Transformer의 경우, 예전에 혁펜하임 강의를 구매해서 들었는데...
지금은 시간이 없는 관계로 !! 압축된 강의를...ㅎㅎ 듣고자 한다. 뒤에 혁펜하임 자료본 참고해서 적은 내용도 추가했따!
Preparation
Weight 통과
쉽게 말하면 특정 벡터에 가중치를 곱하는 것이라고 할 수 있다.
linear combination!
Weighted Sum

info1,info2,info3의 가중합은 저 회색이다.
여기서, 제약조건(constraint)가 있는데, 가중치의 합은 1이라는 것이다. Convex Combination에서도 가중치의 합이 1인 것처럼!!
만약 info1의 정보를 많이 담고 싶다면, info1에 해당하는 가중치를 1과 가깝게 설정하면 된다. info2의 정보를 많이 담고 싶다면, info2에 해당하는 가중치를 1과 가깝게 설정하면 된다.
inner Product
내적의 원리 : 같은 차원 숫자끼리 곱하고 더함.
내적의 특징 : Cosine Similarity에 의해 내적했을 때 유사하면 내적의 값이 크고 덜 유사하면 값이 작다.
왜 유사하면 내적의 값이 크고 덜 유사하면 값이 작냐면,,,
하 학교 수업에서 배웠는데 기억이 안ㄴ나네.

답은 이거ㅎㅎ
내적을 norm으로 나눈 게 cosine similairy! 즉, 방향을 나타내는 것이라고 할 수 있다.
Attention
위의 기본 3가지 성질을 가지고 Attention을 설명할 수 있다고 한다.
준비물
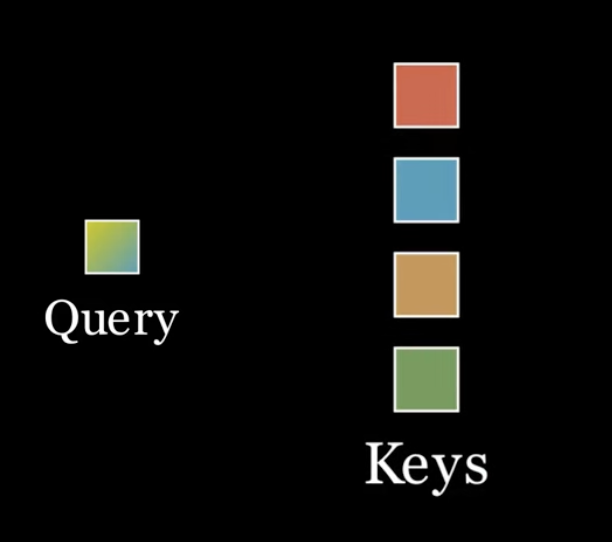
1. Query Tensor
2. Key Tensors (텐서들!)
과정
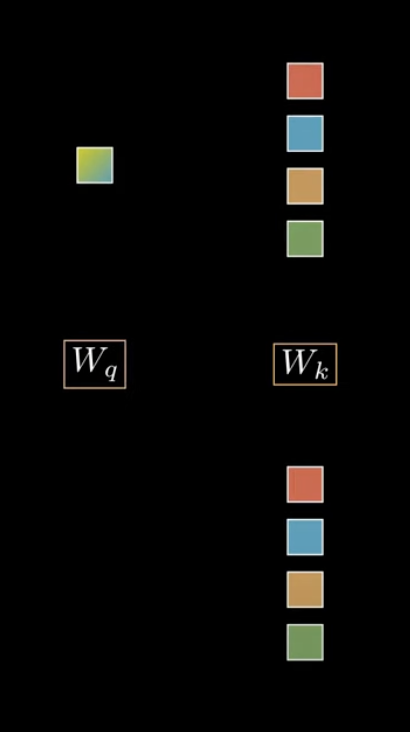
1. Weight를 통과시키기(Linear Combination)
1-1 ) Query Tensor x 가중치 = Query
1-2 ) Key Tensors x 가중치 = Key
1-3 ) Key Tensors x 가중치 = Value
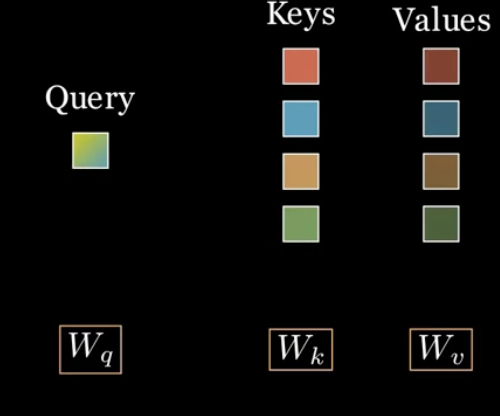
2. 내적
1-1과 1-2를 각각 내적

그림에서는 4개의 내적값이 나옴!
맨 위의 키는 1.7만큼 비슷,-1.3만큼 비슷,3.9만큼 비슷,마지막은 0.3만큼 비슷
3. Weighted Sum을 위한 준비
의문점...
1) 왜 Weighted Sum?
Weight가 큰 정보를 많이 갖는다. Query랑 유사한 정도를 가지고 Value의 정보들을 담겠다!!
2) 내적이 음수일지도...?
내적의 합이 1인 것도 아니고, 양수인 것도 아님.
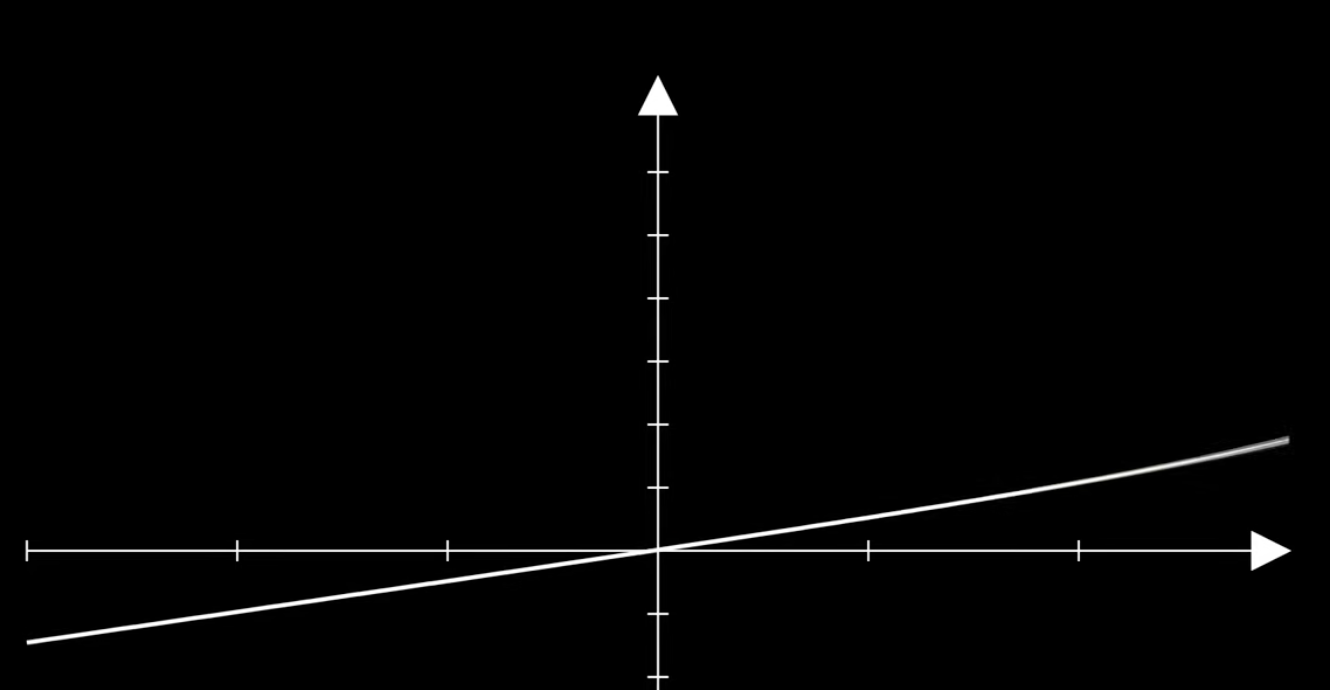
이렇게 성질을 만족하는 것을 exponential!
3) 합을 1로 만드는 방법은?


분모에는 가중치의 합을 , 그리고 분자에는 그 가중치를!
4. Weighted Sum
그렇다면, Weighted Sum의 결과는 쿼리의 정보일까? 아니면 Key들의 정보일까?

이렇게 되었다고 가정하면,


Weighted Sum의 결과의 정보공간은 한국어 정보 공간!
즉, 결과의 정보는 Value들의 가중치 합!
여기서 잠깐,,, Value들은?
Key들에서 가중치를 곱해서 나온 것! 과정1에 있음
결국, 정리하자면 Attention은 Key 정보의 가중치 합!
질문
왜 쿼리라는 단어를 붙였을까?
쿼리 = 정보를 요청한다.
ex) 구글
쿼리 = 검색어
검색엔진에선, 쿼리와 제일 관련 있는 블로그 글이나 이미지 같은 것들을 추천해준다.
그래서, 결국 검색어(쿼리)가 주어졌을 때 Key정보들 중에서 관련된 것을 찾아서 weight를 구한 다음 그 value들을 결과로 보여줌.
동음이의어에서는...?
인도 카레 전문점
인도 주행 금지
우리는 이게 의미가 다르다는 것을 알고 있음.
Attention계산만으로는 둘이 다른 정보라는 것을 구별할 수가 없음.
불가능하다.
Attention에 순서/맥락 반영하기
문제
쿼리를 입력했을 때, 쿼리랑 관련 있는 키 정보들의 가중치 합.
이때 키 정보들을 각각 개별적으로 내적계산
=> 순서를 고려하지 못함...



'인도'라는 키랑 내적을 첫번째에 하든, '인도'라는 키랑 내적을 4번째에 하든 내적 결과는 동일!

그래서 첫번째가 인도다 이런 순서는 무시됨.
구체적으로 얘기해보자면.
첫번째:
1.Scalar랑 Key1를 inner product함.
2.Value1이랑 1번을 weighted Sum함
두번째:
1.Scalar랑 Key2를 inner product함
2.Value2랑 1번을 Weighted Sum함
=> 키의 순서가 바뀌어도, 애초에 Value가 Key로부터 나오는 것이기 때문에! 첫번째 = 두번째 가 되는 것임.
해결책 - Positional Encoding
특정 위치마다 특정 벡터를 더한다! 
이렇게 되면 순서 정보를 주입할 수 있다!!!
문제
하지만, 또다른 문제가 등장한다.
바로바로...
순서 정보를 주입했다고 해도
과연 똑같은 의미일까? 
이 둘은 다른 의미다. 똑같이 첫번째 단어이긴 해도!! 둘의 의미는 엄연히 다르다.
해결책 - Self Attention

Query도, Key들도,Value들도 다 똑같은 문장!을 쓴다. 
6개의 쿼리들을 각각 Key들에 내적을 취한다. 
그러면 인도라는 한 단어의 정보가 아니라, 다른 단어들과의 관련도가 반영된 "인도"정보에 대한 가중치 합!인 것이다. 
Attention과 Transformer
Transformer 학습
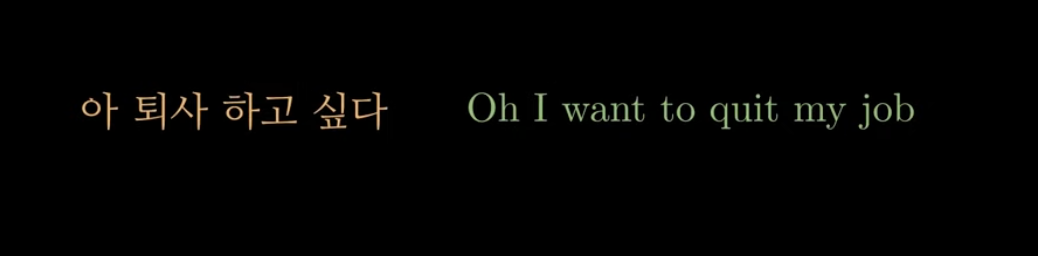
번역을 하기 전에는, 번역된 영어 문장이 뭔지는 모른다.
일단 한글로 주어진 문장은 다 알고 있는 것임.
그러면 어떤 순서로 예측하는 게 쉬울까?
일단, 첫번째 단어로 Oh라고 예측하면, 그 다음 영어 단어는 주어가 있어야 할 것이니까 I...
그니까 첫번째 단어부터 차근차근 예측하는 것이 쉬움!!!
Encoder
번역 당할 문장은 Encoder에!
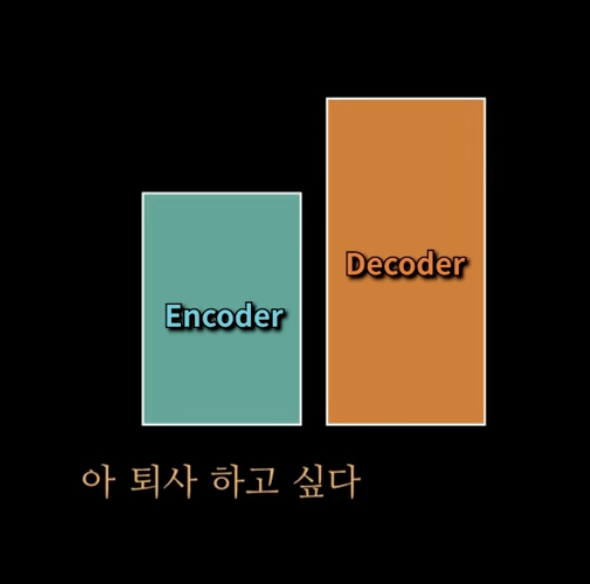
Decoder
하나씩 하나씩 디코더에 넣어요!!
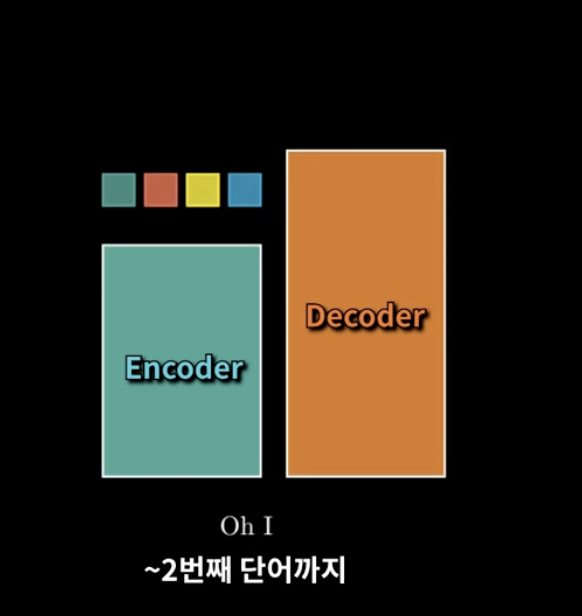
3번째 단어단어를 예측한다고 하면,
Decoder에 첫번째 영어단어 그리고 두번째 영어단어를 입력으로 넣는다.
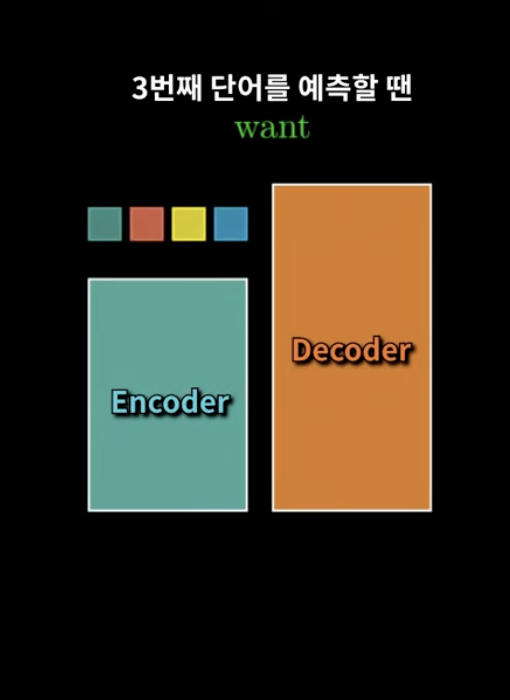
첫단어를 예측할 때는, 
SOS 토큰!
마지막을 예측할 때는,
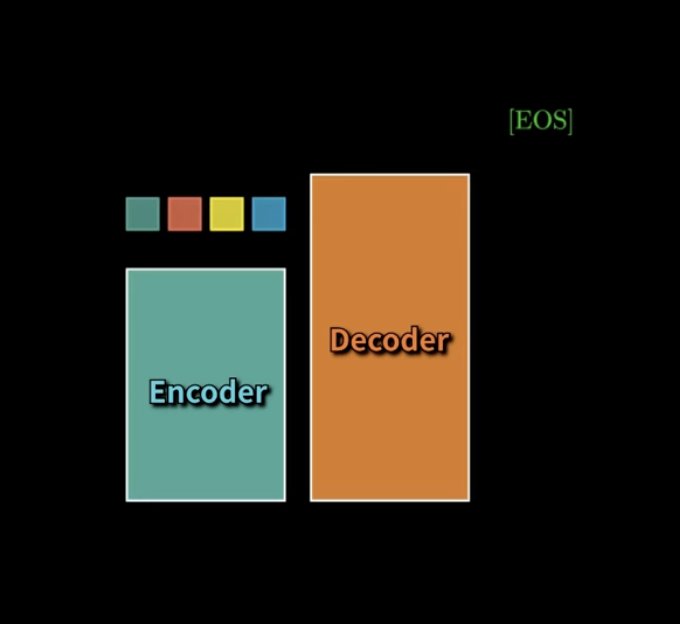
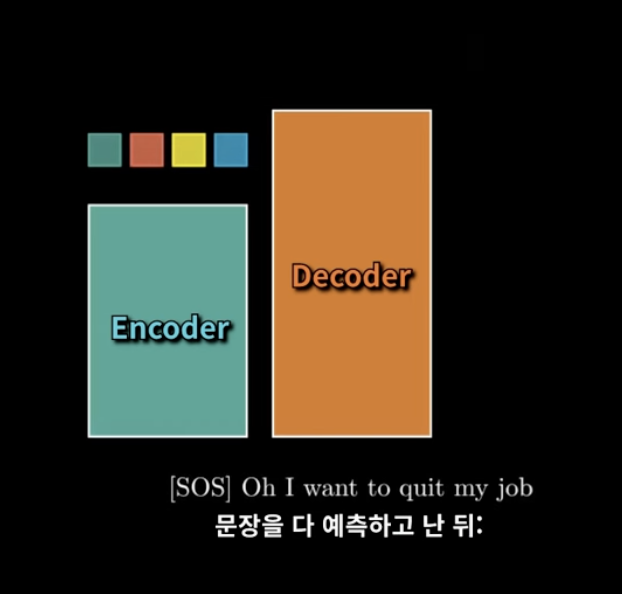
EOS 토큰!

최종적으로는 이렇게 N-1개의 단어를 넣어서 N번째 단어를 예측하는 과정을 반복하면 된다! ! ! ! !
근데...꼭 하나씩 하나씩 넣어야할까...?
계속 반복하기가 너무 귀찮아요...
한번에 넣어요!
그것이 바로 그 무시무시한... 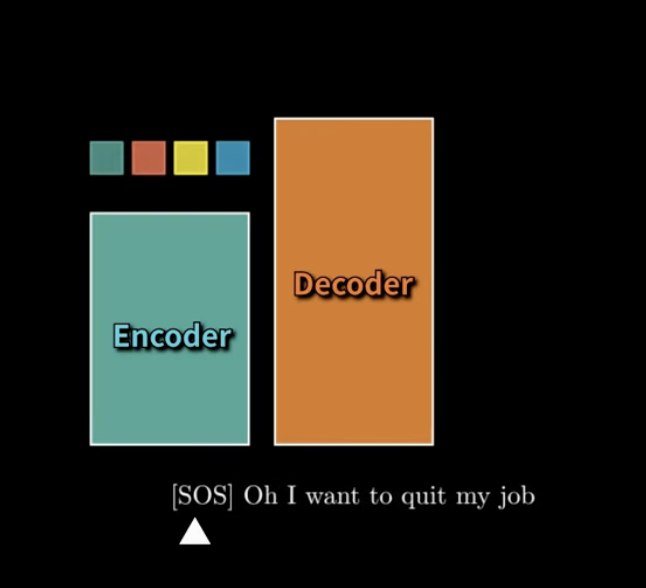
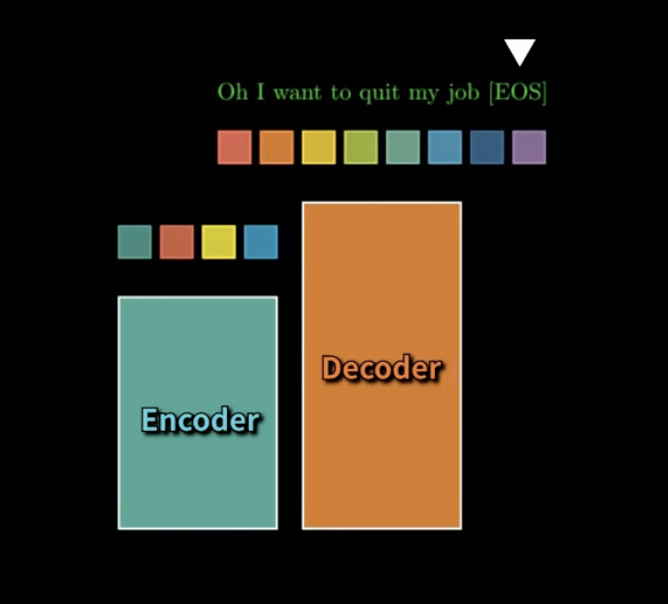
한번 밀어넣으면 병렬적으로 가능!!!
하지만 이걸 그냥 학습시키면 심각한 문제가 있음.
예를 들어, Oh를 예측하도록 학습을 시킨다고 할 때,,,
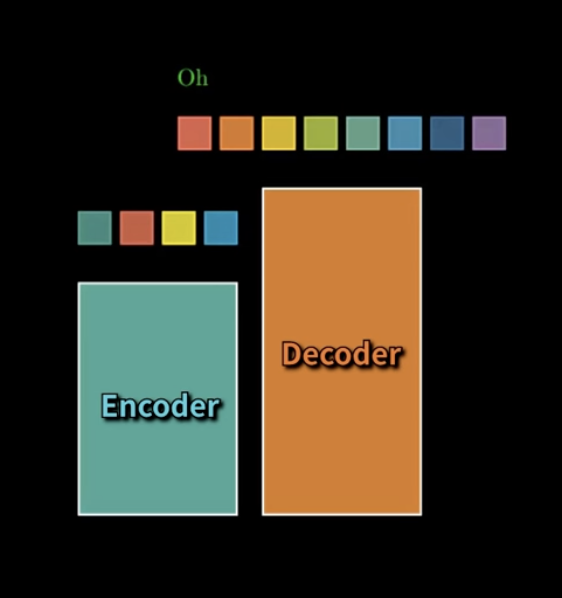
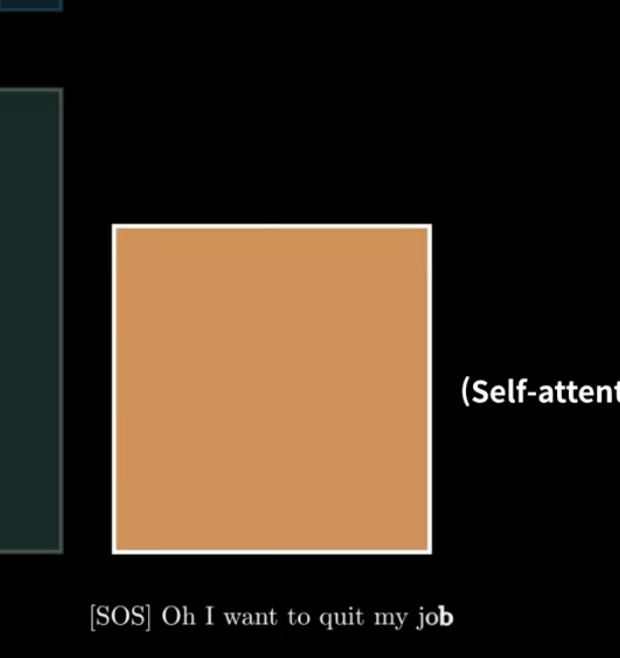
-> 이렇게 미래정보까지 써버리면 ㄴ어떻게 해??!!!
-> 다 정보를 갖고 있으면... 다른 단어의 정보를 가지고 있으니까 전부 다 활용하고 있음...
-> 사용할 수 없는 번역기...
이걸 해결하기 위해!
첫번째 단어 예측할 땐 
두번째 단어 예측할 땐 
MASKING이 등장!
MASKING
: 내적 결과에 극단적인 음수 값을 주는 방식!!!!!!! -999999이런식... 그러면 softmax에 통과시키면 값이 0이 되겠지. !!!

Transformer 추가
사실 이것만으로는 부족하기 때문에...
다른 곳에서 공부했던 것들을 추가해보겠다!!
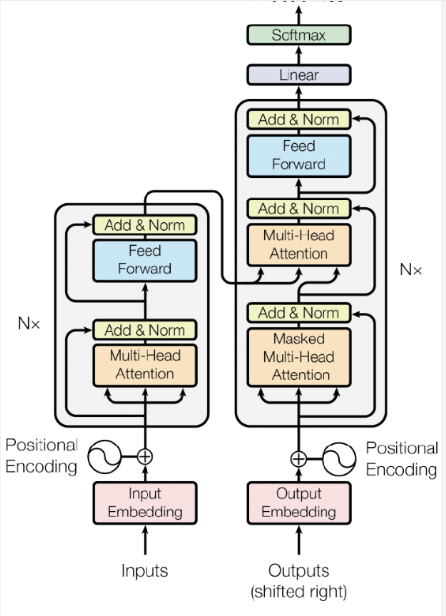
input
인풋 : 예를 들어 , 32x50xmax_len 로 one-hot되어있음.
여기서, 7851은?
내가 써먹을 수 있는 한글 단어의 총 개수! Embedding Vector : 예를 들어, (max_len x 512)을 통과 시키면 32 x 50 x 512의 Embedding Vector!
각 차원의 의미 : 32는 문장 개수 / 50은 단어 개수 / 512는 차원의 수
input + Positional Encoding
둘은 더하는 거다!!
Query , Key, Value
- Query,Key,Value 만들기
Query : (512 x 64)를 통과 시키면 32 x 50 x 64의 Query Vector
Key : (512 x 64)를 통과 시키면 32 x 50 x 64의 Key Vector들!
Value : (512 x 64)를 통과 시키면 32 x 50 x 64의 Value Vector들!
그리고 나서 
-
내적하기
Query x Key.T = (32 x 50 x 64) x (64 x 50 x 32) = 32 x 32
정사각형 느낌!!ㅎㅎ -
Scaling하기
그럼 왜 scaling을 할까?? 여기서 dk=64 니까 64에 루트를 취해서 나눠준다.
내적의 분산이 자꾸 커지니까!! 그래서 softmax의 미분이 작아지는 것을 막는다. -
Value랑 곱해주기
(Query x Key.T 를 Scaling) x Value = (32 x 32) x (32 x 50 x 64) = 32 x 50 x 64
- Softmax
그런다음에 softmax를 취한다.
softmax를 취하는 이유는, 아까도 봤듯이 "Query랑 유사한 정도"이기에 비율로 표현해준 것이다!
잠깐 상식!
softmax : 다중분류에서 합이 1인 확률값으로 표현하기 위해 쓰이는 함수
sigmoid : 이중분류에서 합이 1인 확률값으로 표현하기 위해 쓰이는 함수
Multi-Head-Attention
결국, 똑같이 32x50x64가 있는거겠지?
근데 이게 여러개면???
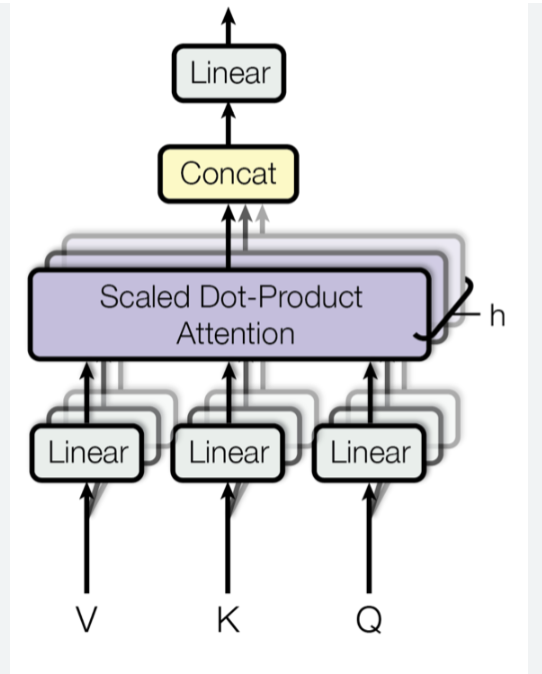
그게 바로 multi-head-attention인 거다.
효과 : 헤드마다 주목하는 게 다 다르다!!!
-
Concat
8개가 있다고 치면,
이걸 예를 들어 8개를 가로로 Concat(더해줌)하는 것이다.
(32x50x64) + (32x50x64) + ...
= (32x50x512) -
Linear
그리고 나서 다시 Linear를 통과시키면...
다시 (32x 50 x 512) x (512 x 512) = 32 x 50 x 512
다시한번 말하지만,
32는 문장 개수, 50은 단어 개수 512는 차원의 수다!
Encoder 전체 구조
ResNet의 skip connection을 쓰는데...
이건 일단 다음 번에 설명할 기회가 있으면 쓰겠다!!!
그리고 나서 Layer Normalization도 하는데...
이것도...다음에
그리고 나서 Feed Forward 통과 시키고
그리고 나서 이걸 6번이나 반복하는 것이다.
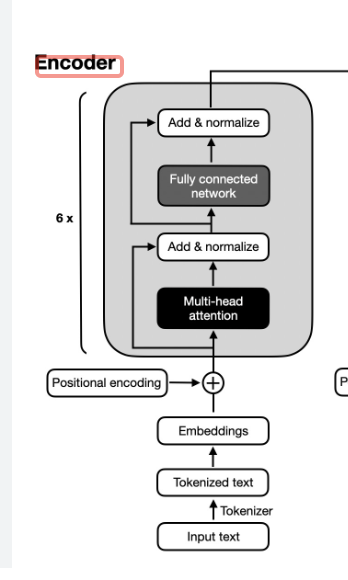
왼쪽에 6번이라고 써있는 게 보이는가!!
Decoder 전체 구조
아까 보았던 MHA (Masked-Head Attention)을 활용한다.
그리고 똑같이 Add,Norm 통과하고 얘도 6번 반복!
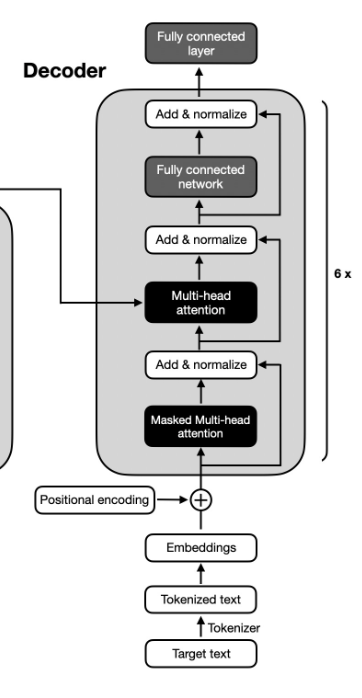
Last Stage
Decoder의 마지막 Layer의 출력을 쓴다.
그냥, nn.Linear(512,5972) 통과시키면 됨.
Softmax 통과시키고 Cross-Entropy로 Loss정의!
추론할 때는 가장 높은 확률에 해당하는 단어 선택
결론
결국, 임베딩 벡터를 어디로 위치시킬지 학습하는 거다!!

학습이 진행이 되면서, 임베딩 벡터는 업데이트가 되어서 최적의 위치를 찾게 되는 것이다...!!!
하 GPT를 향한 여정이 길다.
매우.
힘들다.
끝!!!!!!!!
