 수 있을듯하다!!!
2. 장기적인 정보들을 유지할 수 있도록 Cell state를 이용한다!
LSTM의 구조
알아두어야할 점은, 궁극적으로 원하는 것은 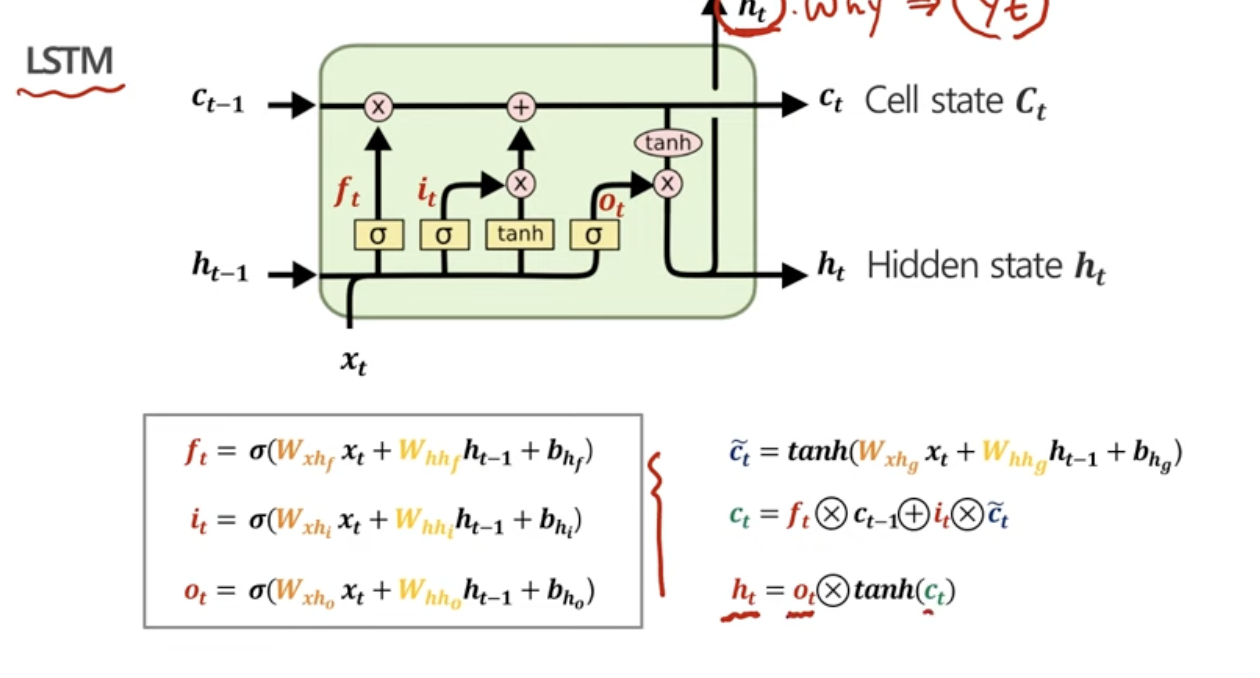
t시점의 hidden vector를 구하는 것!!!
1. hidden state
t시점의 cell state에 tanh x t시점에서의 output gate
즉, output gate는 수도꼭지같은 느낌! 얼마나 cell state를 반영할건데?
2. cell state
t-1시점에서의 cell state x t시점에서의 forget gate + t시점에서의 input gate x t시점에서의 임시 cell state
즉, forget gate와 input gate도 수도꼭지같은 느낌! 이전의 cell state를 얼마나 잊을건데? 지금의 cell state를 얼마나 반영할건데?
3. 임시 cell state
t시점에서의 입력 x 가중치 + t-1시점에서의 hidden state x 가중치
에다가 tanh
4. forget,input,output gate
얘네는 결국, cell state를 조절해주는 수도꼭지 같은 느낌이다!!!!
그럼 그 수도꼭지가 어떻게 구해지냐면,
t시점에서의 입력 x 가중치 + t-1시점에서의 hidden state x 가중치
에다가 시그모이드!
왜...어쩔때는 tanh고 어쩔때는 시그모이드...?
왜 f,i,o gate에서는 시그모이드? 값이 0에서 1사이. 그래서 수도꼭지처럼 비율을 조절할 수 있어서 그런 게 아닐까?!
왜 임시 cell state에서 tanh? 1) 조금더 표현을 다양하게 할 수 있음. 2) 임시 cell state에서는 가중치가 '학습'이 되기 때문에 임시 cell state가 엄청나게 커질 위험을 방지하기 위해 tanh를 넣는다. 3) 비선형성이 필요!!!
LSTM 과정
조금 더 자세하게 설명해보면,
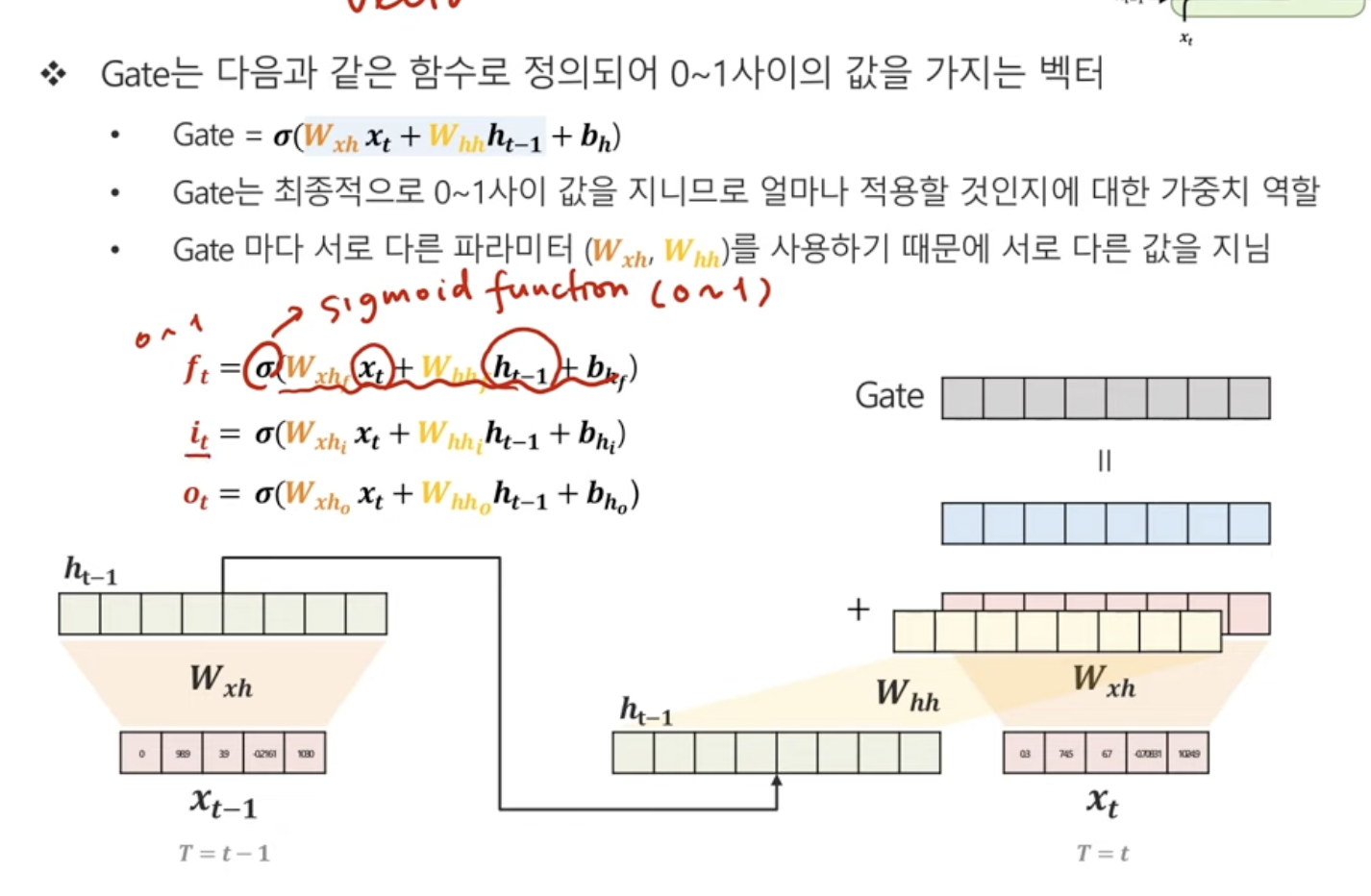
1. forget,output,input gate 구하기
현재시점의 관측지 x 가중치 + 이전시점의 hidden state x 가중치
에다가 시그모이드!
=> 확률값이니까.
얘도 또다른 가중치라고 할 수 있음.
2. cell state 업데이트 하기
2.1 임시 Cell State
현재 시점의 관측치 x 가중치 + 이전시점의 hidden state x 가중치
에다가 tanh
2.2 Cell State
이전 시점의 Cell Stae x forget gate + 임시 Cell state x input gate
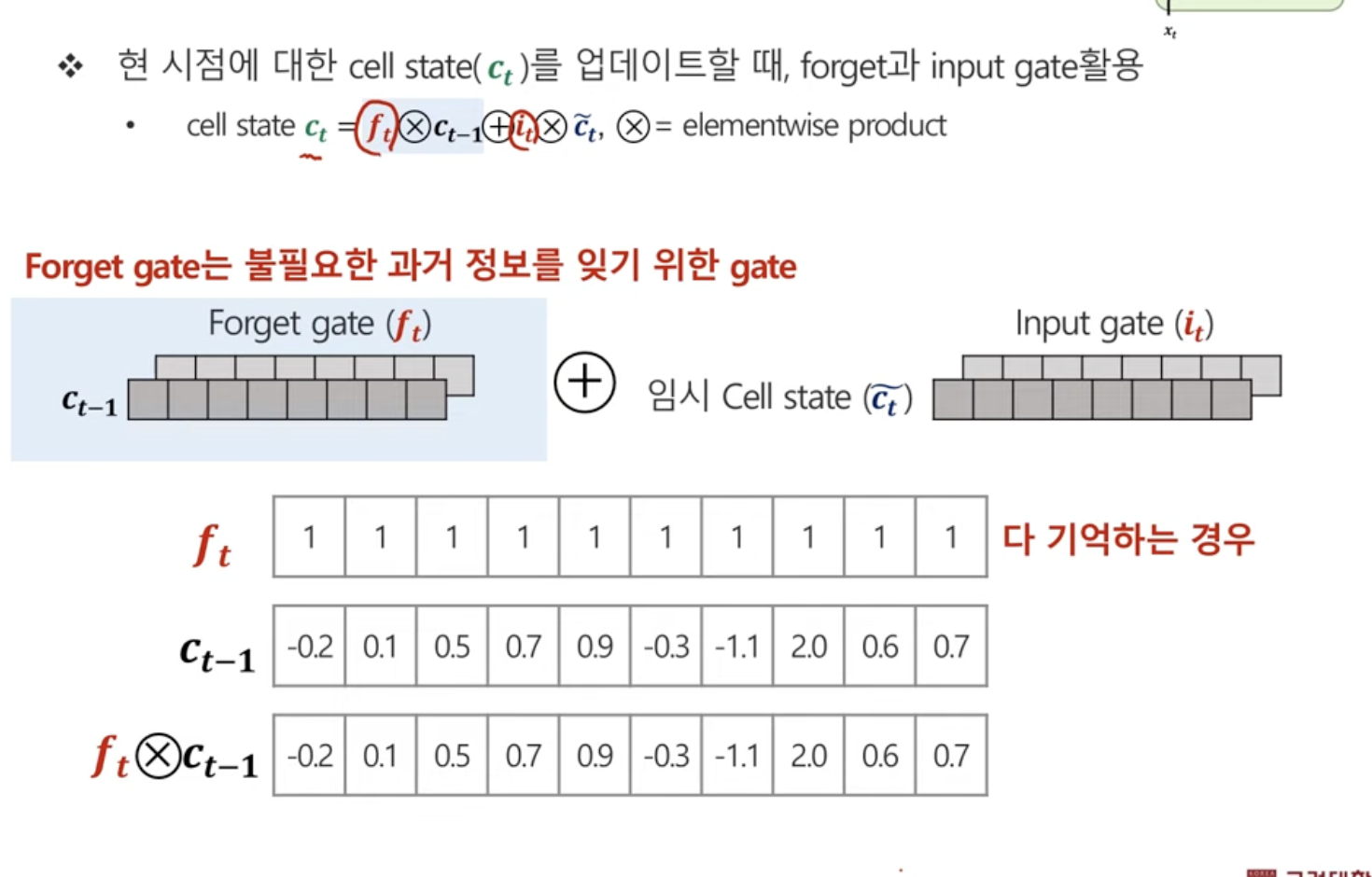
이전시점의 정보를 얼마나! 잊을 것인가 이거를 forget gate가 조절하는 것.
forget gate가 1이면 온전히 다 살아남음.
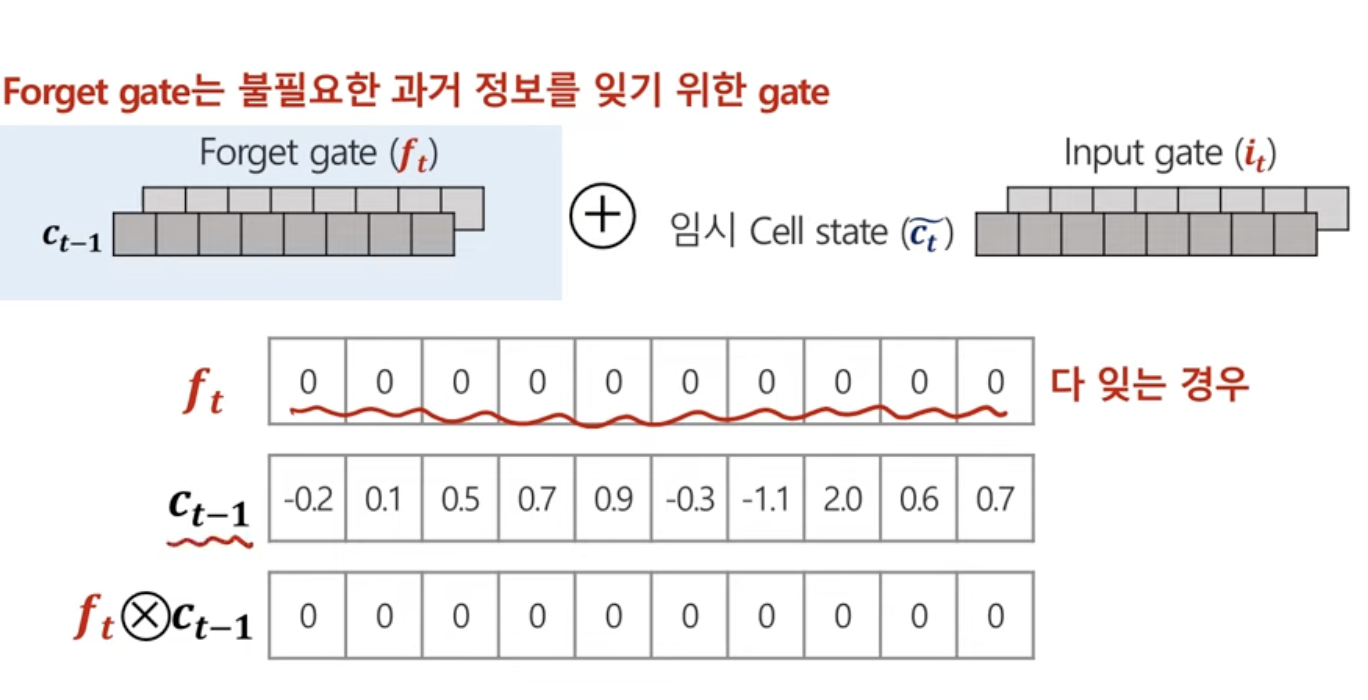
forget gate가 0이면 온전히 다 살아남지 않음.
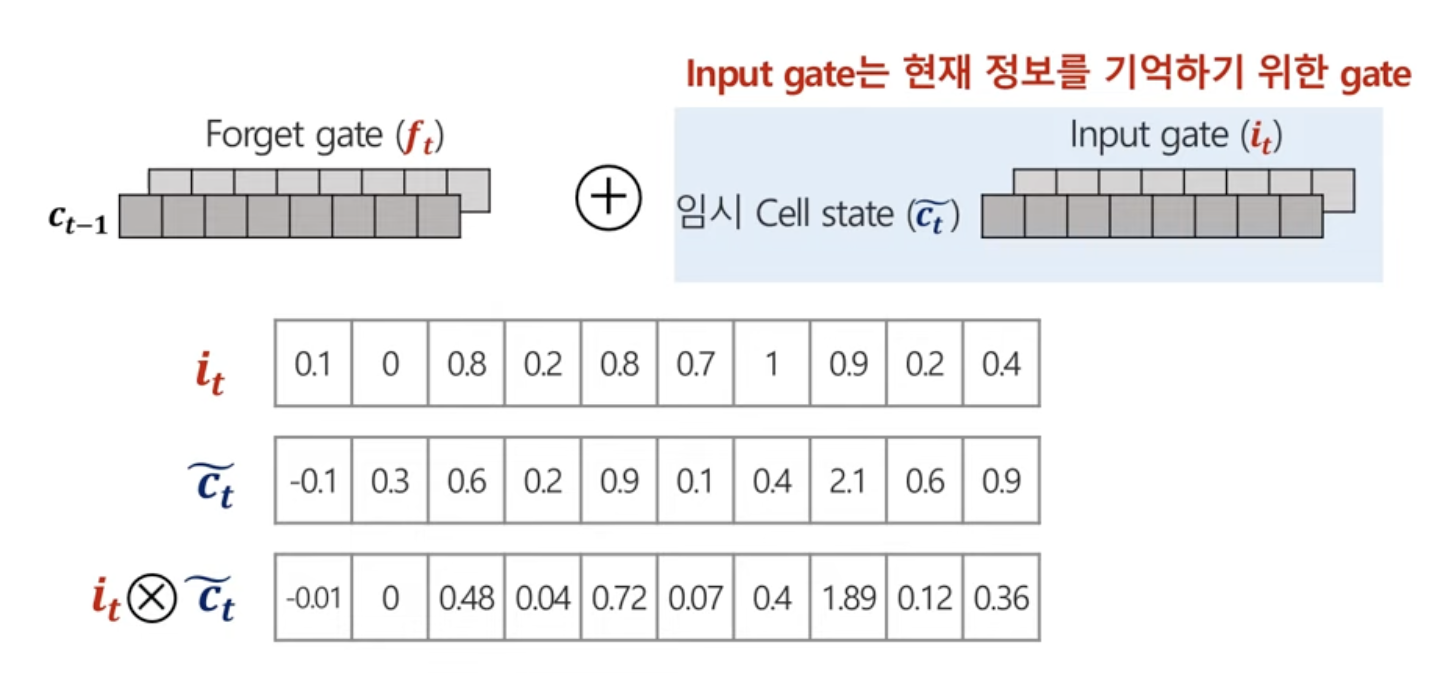
input gate는 현재시점의 정보를 얼마나! 기억할 것인가!
3. hidden state 업데이트 하기
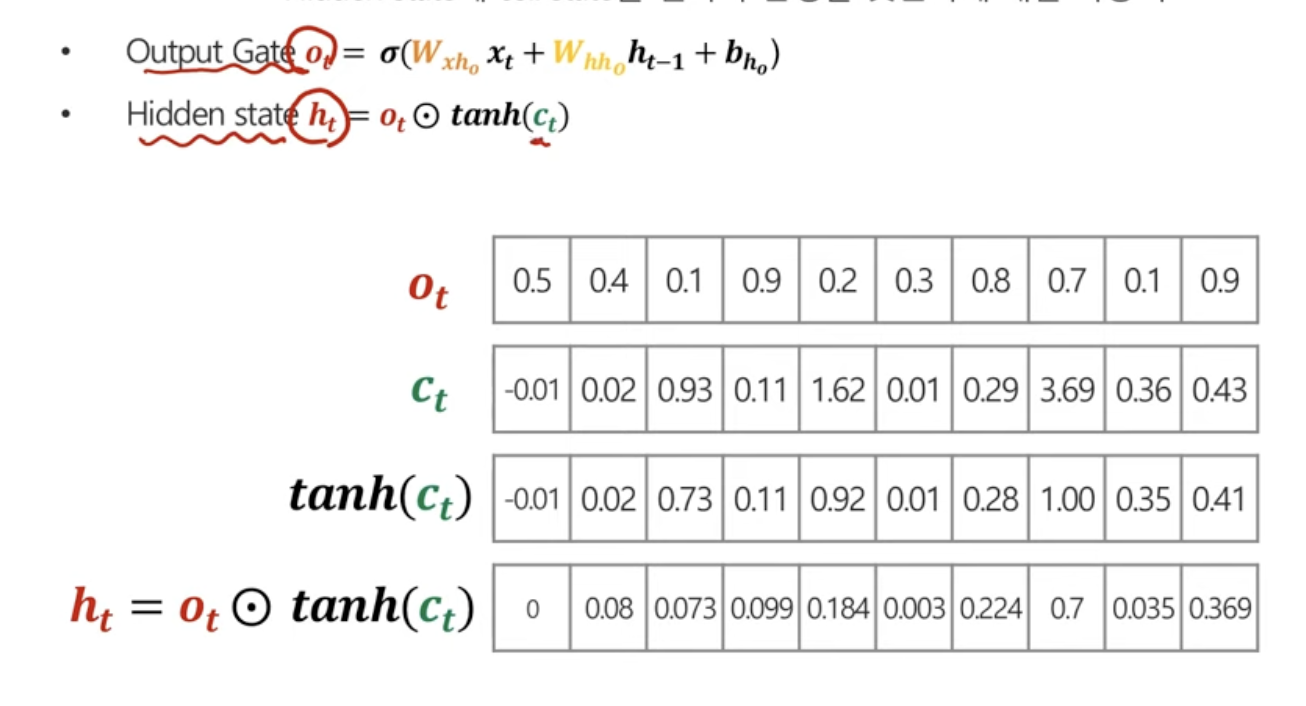
t시점에서의 cell state를 얼마나 반영할 것인가!!
4. 예측값 구하기
hidden state x 가중치
LSTM에서의 gradient update
이건 강의 영상에 없는데 개인적으로 gradient 수식이 무엇인지 궁금해서 찾아봤다.

일단, 이것이 끝이고 transformer는 내일... 내일 아침에...
올려야지...
출처 :
김성범 교수님의 RNN,LSTM,GRU강의
이 링크 클릭하면 설명을 들을 수 있다!
