그냥 간단하게 넘길라 했는데 GPT에 이 내용이 나와서 어쩔 수 없이 적는다.
Skip Connection
Skip Connection은,
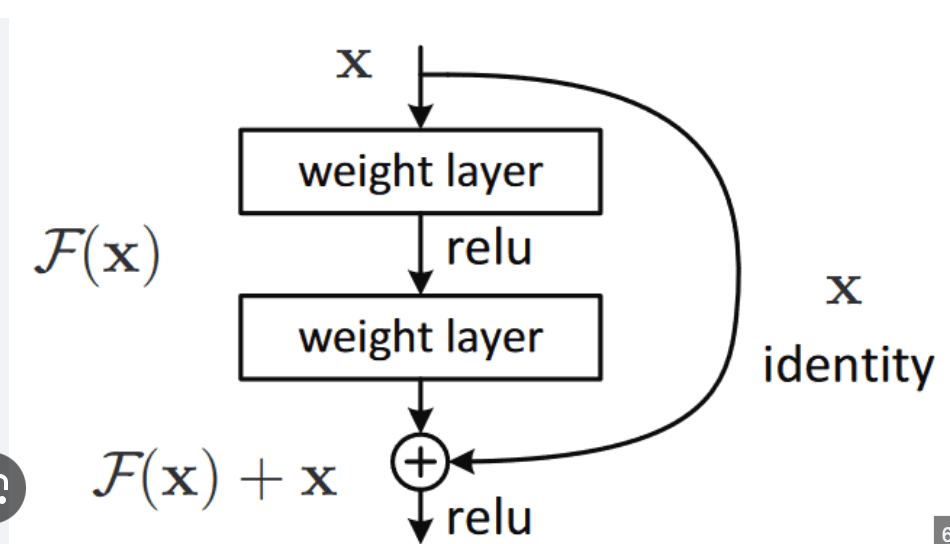
출처 : 위키독스
기존에는, 그냥 input이 들어가면 function은 아웃풋을 예측하도록 만들어졌는데,
Skip Connection은 input이 들어가면 function은 아웃풋을 제외한 부분을 예측하도록 만들어두는 것이다.
가정
여기에는 아주 큰 가정이 있따. H(X)가 X와 비슷할 경우...라는 것이다.
=> 입력부터 차근 차근 바꿔나가는 것이 이상적이지 않을까?
=> 잘학습된 ResNet의 경우에는, 값의 변화가 그리 크지 않을 거다.
=> '값이 막 그렇게 많이 변하지 않을테니, 조금씩만 바꾸자~'라고 말하는 것!
학습
그러면 학습은 어떻게 시키는데?
차이만을 학습시키는 것!
구체적으로, DenseNet에 관한 설명ㅇ은 나중에...ㅎㅎ
Batch Normalization
마치 random variable 처럼!!!
가우시안 분포처럼...!
배치가 32라면, 행이 32개인거니까 값은 총 32개...!
1. 평균
2. 분산
3. 얘를 정규화해줌(어떻게 보면 표본평균으로 빼주고, 표본표준편차로 나눈다고 할 수 있음.) 
- 다시 감마를 곱하고, 베타를 정한 게 Batch Normalization!
여기서 감마,베타는?
트레이닝 파라미터!
여기서는, 감마랑 베타가 32쌍이 있는 것임...(노드당 두개)
그럼 Test할 때는?
그동안 구했던 표본평균의 평균을 구해서 쓴다!!!
그동안 구했던 표본분산의 평균을 구해서 쓴다!!!
즉, Expectation을 취할거다. 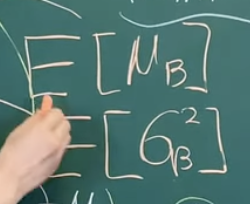
그리고 잘 traing된 감마와 베타를 활용해서 y값을 구하고 activation을 통과시킨다.
여기서, 평균을 할 떄는,
m으로 나누는 게 아니라 m-1로 나눈다.이건 확률과 통계에서 나오는 것...
Unbiased estimator니까...
왜 근데 빼고 나누고 또 곱하고 더해?
- Normalize의 이유
일단, 평균이 0이고 분산이 1이도록 만든거야.
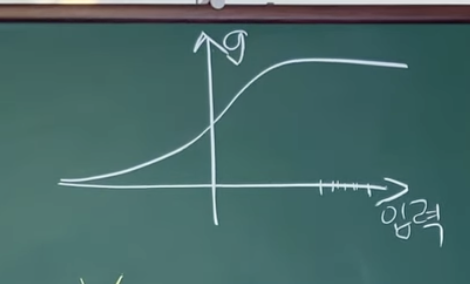
만약, 이렇게 오른쪽으로 되어있으면,,,Vanishing gradient가 생길것이다. 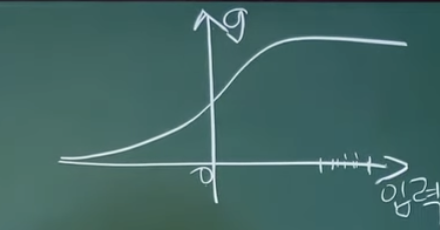
0근처로 하게 되면 Vanishing Gradient가 사라질 거야...
그러니까, Vanishing Gradient를 없애기 위해서...
근데 그러면,,,굳이 감마와 베타를 파라미터로 두고 shifting을 할 필요가 없지 않니?
- 거기에다가 Shifting의 이유
그리고 나서 감마를 곱하고 베타를 더하는 건,
정규분포인 상태에서 shifting하는 것이다...!!!!!
이 Shift가 필요한 이유는,
그냥 계속 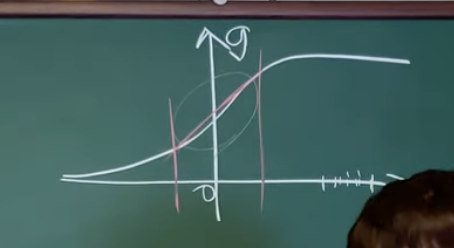
이 구간에 머물러있으니, 시그모이드가 아니게 된거야...
그래도 어떤 애는 오른쪽 끝에 있고, 어떤 애는 왼쪽 끝에 있고 이래야하는데
아예 모든 게 다 0에 몰려있으니 이게 더이상 시그모이드의 역할을 할 수 없는거지...
시그모이드의 역할을 할 수 없으면 발생하는 문제?
시그모이드는, 일종의 '확률값'을 나타낸다.1로 분류할 확률이 0.4이고 0으로 분류할 확률이 0.6인 것이 있다고 쳐보자.
1로 분류할 확률이 0.1이고 0으로 분류할 확률이 0.9인 것이 있다고 쳐보자.
-> 그러면 전자는 non-linearity가 없음...
즉, 입력 값의 차이에 따른 출력 값의 변화가 매우 작아져 비선형성이 상실...
선형성 vs 비선형성
선형성 : 선형 함수는 입력 값의 변화에 비례하여 출력 값이 변화
비선형성 : 비선형 함수는 입력 값의 변화에 비례하지 않으며, 복잡한 패턴을 모델링가능.
종합하자면, Vanishing Gradient 막기 + Non-linearity 유지!
Layer Normalization
해당 레이어에 대해!!!
아까 Batch Normalization은 해당 노드에 대해서...
얼마나 Non-linearlity를 살릴까?
데이터 하나가 들어올 때,
모두가 양수면 non-linearity를 충족할까? 걍 ReLU통과시킨 거랑 똑같지 않을까.
레이어의
1. 평균
2. 분산
3. 얘를 정규화해줌
4. 다시 감마를 곱하고, 베타를 정한 게 Layer Normalization!
'레이어마다'!!!!!
Batch Normalization과 다른 점
1. Layer Normalization은 표본평균의 평균을,표본분산의 평균을 구할 필요가 없음.
왜냐면, 레이어당 두개의 파라미터밖에 없기 때문에...
2. 배치사이즈의 영향X
3. LN은 자연어처리에 쓰임.
