
RPS는 왜 30초마다 바닥을 찍을까?
Node.js GC와 Stop-the-World 현상 분석
고성능 인프라를 구축하고 네트워크 최적화 인스턴스(c6in.xlarge)까지 도입했다.
이제 모든 병목이 해결됐을거라 생각했다.
그러나 부하 테스트 결과는 나의 예상을 배신했다.
1. 주기적인 RPS 급락
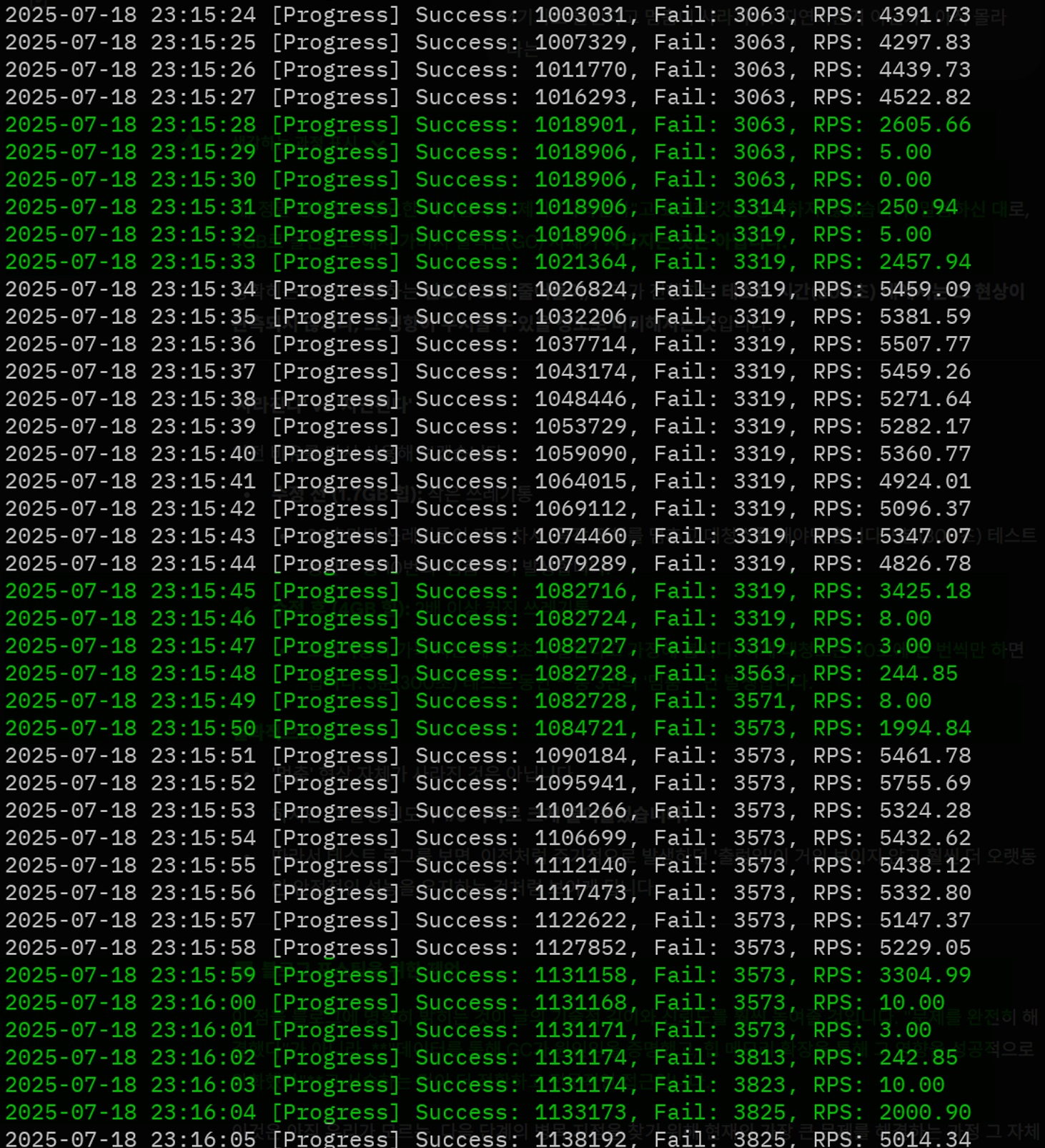
부하 테스트를 시작하면 처음 30초 정도는 깔끔했다.
RPS(초당 요청 수)가 5,000 이상을 안정적으로 유지했고 실패 요청도 없었다.
하지만 정확히 30초가 지나면 그래프가 수직 낙하했다.

2025-07-18 23:11:33 [Progress] Success: 140254, Fail: 0, RPS: 5142.74
2025-07-18 23:11:34 [Progress] Success: 143720, Fail: 0, RPS: 3465.44
2025-07-18 23:11:35 [Progress] Success: 143736, Fail: 0, RPS: 15.99
2025-07-18 23:11:36 [Progress] Success: 143741, Fail: 0, RPS: 5.00
2025-07-18 23:11:37 [Progress] Success: 143741, Fail: 235, RPS: 234.81약 30초마다 RPS가 0에 가깝게 떨어지고 실패가 발생했다.
-
인프라 자원 상태
- CPU 사용률: 10 % 미만
- 네트워크 대역폭: 한계에 한참 못 미침
-
결론: 애플리케이션 내부 문제가 의심되었다.
2. 범인은?
주기적인 ‘완전 멈춤’은 Node.js(V8 엔진)의 Stop-the-World GC 패턴과 유사하다.
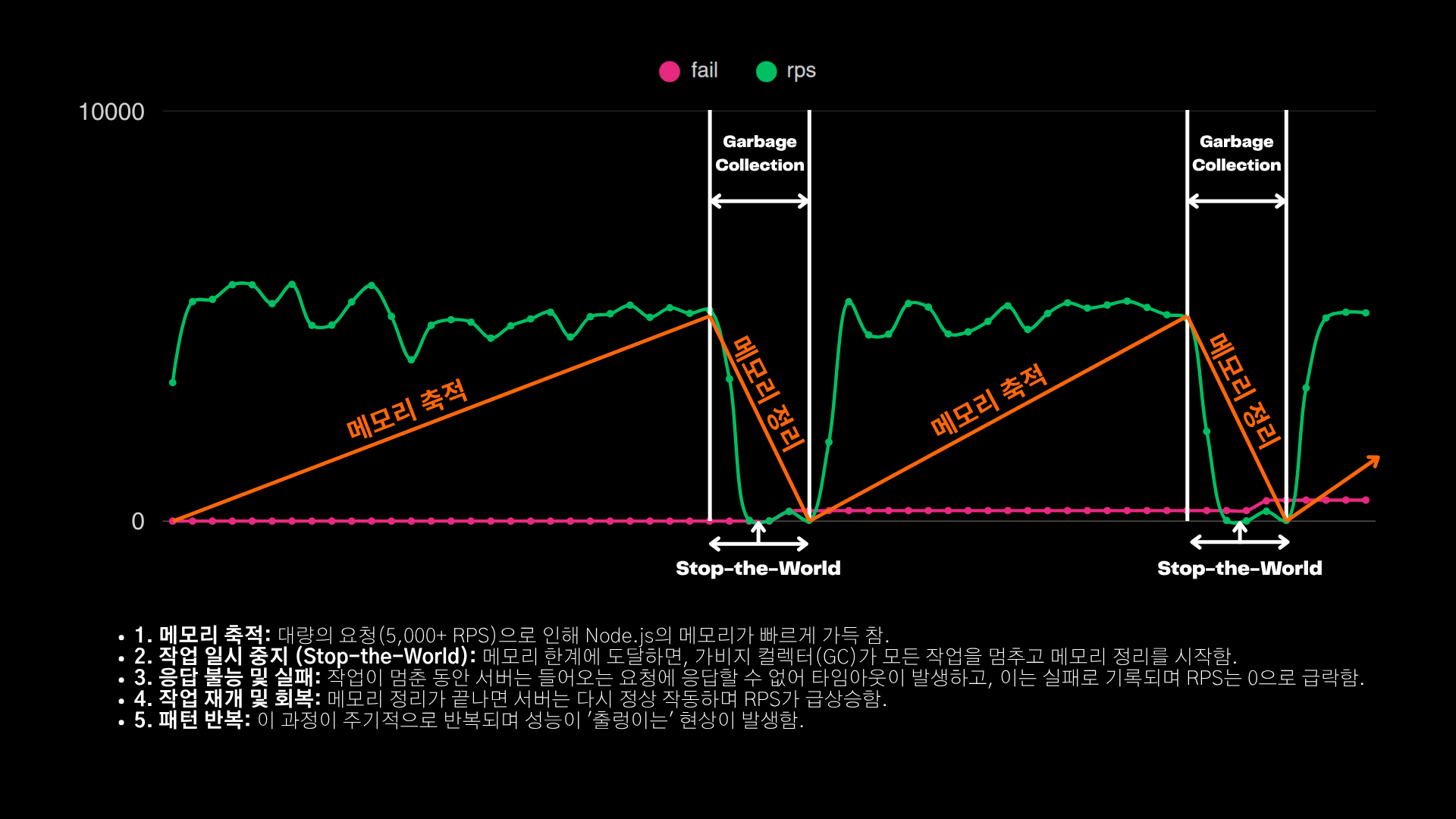
- 메모리 축적
초당 5 000 + 요청이 들어오며 객체가 힙(Heap)에 빠르게 쌓인다. - Stop-the-World
V8 엔진이 힙 한도에 도달하면 GC를 수행하기 위해 모든 애플리케이션 스레드를 일시 중단한다. - 요청 실패
수백 ms 동안 응답이 멈추며 NLB는 타임아웃을 발생시켜 실패로 기록한다. - 작업 재개
GC 완료 후 작업을 재개하면서 RPS가 다시 상승한다.
이 과정이 주기적으로 반복되며 ‘출렁임’ 현상을 만든다.
3. 검증: 왜 하필 ‘30초’였을까?
Node.js의 기본 힙 한도를 확인했다.

| 항목 | 값 |
|---|---|
| 인스턴스 사양 | c6in.xlarge (RAM 8 GB) |
| Node.js 버전 | 18.x |
| 기본 힙 한도 | 약 1.4 GB |
약 5 000 RPS 부하에서 힙 1.4 GB가 30초 만에 포화되었고,
그 순간 Stop-the-World GC가 발생했다.
데이터가 가설을 뒷받침했다.
4. 해결법 1: 힙 메모리 확장
GC 빈도를 낮추기 위해 힙 한도를 직접 확대했다.
# 수정 전: 기본 힙(≈1.4 GB)
pm2 start app.js --name klicklab-producer
# 수정 후: 힙을 4 GB로 확장
pm2 start app.js --name klicklab-producer --node-args="--max-old-space-size=4096"기대효과 :
- 전체 RAM 8 GB 중 4 GB를 할당해 OS 여유 메모리도 확보.
- GC 주기가 길어져 Stop-the-World 발생 빈도 감소.
5. 해결법 1에 대한 결과: 지연된 ‘멈춤’ 현상
수정된 템플릿을 배포해 동일 조건으로 테스트를 재실행했다.
-
30초마다 발생하던 성능 급락이 아주 조금 완화되었다.
-
달라진 점: 메모리를 4GB로 늘린 덕분에,
안정적인 구간의 최대 RPS가 6,000을 넘나들며 이전보다 확실히 향상되었다.
이는 메모리 증설이 어느 정도 효과가 있었음을 의미 -
그대로인 점: 하지만 가장 중요한 문제인 '주기적인 멈춤' 현상은 여전히 똑같이 발생.
약 20~30초간 높은 성능을 유지하다가 RPS가 급락하고 실패가 발생하는 패턴이 그대로;;
만약 GC가 유일한 원인이었다면,
메모리를 2배 이상 늘렸을 때 '멈춤' 현상이 발생하는 간격도 2배 이상으로 길어져야만 하는데...
하지만 그렇지 않았다.
해결법 2는 다음 편에 계속...
