
나만무 최종 발표 하루 전
인프라 원복 직전의 상황이다.
테스트 전용 사양으로 다운그레이드 해놓은 Kafka 브로커(t3.small)와
원래 사양(m5.large)을 정면 비교할 수 있는 단 한 번의 기회가 왔다.
이번 글은 그 실험 기록이다.
실험 배경
우리는 초당 1만 건 목표를 향해 인프라를 키워 왔다.
그러다 발표전까지 비용을 아껴야한다는 판단으로
Kafka 브로커를 m5.large → t3.small 로 내려놓았다.
원복 작업이 예정돼 있던 바로 그날 밤,
“실제로 다운사이징이 병목일까?” 를 수치로 증명하기 위해 실험을 진행했다.
이미 휴면(Scale‑in) 전 m5.large 로그는 보관해 둔 상태라서
이제 t3.small 구간만 남기면 완벽한 A/B 비교가 가능했다.
그리고 만약 다운사이징을 한 상태에서도
RPS 1만이 나온다면,
우리는 비용을 더 아낄 수 있다.
나와도 좋고, 안나오면 그걸 실험으로 증명했으니 좋은 셈이다.
실험 설계
| 구간 | Kafka 사양 | 프로듀서 (t2.small) |
|---|---|---|
| A | t3.small 3 노드 | 70 → 90 대 Step Scaling |
| B | m5.large 3 노드 | 74 대 (고정) |
결과 스크린샷
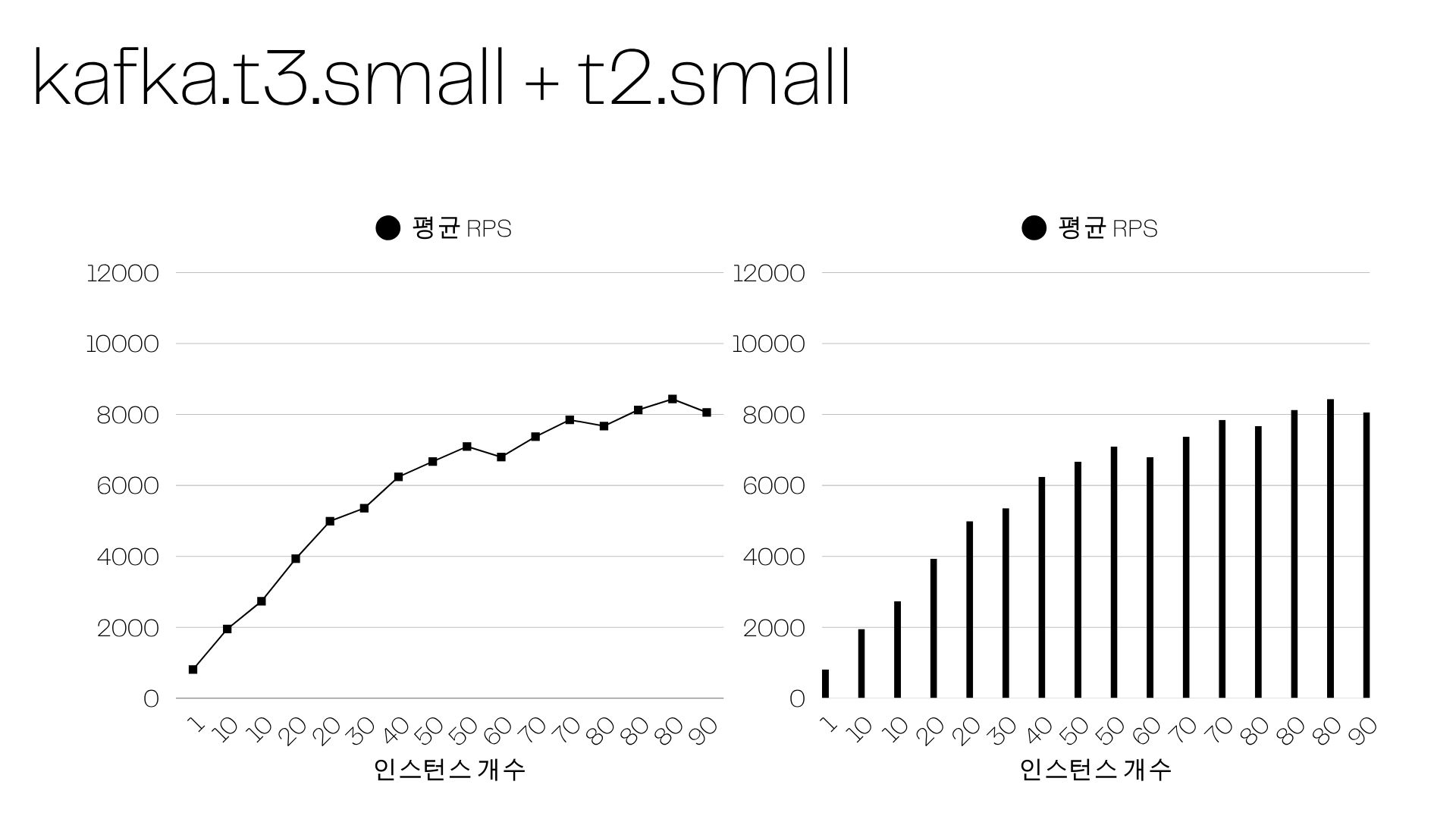
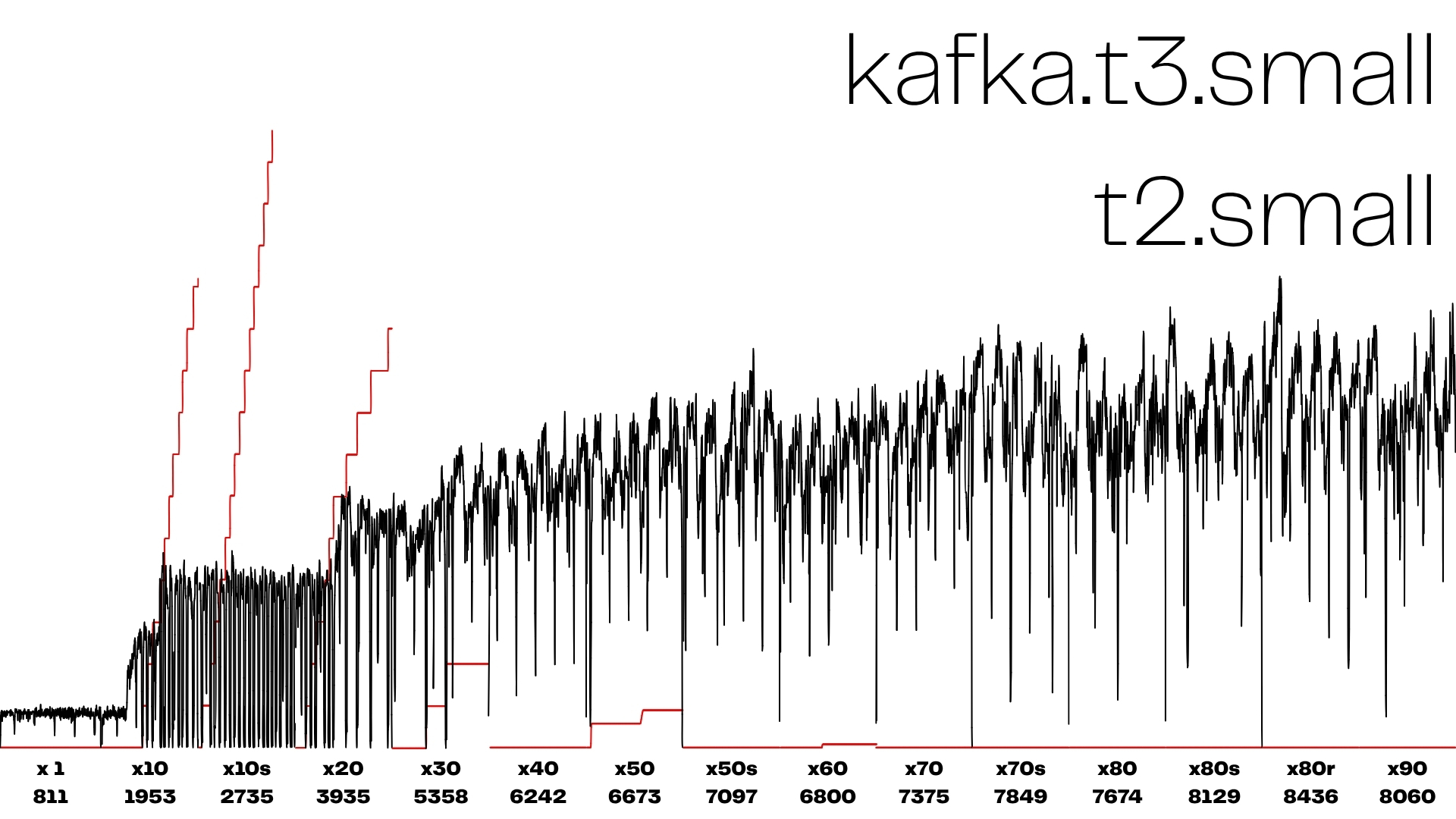
인스턴스 개수가 늘어도 카프카 병목으로 인해 평균 RPS는 더 이상 증가하지 못한다.
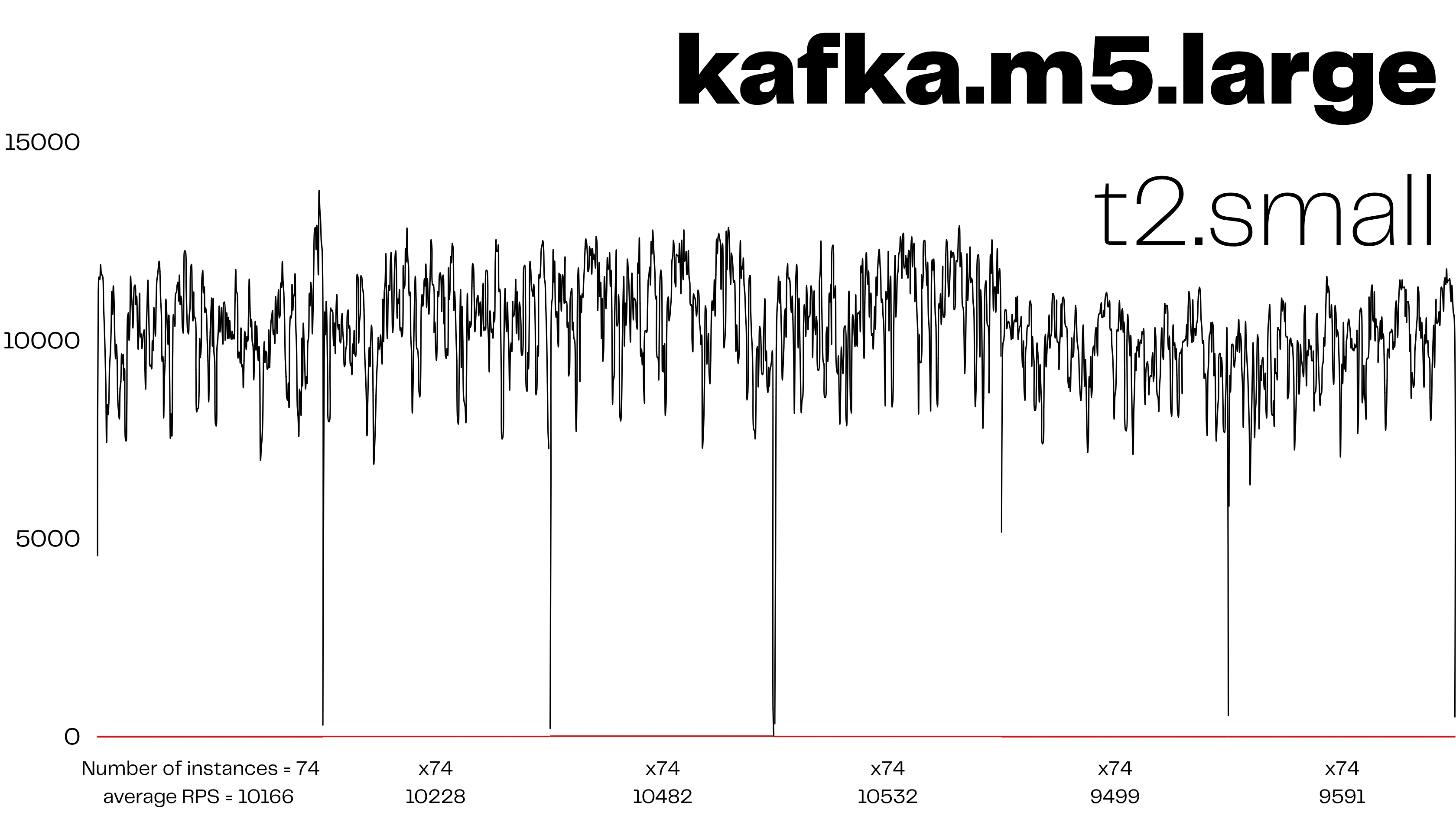
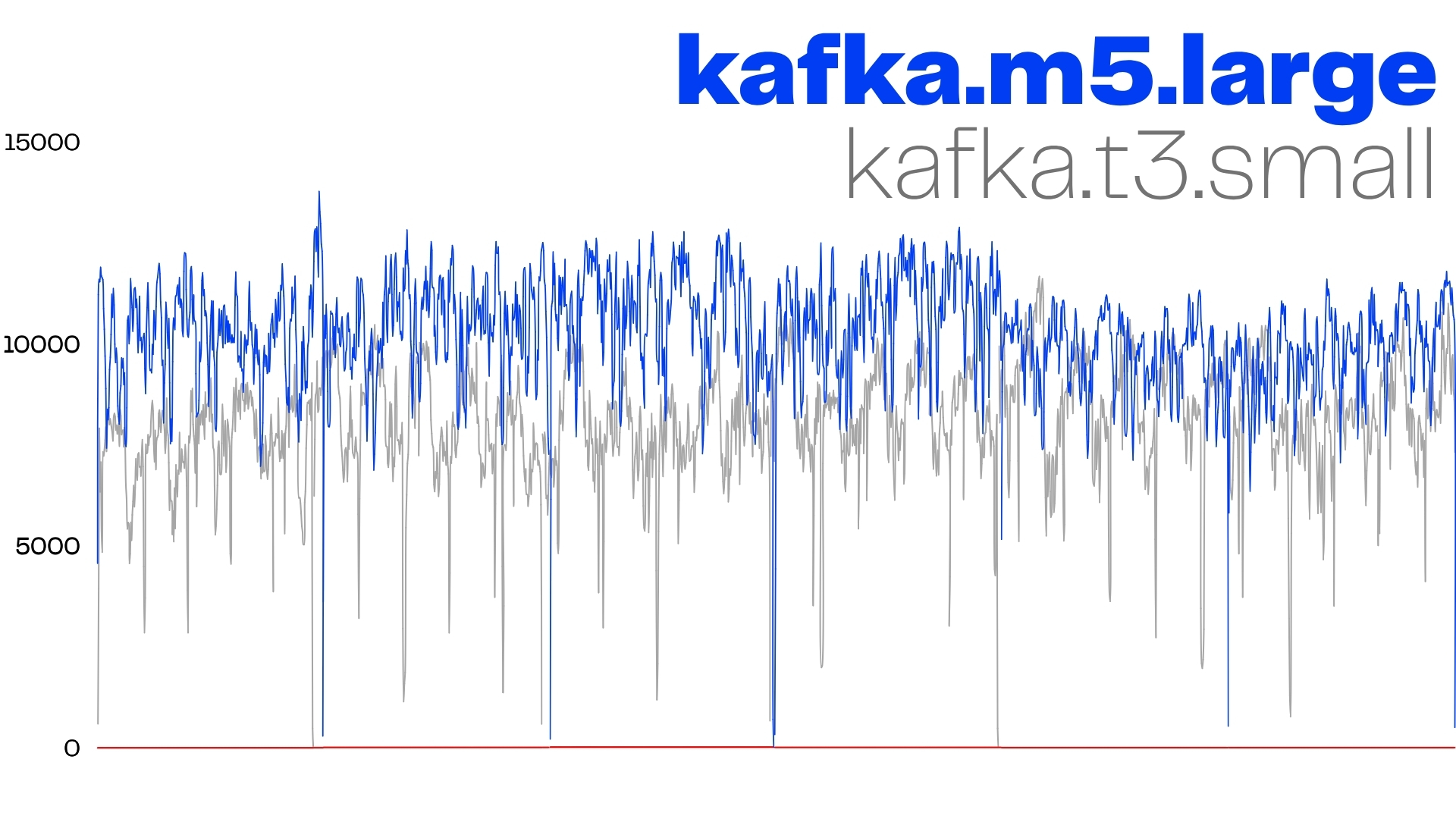
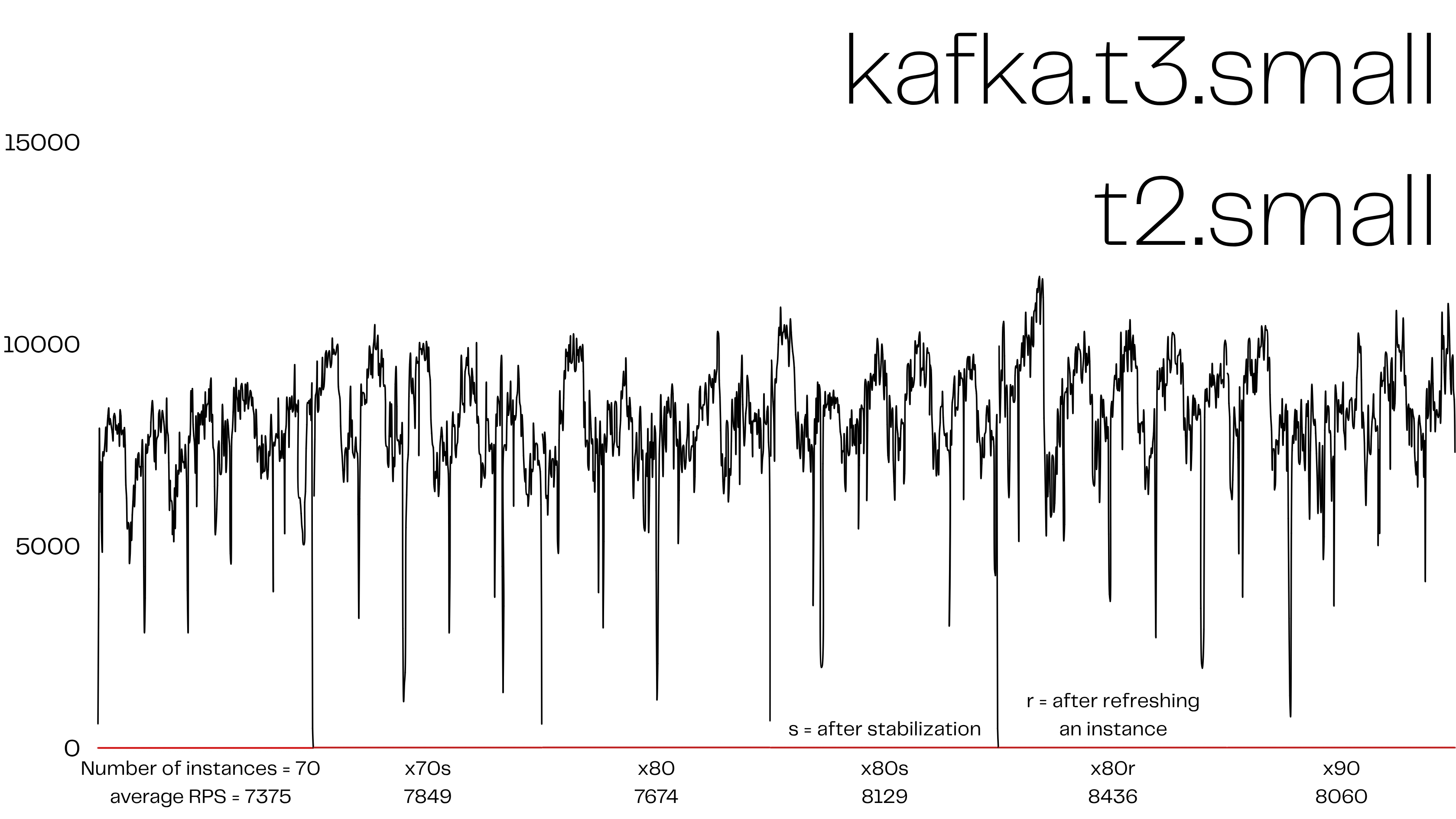
| 지표 | 구간 A (t3.small) | 구간 B (m5.large) |
|---|---|---|
| 평균 RPS | 7,375 | 10,166 |
| 최대 RPS | 10 0xx | 12 9xx |
| 딥 스파이크 빈도 | 1/40 s | 1/120 s |
+38 % 처리량, 단지 브로커 사양을 되돌렸을 뿐인데 나온 차이다.
병목의 원인은 무엇이었을까??
1. CPU 크레딧 고갈
- t3.small 은 시간당 24 크레딧. 50 대 프로듀서를 넘기면 크레딧 0 → 베이스라인 20 % 성능.
- CloudWatch
CPUCreditBalance가 0 에 붙는 순간부터 RPS 곡선이 꺾였다.
2. 메모리 & Page Cache 부족
- 2 GiB RAM → segment 파일이 캐시에 오래 머물지 못함.
- 디스크 I/O 대기 증가 →
LogFlushTimeMs급등.
3. 네트워크 / EBS Baseline 제약
- t3.small Baseline 0.5 Gbps — 리더‑팔로워 복제 + 프로듀서 트래픽으로 금세 포화.
NetworkOut대비BytesOutPerSec증가율이 눈에 띄게 눌려 있었다.
결국 CPU, 메모리, IO 세 축이 동시에 제동되어
선형 스케일이 멈추고 80 ~ 90 대 구간에서 후퇴한것으로 보인다.
결론
- 브로커를 m5.large 로 복구하는 것이 평균 처리량,안정성을 고려할 때 오히려 효율적이다.
- 다운사이징 전에는 A/B 로그 확보→ 빠른 롤백 테스트로 숫자를 남겨놓는게 좋다.
- 비싼게 좋다.
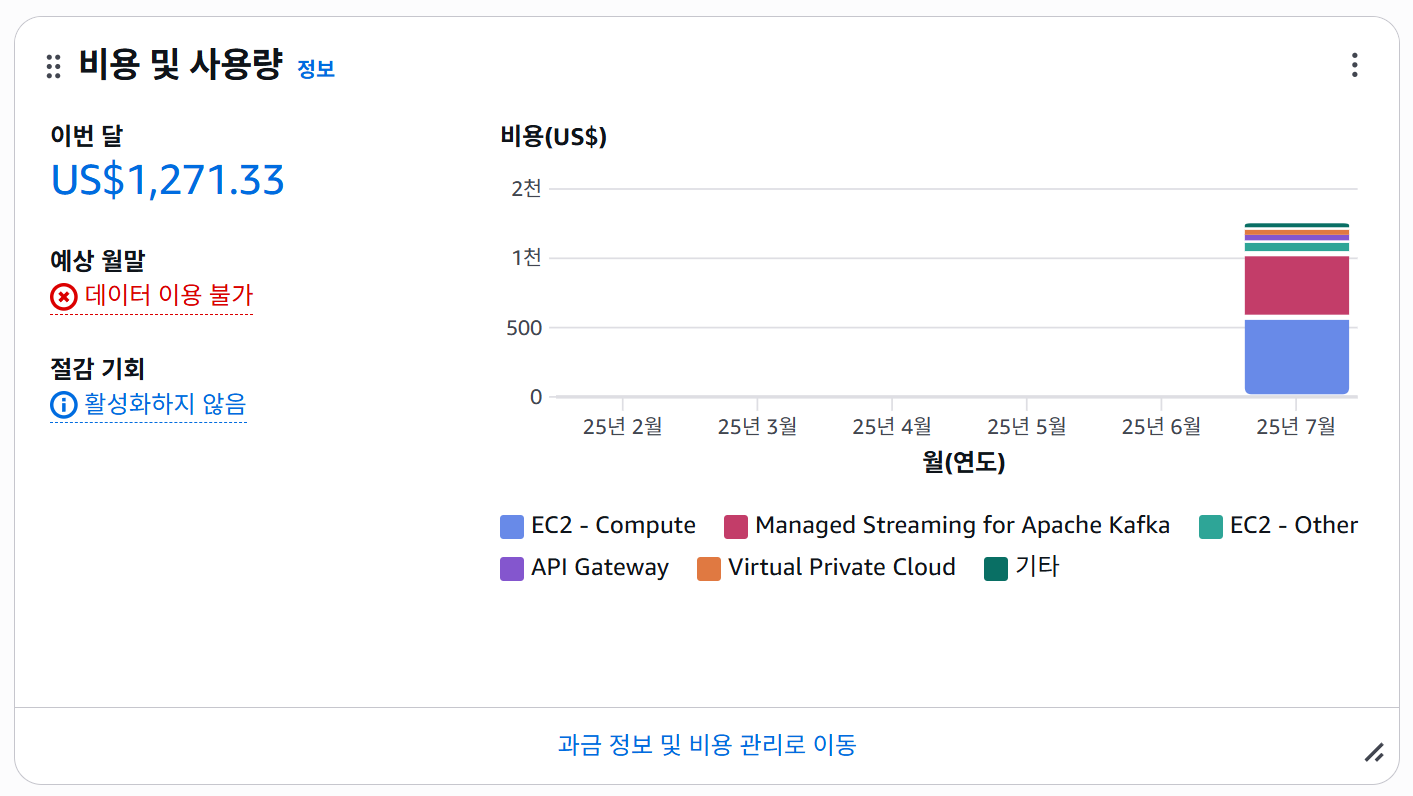 근데 진짜 비싸다.
근데 진짜 비싸다.

서툴지언정 늘 행동이 먼저이기를