논문 링크 :
https://www.nature.com/articles/s41599-024-03611-3.pdf
무려 네이처지에 등장한 논문이다!
Introduction
- simulation의 정의 ?
simulaiton은, computational tool로써 인간 세계 혹은 시스템을 모방한다.
- 작동 방법 ?
= specific behavior, attribute, decision-making 능력을 assign하기
- simulation의 중요성
- 현상 이해
- 현상 분석
- 현상 예측
: 실제로 일어나는 것을 관찰하기 어려운 현상들을 이해, 분석, 예측해보는 도구로써 활용이 되는 것이다.
⇒ 가설 검증 & 결정에 도움을 준다.
- llm agent의 중요성
- 명백한 instruction이 없다고 하더라도 액션을 취할 수 있다.
- 진짜 인간처럼 행동을 할 수가 있다.
- 다른 에이전트들이랑 상호작용을 할 수가 있다.
⇒ 그렇다보니, 인간-level 지능에 새로운 패러다임을 불러일으킬 것이다.
논문 전개 방식 ?
1 ) llm agent의 기존 연구들보기
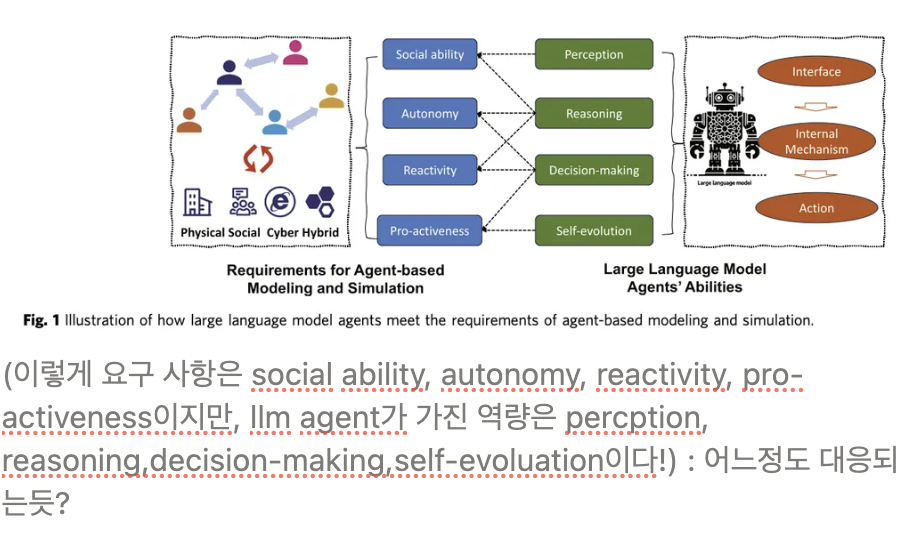
2 ) simulation에 필요한 ability ?
- autonomy
- social ability
- reactivity
- proactiveness
3 ) simulation에 필요한 ability를 어떻게 해서 llm agent가 충족 시키는지?
4 ) llm-agent가 simulation에 사용되는 4가지 도메인
- cyber
- physical
- social
- hybrid
5 ) 새로운 연구 방향은 어디일까?
Background
Agent-based simulation
-
agent
-
environment
-
interaction
- agent-to-agent
- agent-to-environment
- environment-to-agent
-
agent capability
: agent들이 어떤 특성을 가져야 하니?
-
autonomy
-
social ability
: 협력적/경쟁적일 수도 있음.
-
reactivity
: 되게 적응을 빠르게 해야함.
-
pro-activeness
: 목표 지향적인 행동을 해야함.
-
Agent-based simulation domain
- phsical domain
- 생태학
- 생물학
- 교통학 ( traffic pattern)
- 도시 계획( urban planning )
- 공학 ( engineering )
- social domain
- social interaction ( 소셜 네트워크 분석 같은 것 ! )
- economic system
- cyber domain
- hybrid domain
Agent-based simulation methodology
그러면, 사실상 어떻게 simulation을 할 지가 가장 화두일텐데…어떻게 하나?
-
predefined rules
: 특정한 situation에는 특정한 행동을 해라! 이렇게 미리 rule을…1984년 논문에 나온 기법임.
-
symbolic equations
: 좀더 formal하고 mathematical한 manner로 설명하려고 하는 것!
ex ) 보행자의 움직임을 newton-like law로 설명하려고 했음.
-
stochastic modeling
: random 상황에서 choice model들을 활용하여 ! !
ex ) 보행자의 움직임을 choice model을 사용하여 설명하려고 했음.
-
machine learning models
: 환경과의 상호작용을 통해 학습할 수 있도록
Large Language models and llm-empowered agents
- llm agent의 장점
- adaptively react
- 아이디어 생성
- 인간처럼 대응 가능
- 상호작용 능력!
Critical abilities of llm for agent-based modeling and simulation
agent-based modeling은 다양한 area에서 사용이 될 수 있음. 어떤 요소가 simulation을 가능케하고, 어떤 게 약간 limitation이 될 수 있는거지??
-
perception : “상호작용”
= 인간의 입장을 이해하고, 다양한 need와 감정에 대해 인지할 수 있어야 한다.
-
reason and decision making
- 예전모델들 : incorrect message보내고 진짜 뛰어나지 않았음.
- llm : 꽤 괜찮은 결정을 내린다.
-
Adaptive learning and evolution
- 예전 모델들 : 원래의 전략에서 벗어난 정책을 잘 못함.
- llm : 새 데이터를 계속 학습하고 맥락에 적응 가능 , 새로운결정 내릴 수 있다.
-
Heterogenity and personalizing
- 예전 모델들 :
-
매개 변수 설정 복잡
-
모델의 한계
: rule-based 모델이나 그런 전통적인 방법은 모든 차원의 이질성을 커버할 수가 없다.
-
모델이 너무 단순화
-
- llm : 복잡한 특성 capture할 수 있고, personalization이 가능하다.
- 예전 모델들 :
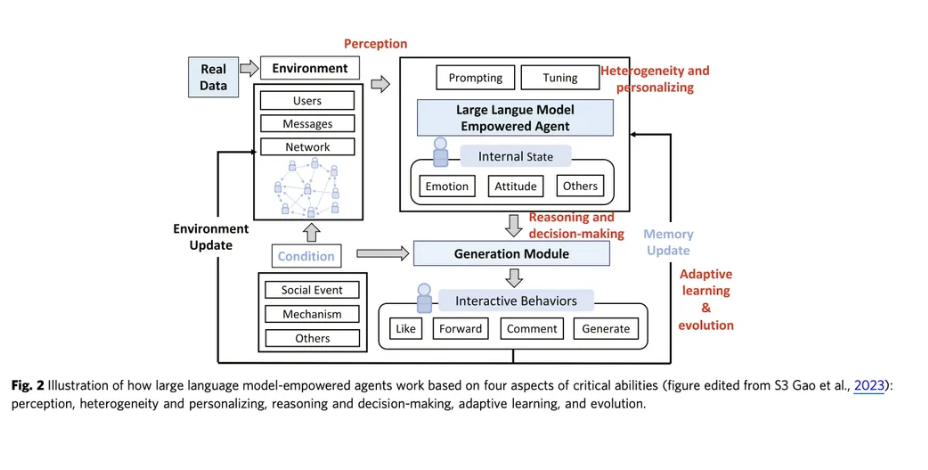
Challenges and approaches of llm agent-based modeling and simulation
agent-based modeling의 핵심은!
어떻게 에이전트가 환경이랑 상호작용하는지, 어떻게 에이전트가 서로 협력하는지, 에이전트가 현실세계의 인물들과 어떻게 가깝게 행동해야하는지…
⇒ 4개의 challenge가 존재한다.
(1) 환경 인식
(2) 적합한 액션 찾기
(3) 시뮬레이션 평가하기
-
Environment and construction and interface
첫번째 해야할 일은, 환경 자체를 구축하는 거.
그다음에 해야할 일은 , 에이전트가 어떻게 환경 혹은 다른 에이전트랑 상호작용할지 디자인하는 거.
- 환경 구축
: 세계와 그 규칙을 정한다.
ex ) Qian et al.(2024) 는 software company with multiple agents에서 CEO,manager,programmer 이렇게 역할을 정했었다.
ex ) Wang et al.(2023b) 는 virtual recommender system을 구축했는데 agent들이 추천콘텐츠들을 browse하고 피드백을 줄 수 있는 시스템이었다. 환경은 sandbox 환경이었다.
ex ) Generative Agent Park et al.(2023)는 Smallville sandbox world를 만들어서 llm agents들이 그들의 하루를 계획하고, 뉴스를 만들고, 관계를 정립했다.
- interface
: 어떻게 환경과 interact할지 ? 어떻게 agent와 interact할지?
환경과 interact - 대부분은 text를 기반으로 소통을 하게 된다. 아직까지는,,, 외부 환경을 perceive하면 그게 text로 여겨지는 것임.
agent와 interact - direct하게 소통 ( text로 ) / indirect하게 소통 ( rule-based로)
-
Human alignment and personalization
✅문제 : llm이 아무리 다양한 지식을 갖고 있더라고 하더라도, llm은 domain knowledge가 부족하다.
해결책 : llm agent를 인간의 지식, 즉, domain 전문가의 지식과 맞추기 ! ! !
⇒ 문제 : agent를 다르게(heterogeneous하게)만들어야 하는데…어떻게 domain 지식을 가지면서도 다르게 만들지?Human alignment -
1 ) prompt engineering
업무에 대한 설명, 배경지식, 패턴, 과업 예시…를 주면 된다.
ex ) 게임 룰에 대한 자세한 설명과 예시를 주게 주는 것…!
2 ) Tuning
특정 도메인에 대해 training dataset을 구축을 하는 것이다…!
ex ) Singhal et al.(2023)은 clinical medicine에서는 존재하는 6개의 medial data들을 합쳐서 tuning을 했다고 한다.
🤗**구체적으로 어떻게 tuning을 했을까~!?
- q&a 데이터로 fine-tuning을 한다.
- 그런다음 model prompt에 대한 답변을 확인한다.
- 의사들의 피드백에 따라 prompt를 조절해나간다.**
Personalization -
1 ) Prompt engineering
llm agent들이, 각각 선호하는 거 제공 ⇒ 인간의 사회적 상호작용의 복잡성 simulate 가능 !
ex ) AI town : 개인화된 상호작용을 할 수 있도록 직업, 행동 선호, 대인관계 이런 것들을 프롬프트에 추가했다.
2 ) Tuning
다양한 user들로부터 feedback을 받아서 각가의 모델들이 개인화된 니즈에 맞춰서 personalization을 할 수 있도록 한다.
⇒ 결국, 실제 세계 system의 다양성?을 모방할 수 있게 만든다 이게!!
-
How to simulate actions
-
Evaluation of llm agents
Recent advances in llm agent-based modeling and simulation
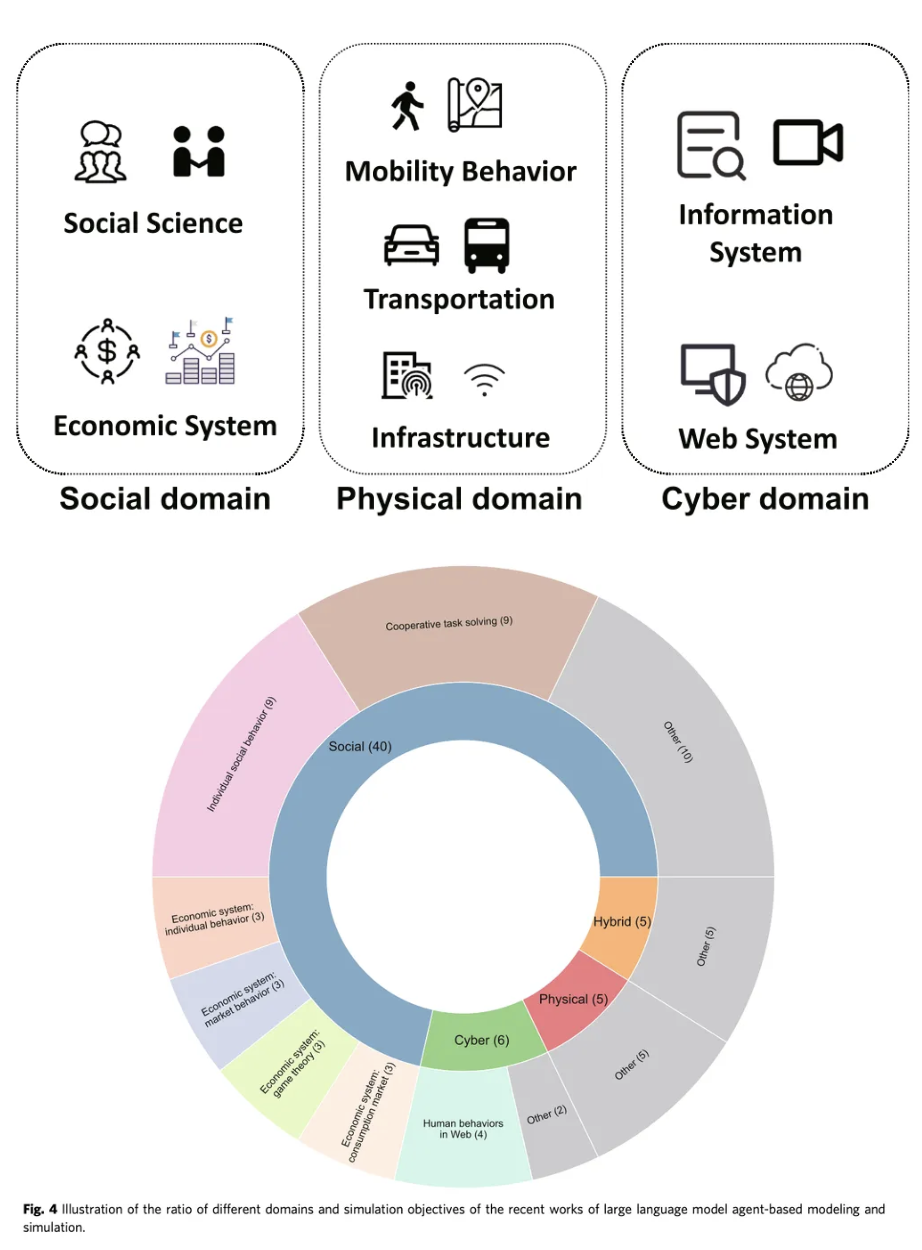
그렇다면 과연,,,llm agent-based modeling은 어떻게 발전하고 있는걸까~?
50%의 paper : planning
50%의 paper : reflection
80%의 paper : real-world evaluation
40%의 paper : ethical evaluation
1. Social Domain : Social science
-
social network dynamics
ex ) social network에서 개인적, 그리고 집합적인 행동을 simulate해보려고 함.
사용한 데이터 : 실제 real-world social network data
시나리오 : gender discrimination & nuclear energy
ex ) llm agent가 epidemic spread의 트렌드를 simulate할 수 있다…!
ex ) 늑대인간 게임에서, llm은 믿음이나 대립 이런 것들을 할 수 있니?
ex ) llm이 인간이 사회적 커뮤니케이션 상황에서 겪고 있는 그런 bias를 그대로 답습하나? ⇒ 결과는 llm은 neutral한 에이전트가 아니다…인간이 가진 그 bias를 그대로 답습
ex ) 포럼에서, 어떻게 온라인 행동들을 simulate할 수 있나?
ex ) 소셜 미디어에서 언어의 발전을 연구를 했다…? (Cai et al. 2024)
-
simulation of coorperation
어떻게 인간 사회를 모방할 수 있는지!!!
ex ) COLA : 소셜 미디어에서 각각의 agent들은 analyzer, debater,summarizer로.
analyzer - 텍스트의 문법이나 어휘 사용 평가, 전문적인 용어 세밀하게 보고, 커뮤니티의 반응을 살펴본다.
debater - 논리적인 구조를 통해 설명!
summarizer - analyzer와 debater의 결론을 종합해서 결정.
ex ) MAD : 싸움에서 어떻게 결론으로 다다르지?
each agent - 무조건 싸우기
judge - 최종적인 결론에 다다르도록 평가하기!
ex ) MetaGPT -
pm -
architect -
engineer -
ex ) ChatEval : text quality 평가하도록!
public - 대중
critic - 비평가
jouranlist - 기자
scientist - 과학자
judge - 최종적으로 모든 agent의 말을 듣고, judge가 판단하도록!
ex ) CAMEL - 협력적인 role-playing
task detaling assistant - task를 자세하게 설명
commander - step-by-step instruction을 준다.
executor - 그 instruction을 실행
ex ) Agent Hospital - llm agent로 병 치료!
🤗그렇다면, 이렇게 cooperation을 하는 데에 한계점은 없을까??ㅠㅠ
→ 가장 큰 건, versatility. 즉, 그 상황을 만드는 것일뿐, 모두에 대응하는 그런 framework를 만들기가 매우 까다롭다.
하지만 이에 관한 연구는 진행이 되어가고 있음. 이제 진정한 AGI 시대가 되는걸까…?!!!
연구1. AgentVerse(Chen et al.,2024) : 인간의 group problem-solving 상황에서, adaptively llm agents들을 다양한 task에 만들어내는거지
(1) expert recruitment : 여기서 agent의 구성이 결정되는 것임
(2) collaborative deciison-making : agent들이 problem-solving 전략들을 짜는 것
(3) action execution : agent들이 이 전략들을 실행하는 것
(4) evaluation : 성과를 asses하고, 향상을 guide하는 것!
⇒ coding부터 다양한 일들에 성과를 보였다고 함… 헉.
연구2. SPP(wang et al.,2023) : 하나의 single llm을 multi-persona agent로 변화시킨다.
연구3. CoELA(Zhang et al.,2024b) : llm의 nlp,추론,communication 능력을 modular framework에 담았따…
-
simulation of individual social behavior
정말 인간의 대답을 인간의 관점에서 하는 것도 굉장한 숙제임. 약간 큰 틀에서 인간들의 상호작용에 관해 연구하는 것이 아니라, 인간의 개인 행동을 simulation 잘하는 것도 숙제인 것이지…
ex ) SocioDojo
: analyst - assistant - actuator 프레임워크
ex ) llm agent와 실제 참가자들의 반응 비교
: 응답과 실제 데이터간의 유사성을 비교해봤다… 그랬더니 사실 별로 차이가 없었음.
ex ) social science 연구에서
: 특정 인구 집단의 비율로 llm agent를 써서 사회 과학 연구에서의 반응생성.
2. Social domain : economic system
-
individual behavior
: 행동 경제학 실험에서…!
ex ) 독재자 게임, 공정성 제약ex ) chen at al.(2023e) : llm이 경제적 결정에서 합리적인가?
ex ) Xie et. al(2023) : llm이 주식 시장을 지극ㅁ까지의 주식 데이터와 관계된 tweet가지고 잘 예측?
⇒ 안타깝게도 예측은 불가.
-
interactive
-
system-level
: 물품을 교환하고, 시장을 형성하는데…그렇다면 그냥 한 개인이 아니라 agent는 기관,은행,기업 이런 걸로도 대표될 수 있는 거 아닌가?
ex ) Zhao et al.(2023b) : 레스토랑을 경영하는 데에 필요한 행동들…여기서 다른 레스토랑이 유명해지고 그 레스토랑이 돈을 많이 버니까, 다른 레스토랑은 그 레스토랑을 모방하는 경향을 보였다.
ex ) Han et al.(2023) : 시장에서 2개의 회사의 가격 책정 상황을 simulation했다. 결과는 소통이 있으면, 담합을…하는 경향을 보였다…
3. Physical domain :
-
llm agents for simulating mobility behaviors
ex ) gurnee and tegmark,2024 : llm이 실제 세계의 정보를 파악하고, 그 결과는 그 모델들이 실제로 그 정보들을 다 잘 파악한 것으로 드러났다.
ex ) Manvi et al.2024 : geospatial knowledge를 알 수 있었다…!!!
-
llm agent-based modeling and simulation for transportation
ex ) jin et al.(2023 ) : 과연 인간 운전자의 운전 행동은 어떨까???
⇒ memory module에 있는 것도 잘 사용하면서, safety criteria도 잘 맞추면서…
⇒ 결국에는 충돌률이 감소하고, 좀더 인간같은 그런 행동을 보여줬다…!
-
llm agent-based modeling and simulation for wireless network
무선 통신에서도 사용이 될 수 있다.
ex ) Zou et al.(2023) : 다양한 on-device llm agent가 가 어려운 task를 같이 푸는 것을 발견해냈다…
⇒ 각각의 device에 있던 agent의 문제점들을 해결하는 그런 모습을 보였다…
4. Cyber domain
ex) WebAgent(Gur et al.2024) : 자연어 instruction만을 가지고 실제 website에서 인간의 행동을 모방…
🤗어떻게 이게 실현되는거지?
-
instruction이 주어짐
-
instruction을 sub-part로 나눔.
(HTML document를 section들로 나누는 것임
ex) Mind2web(2024) : llm을 써서 HTML을 pre-filtering함. 그런다음에 저 WebAgent를 활용하는 것임…!
5. Hybrid domain
ex ) Hua et al.(2023) : llm agent를 써서 역사적 국제 분쟁(세계대전 등)의 결정을 시뮬레이션 했다…
ex ) Williams et al.(2023) : 전염병에서, 사회적인 관계가 얼마나 영향을 미치는지?
Open Problems and future directions
Efficiency and scaling up
-
일단 지금 현재는, 다양한 persona를 가지고 있는 것을 simulate하는 것이 이득이라고 하고 있음.
-
하지만, llm agent들을 그렇게 많은 llm agent들을 가지고 simulate하는 거 자체가 돈이 엄청나게 많이 든다.
⇒ 단점 : 돈 , 성능 …
⇒ 해결책 : batch prompting ? (하지만 완벽하게 해결x)
benchmark
벤치마크들이 우수수 등장하고 있긴 하다.
-
decision & planning
- ALFWorld : high-level planner
- ComplexWorld : high-level planner
-
simulation : 이 simulation 벤치마크는 아직… 없다.
However, developing benchmarks for quantitative and qualitative evaluation of LLM-driven agent-based simulation remains a largely open problem
and a promising future research direction.
open platform
-
voyager
= 인간의 개입 없이 minecraft에서 다양한 스킬들을 얻을 수 있는 에이전트들을 디자인 할 수 있는..
-
ModelScope-Agent
= …
⇒ 얘네는 다 planning이다!!!!
⇒ 하지만, simulation을 위한 Open platform은 아직 부족하다는 것을 알 수 있음.
robustness of llm-driven agent-based simulation
🤗robustness란?
= 강건성!
- adversarial attack
- out-of-distribution generalization
⇒ 애초에 llm모델이 강건하지가 않으니까…
현재의 해결방법 :
1 ) erase-and-check filter : 적대적 프롬프트 탐지하는 방식!
- 원문 For example, researchers propose to certify LLM safety with an erase-and-check filter that detects adversarial prompts (Kumar et al., 2023).
2 ) 안전한 응답 선택 : 다양한 응답중에서 안전한 걸 선택해서, 시스템의 robustness향상시킨다.
ethical risk of llm agent..
여기서도, llm agent의 ethical risk가 존재한다고 써놨다.
문제 1 : llm의 bias나 고정관념 존재…
-
sementic ilusions and cognitive reflection test
⇒ GPT4같은 애들은 인간으로부터 reinforcement learning 방식으로 피드백을 받아서, 거의 accuracy가 너무 높았다!
⇒ 결국, 인간의 선호를 언어모델에 넣는게 매우 중요하다…
문제 2 : 과연 그러면 simulaton 상황에서는 ethical risk가 어떨까?
-
Deshpande et al.2023 : chatgpt한테 어떤 특정한 persona를 만들 게 했을 때, 6배나 더 toxic하고, 더 차별적인 고정관념을 가졌다…
⇒ 예를 들어, 흑인에 대한 persona를 만들었을 때, 그게 백인 persona를 만든 것보다 훨씬 더 toxic하고 차별적이었다 이렇게 생각하면 될듯.
-
Acerbi and stubbersfield(2023) : llm agent가 인간과 같은 bias를 경험하고, 그리고 그들이 똑같은 고정관념을 가짐…
그렇다면 이게 왜 문제가 될까?
이게 lllm multi-agent simulation에서, 상호작용하는 동안 이런 편향성이 더 강화될 수 있는 것이다…!!!
그렇다면 어떻게 해결하고 있지?
-
align language models with human values
Yao et al.2023a
이 alingment를 어떻게 하냐면, alignment goal을 human instruction, human preferences, human values 이렇게 3가지로 나눴다!
Yi et al. 2023
이 alignment를 fairness, loyalty, authority, sanctity 이렇게 나눴따!
문제 3 : 어떤 특정한 persona로 assign 되었을 때. 단순한 풍자에 되게 취약하다는 게 알려짐.
해결책은, CoMPosT framework!
⇒ simulated llm 에이전트 상황에서 단순화된 풍자를 측정할 그런 도구?를 만들었다고 함.
⇒ GPT-4같은 애들도 정치적인 상황에서 그런 단순화된 풍자에 속수무책이라고 함.
문제 4 : llm agent의 해석 가능성ㅠㅠ
해결책 : llm agent의 interpretability를 위해 연구가 있다네?
https://dl.acm.org/doi/pdf/10.1145/3639372
( 요게 explainability for large language model : a survey)
