
Phase 2 아키텍처는 초당 5만 건의 요청을 처리하기 위한 견고한 이론적 기반이었다.
NLB를 통한 수평 확장, MSK를 이용한 데이터 파이프라인 안정화, ClickHouse의 읽기/쓰기 분리까지
그러나 이론 설계와 실제 운영 사이에는 언제나 예상치 못한 변수가 존재했다.
목표치를 달성하는 과정에서 우리는 시스템 깊숙이 숨어 있던 병목들을
데이터 기반으로 파헤치고 해결해야 했다.
문제 1: AWS 서비스 할당량(Service Quota)
현상
프로듀서 Auto Scaling Group(ASG)의 인스턴스 타입을
c6i.xlarge(4 vCPU)로 바꾸고 Desired Capacity를 12대로 설정하자
인스턴스 시작이 반복적으로 실패했다.
분석
ASG 활동 기록에서 다음 오류를 확인했다.
You have requested more vCPU capacity than your current vCPU limit of 64 allows…- 12 대 × 4 vCPU = 48 vCPU
- 기존 인프라(ClickHouse, Bastion 등) 사용량 ≈ 40 vCPU
- 계정 전체 한도 64 vCPU → 초과
1차 해결
Service Quotas에서 Running On-Demand Standard instances 할당량을 256 vCPU로 상향 신청.
2차 문제 발견
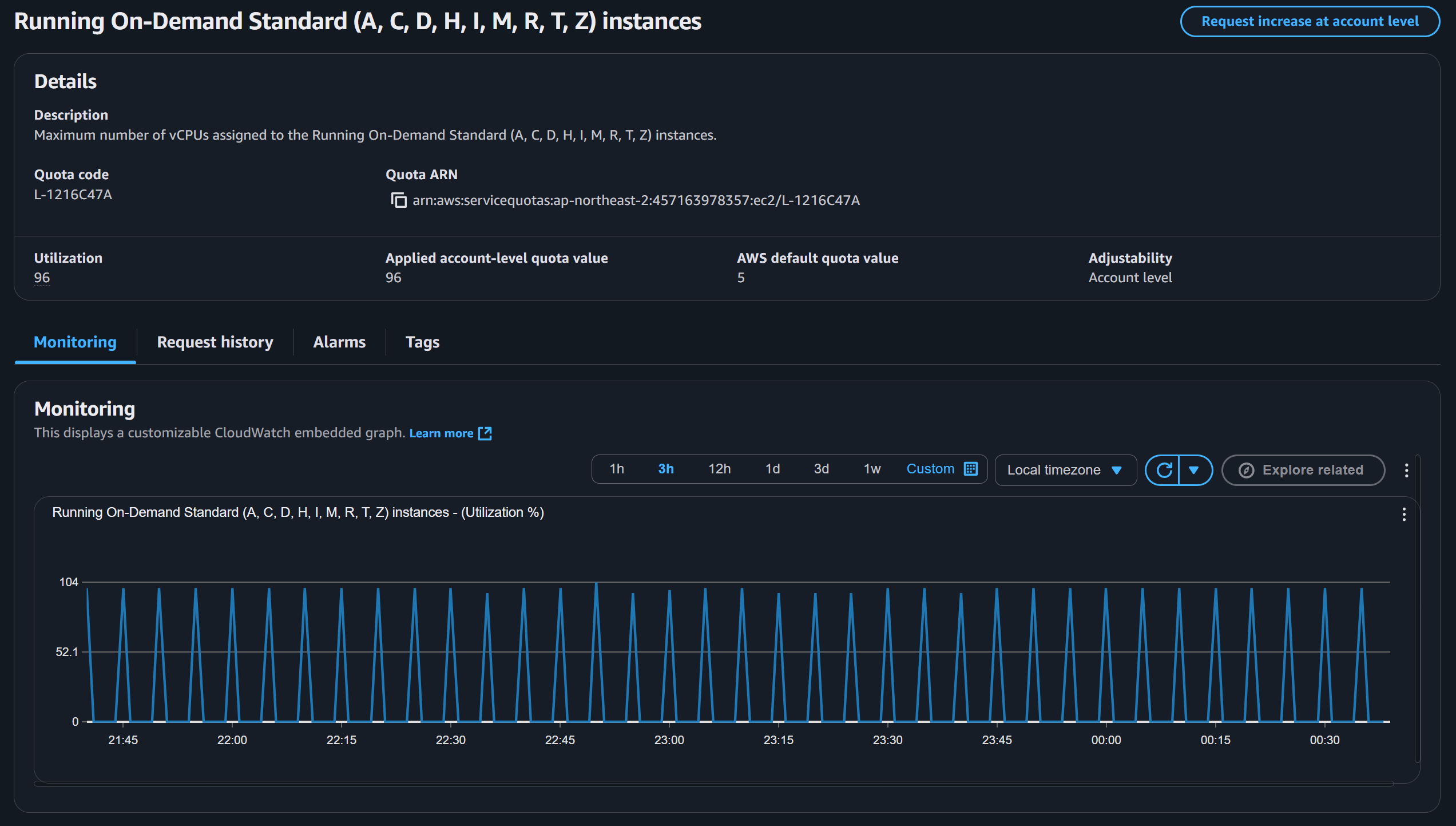
- 전체 vCPU 사용량이 96 개에 근접 → 인스턴스 교체·확장 여유 0
- 고성능 아키텍처 운영 시 숨겨진 제약 확인이 필수임을 절감
- vCPU256 Quota를 256으로 상향해달라고 신청했는데, 96까지만 상향해주었다.
문제 2: 인스턴스 타입의 함정
현상
c6i.xlarge 인스턴스가 안정 구간에서도 RPS가 기대치에 미달.
분석
- CPU 사용률 < 10 %
- 네트워크 PPS 그래프만 부하에 비례해 급등
- 전송량(Bytes) < 대역폭의 5 %
→ 병목은 CPU·대역폭이 아닌 초당 패킷 처리량(PPS)
결론
워크로드는 네트워크 집약적.
컴퓨팅 최적화(c6i) 대신 네트워크 최적화(c6in.xlarge) 가 적합.
문제 3: Node.js의 주기적인 멈춤
현상
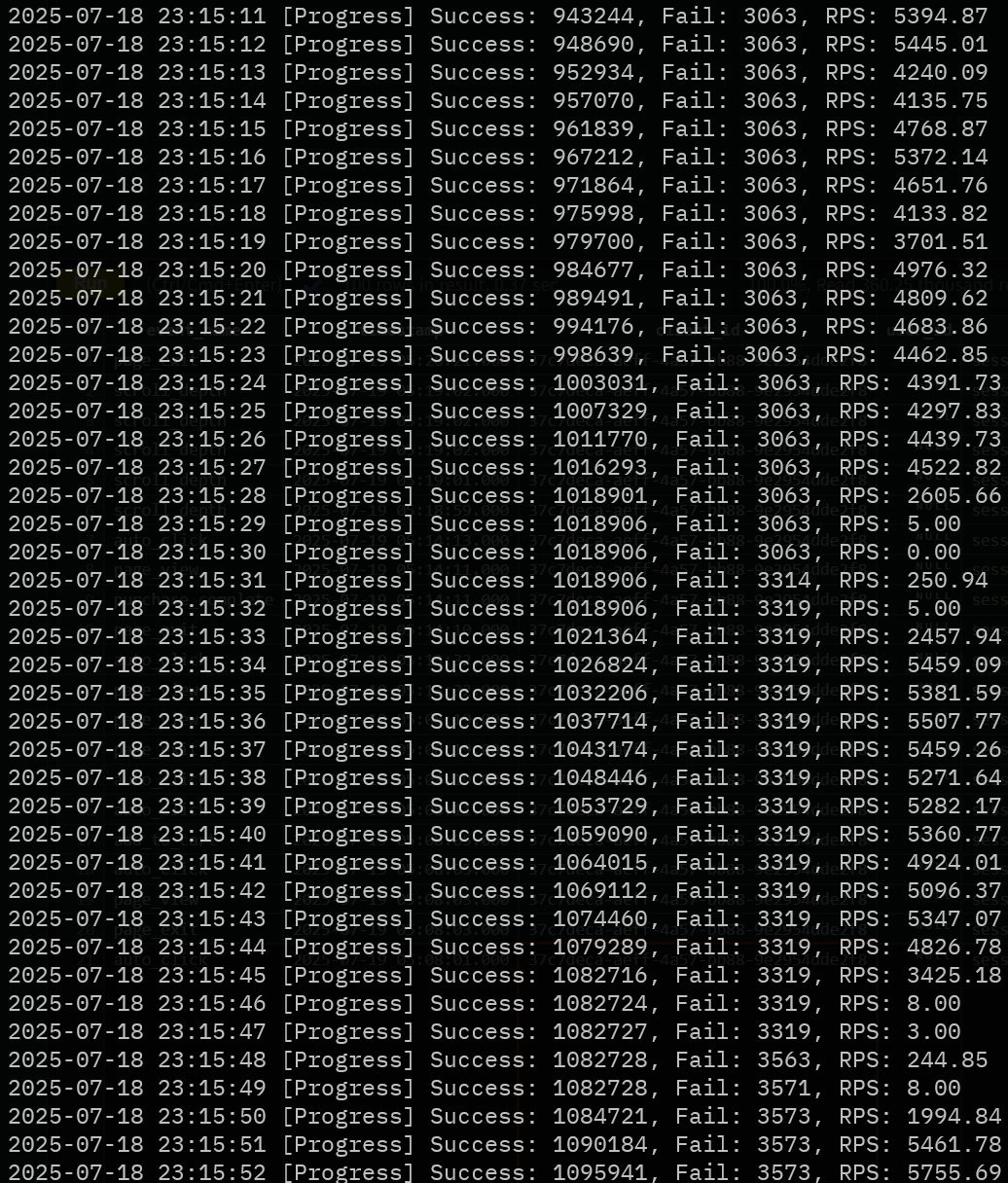
5 000 RPS 이상 유지 후 30 초~1 분 간격으로 RPS가 0 부근까지 급락·회복하는 출렁임 발생.
분석
- 인프라 한계 도달 전 발생 → 애플리케이션 원인 의심
- 패턴이 Node.js의 가비지 컬렉션(Garbage Collection, GC)에 의한 Stop-the-World 현상과 동일
- GC 동안 모든 작업 일시 정지 → 서버 응답 불능
-
메모리 축적: 초당 5,000개가 넘는 요청이 들어오면서,
Node.js 프로세스 내부에 처리 대기 중인 데이터(객체)가 메모리에 빠르게 쌓인다. -
Stop-the-World: V8 엔진(Node.js의 심장)은 메모리가 특정 한계에 도달하면,
더 이상 사용하지 않는 메모리를 정리하기 위해 모든 작업을 잠시 멈추는데 이걸 'Stop-the-World'라고 부른다. -
요청 실패: 작업이 멈춘 동안에는 들어오는 HTTP 요청에 전혀 응답할 수 없는데,
이 때문에 NLB는 서버가 죽은 것으로 판단하고,
클라이언트(phantomflow) 측에서는 타임아웃이 발생하여 실패로 기록된다.
RPS가 0으로 떨어지는 이유가 바로 이것일 것이다. -
작업 재개: 메모리 정리가 끝나면, V8 엔진은 다시 작업을 재개하고,
밀려있던 요청들을 처리하기 시작하면서 RPS가 다시 급상승한다. -
1번으로 돌아가 반복
결론 – Phase 3를 위한 과제
| 단계 | 과제 | 목적 |
|---|---|---|
| 1 | vCPU 할당량 추가 확보 | 안정적 인스턴스 운영을 위해 150 vCPU+ 로 상향 |
| 2 | 인스턴스 타입 변경 | PPS 병목 해소를 위해 프로듀서를 c6in.xlarge 로 교체 |
| 3 | Node.js 런타임 튜닝 | --max-old-space-size 로 힙 크기 확장 → GC ‘멈춤’ 완화 |
| 4 | 분산 부하 테스트 환경 구축 | AMI 기반 다수 클라이언트 동원 → 실제 50K RPS 생성 & 한계 측정 |
이 네 가지 과제를 해결하는 과정이 곧 Architectural Improvements 3가 될 것이다.
