Transformer에 대해 (2)번째 포스트에서 다뤘었는데!!
아무래도 Transformer의 특징에 대해서는 깊게 다루지 못한 것 같아 포스팅을 작성하게 되었다.
출처 : https://www.youtube.com/watch?v=kCc8FmEb1nY&t=4304s
1. Attention은 communication mechanism이다.
상황 : directed 그래프에서 엣지들이 있고, 노드들이 있음.
[Masked X]
노드에는 vector of information,엣지에는 weights가!
=> ingoing edges의 weighted sum을 활용!!!
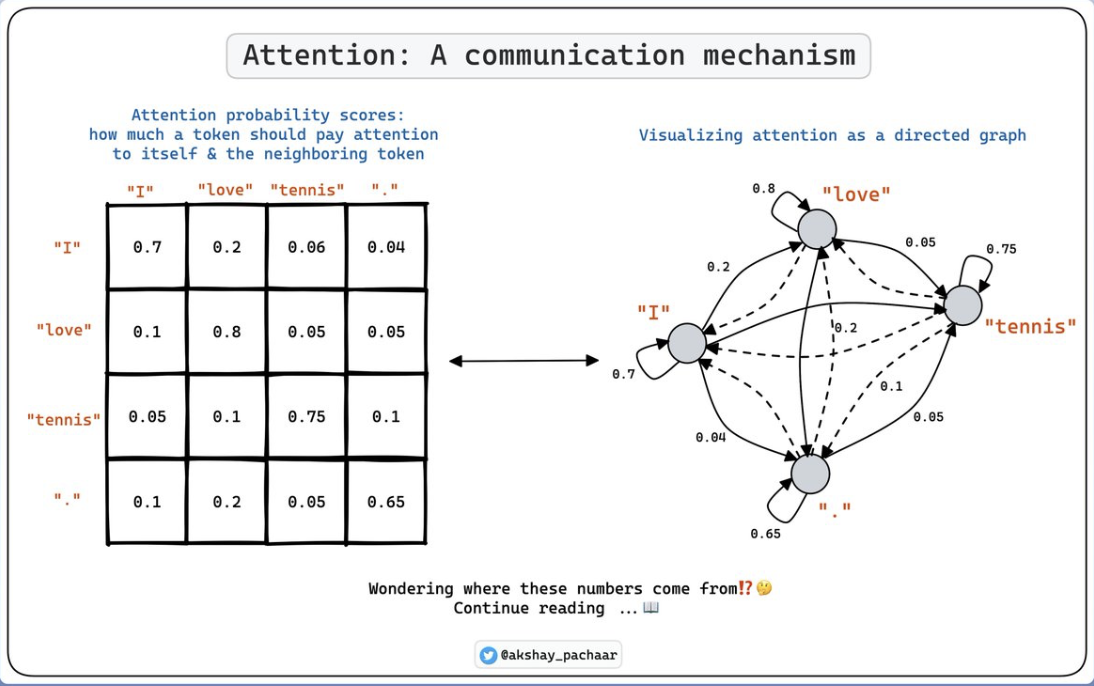
(물론 여기서는 edge들만 값을 갖고 있음)
[Masked O]
만약 위의 그림으로 예시를 들어보자면,
"I" 노드 : ingoing edge는 "I" edge뿐
"love" 노드 : ingoing edge는 "love" edge,"I" edge
"tennis" 노드 : ingoing edge는 "tennis" edge,"love" edge, "I"edge
2. 공간의 개념이 부재하다.
그래서 우리가 positional encoding을 해야만 한다.
반면에 Convolution에서는?
굉장히 specific한 layout of information 이 있다. 그래서 positonal encoding을 하지 않아도 된다.
3. Batch 내의 각각 example들은 그 배치 내에서만 communicate한다.
즉, batch size가 8이라고 가정하면, 첫번째 배치에 있는 8개의 문장들만 서로서로 communicate한다. 그리고 두번째 배치에 있는 8개의 문장들만 서로서로 communicate한다.
첫번째 배치의 문장들과 두번째 배치의 문장들은 communicate할 일이 없다.
예를들어, (B,T,C)가 (8,4,32)라고 한다고 가정해보자.
그러면 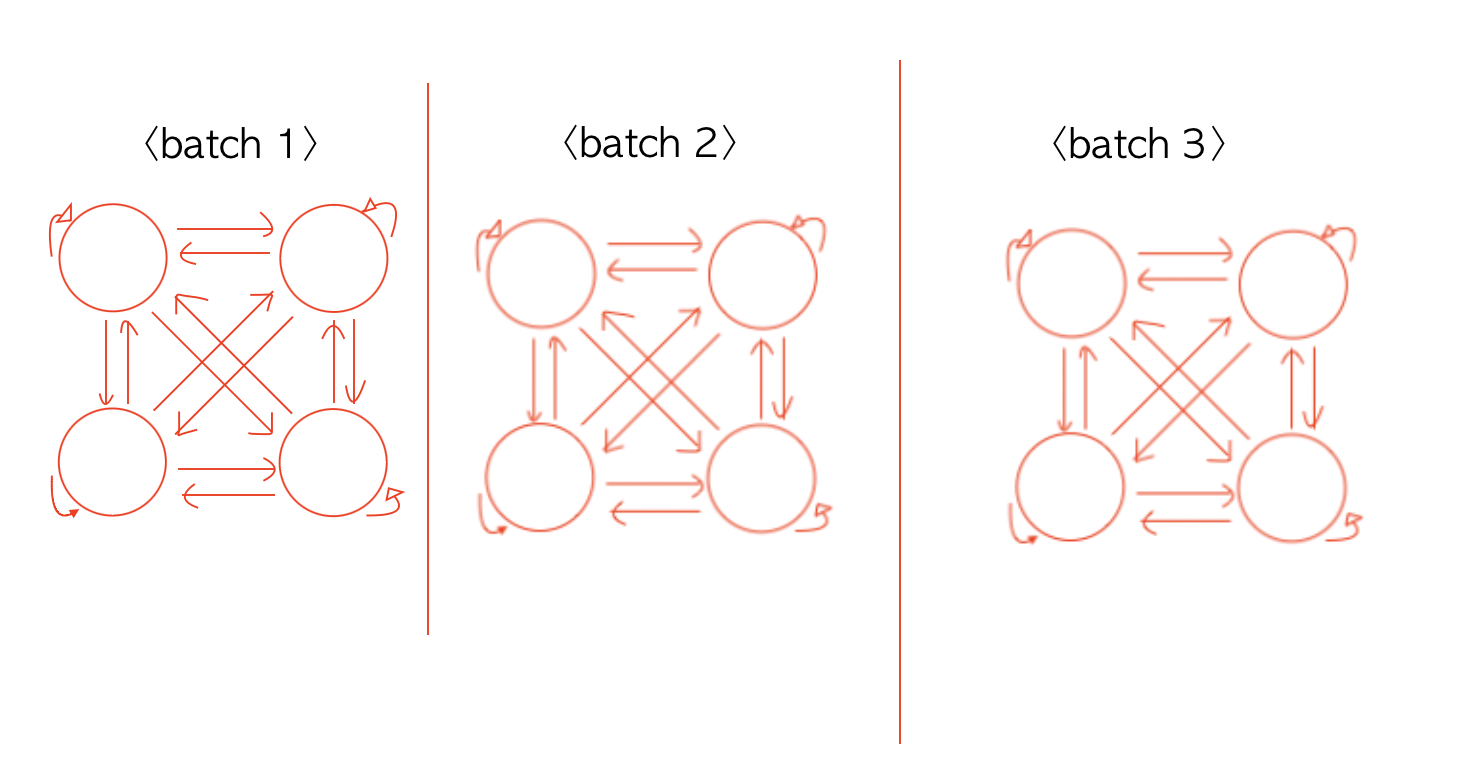
이렇게 batch 내의 token들은 서로 communicate하지만,
만약 서로 다른 batch라면 communicate할 일이 없다는 것이다.
참고로 위는 encoder block내에 일어나는 일이라 가정.
4. Auto-Regressive model
잠깐 상식. 하도 auto regressive이란 말이 많이 나오길래...auto regressive란?
Autoregressive models are a class of machine learning (ML) models that automatically predict the next component in a sequence by taking measurements from previous inputs in the sequence.
5. Cross - Attention?
Self-Attention인 이유는, k,q,v가 같은 source로부터 오기 때문에.
하지만, query가 x로부터오고 key,value가 y로부터 오는 그런 것도 있음. 그것이 바로 cross-Attention...!
6. scaling의 이유
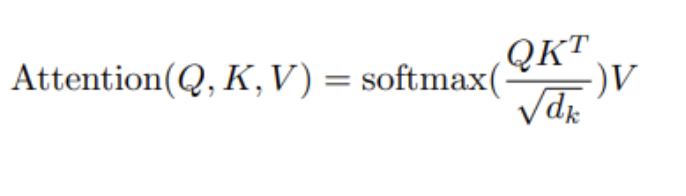
: variance가 1이 되도록.
가중치가 fairly distributed되는 게 중요.
scaling을 하지 않으면 one-hot vector로 됨.
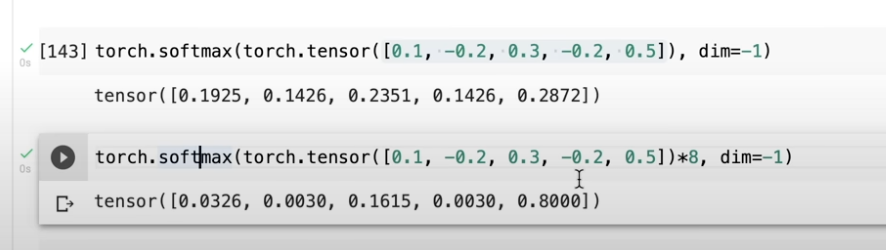
이렇게 scaling된 경우는 잘 distributed된건데 scaling을 하지 않으면 거의 뭐 one-hot encoding된 거나 마찬가지임.
