
해결법 2: 인스턴스 스케일 아웃 전략 변경
힙 메모리 확장이 RPS 최고치를 높여주긴 했지만
주기적인 멈춤 현상을 해결하지 못했기 때문에...
다른 해결책을 생각해내야 했다.
만약 GC가 유일한 원인이었다면
메모리를 2배 이상 늘렸을 때
'멈춤' 현상이 발생하는 간격도 2배 이상으로 길어져야 한다.
하지만 현실은 그렇지 않았다.
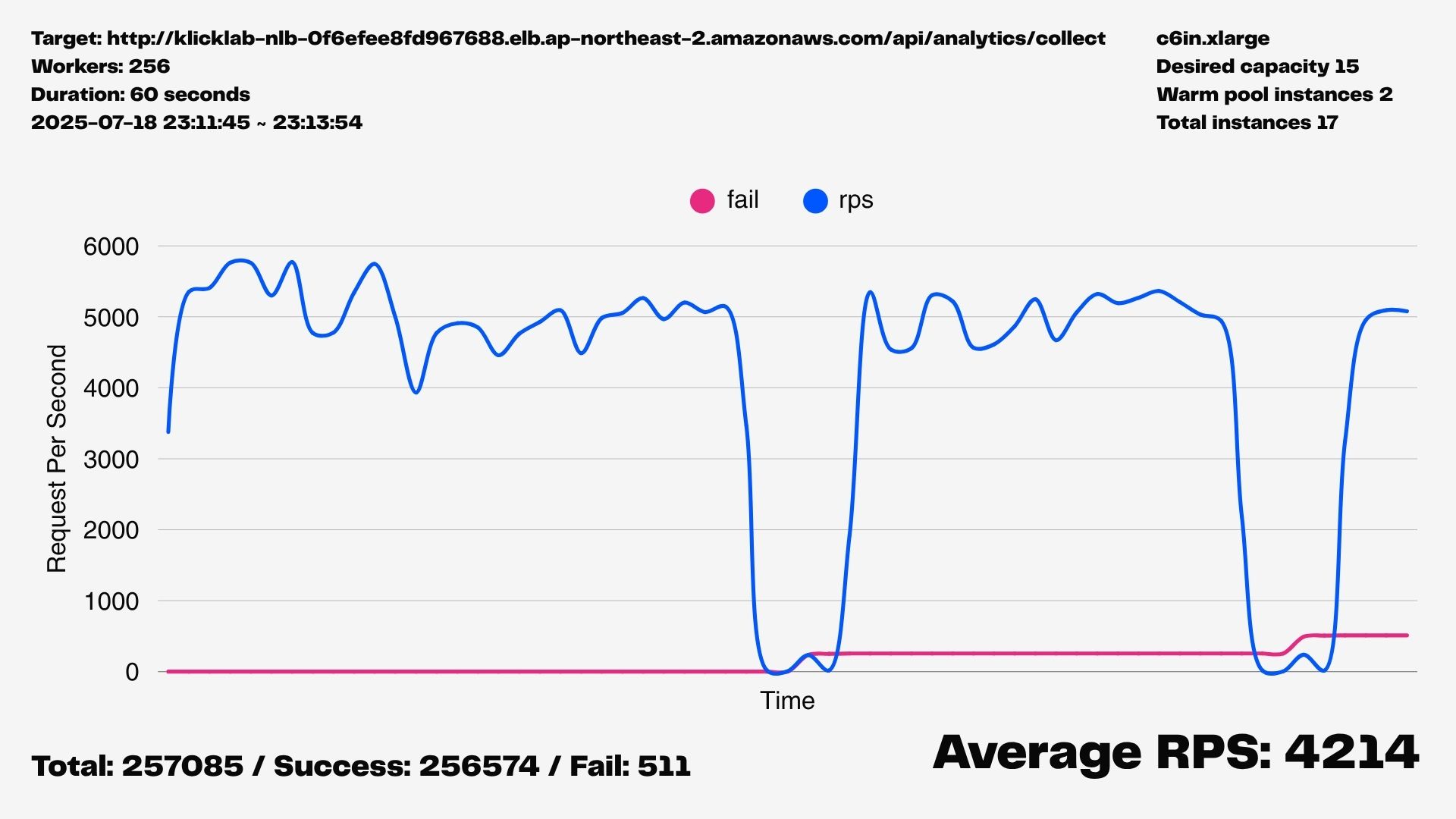
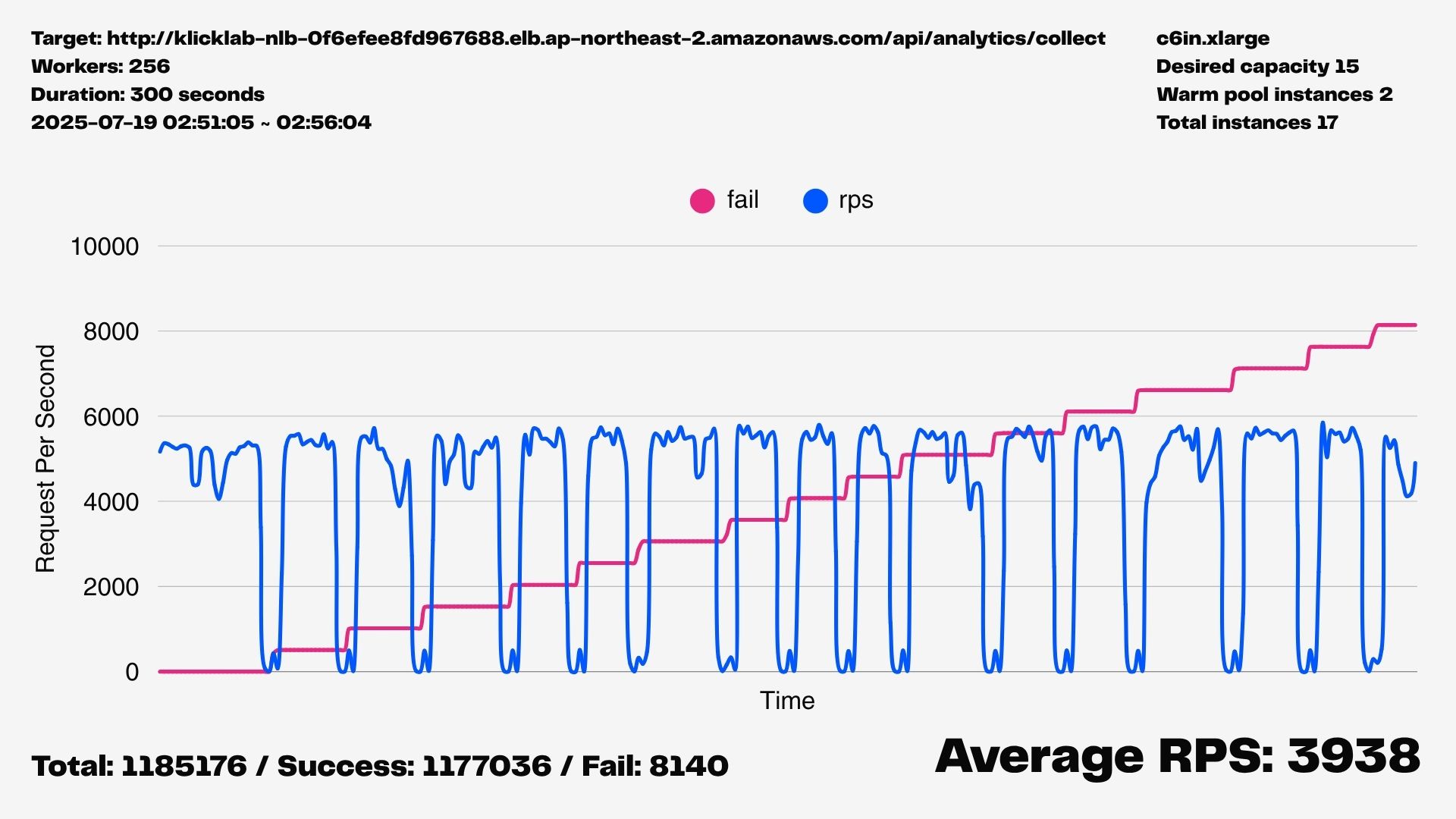
여전히 약 20~30초마다 RPS가 바닥을 찍는 현상이 반복되었다.
이 결과는 문제를 단순히 '힙 크기'의 문제가 아니라,
'단일 Node.js 프로세스'의 한계와 Stop-the-World GC가 필연적으로 발생시키는
지연 시간 그 자체에 있다는 결론으로 이어졌다.
아무리 힙을 늘려도 결국 GC는 발생하고
그때마다 모든 요청 처리가 멈춘다는 본질적인 문제는 변하지 않는다.
전략 수정
각 인스턴스가 더 적은 부하를 처리하면서 GC의 영향을 최소화하는 방법,
즉 Stop-the-World GC가 전체 서비스에 미치는 영향을 희석하는 전략이 필요했다.
인스턴스 사양 변경: 더 작게, 더 많이
기존 인프라는 고성능 네트워크와 CPU를 자랑하는
c6in.xlarge (RAM 8 GB) 17개 인스턴스로 구성되어 있었다.
쉽게 말해 좋은(비싼) 인스턴스를 적게 배치하고
각 인스턴스가 많은 요청을 처리하도록 설계된 구조였다.
하지만 Node.js의 단일 스레드 기반 특성과
GC로 인한 Stop-the-World 현상은 이 전략에 치명적인 제약이 되었다.

그래서 다음과 같이 스케일 아웃 전략을 변경했다.
- 기존:
c6in.xlarge(RAM 8 GB, 4 vCPU) 17개 - 변경:
t2.small(RAM 2 GB, 1 vCPU) 66개
파이프라인에서의 병목 지점: EC2 Auto Scaling
우리가 운영하는 파이프라인은 다음과 같다:
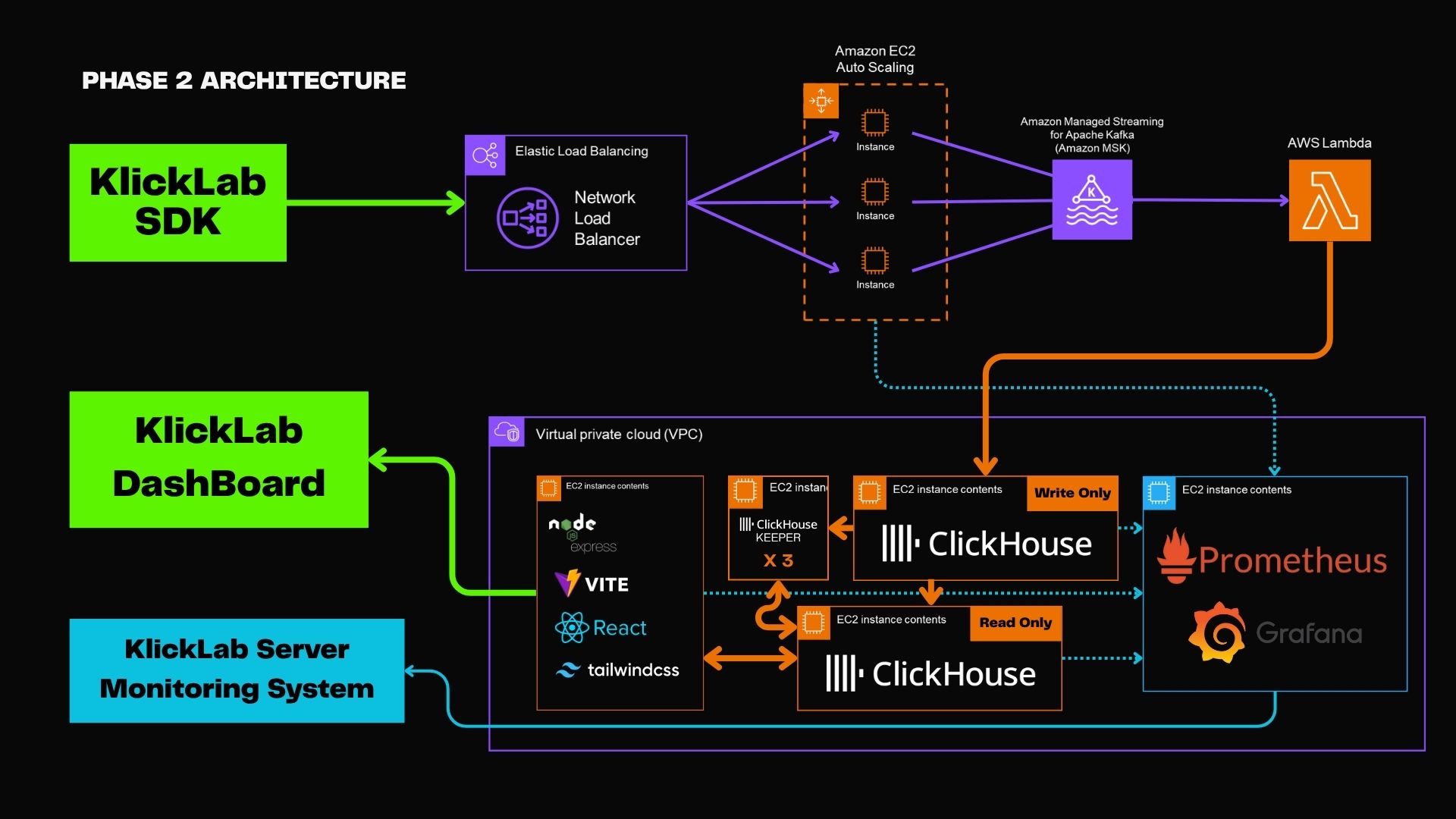
KlickLab SDK → NLB → EC2 (Auto Scaling) → Amazon MSK → AWS Lambda → ClickHouse이 중 병목 지점은 예상 밖에도 EC2 (Auto Scaling)이었다.
GC가 쌓이는 순간마다 요청이 끊기고, 전체 성능이 급락했다.
Node.js 런타임의 단일 스레드 특성과
GC가 맞물리면서 전체 파이프라인의 발목을 잡았던 것이다.
그래서 EC2 인스턴스를 잘게 쪼갰다.
그 결과, 마침내 RPS 10,000을 넘기는 데 성공했다.
할당량과 예산의 제약
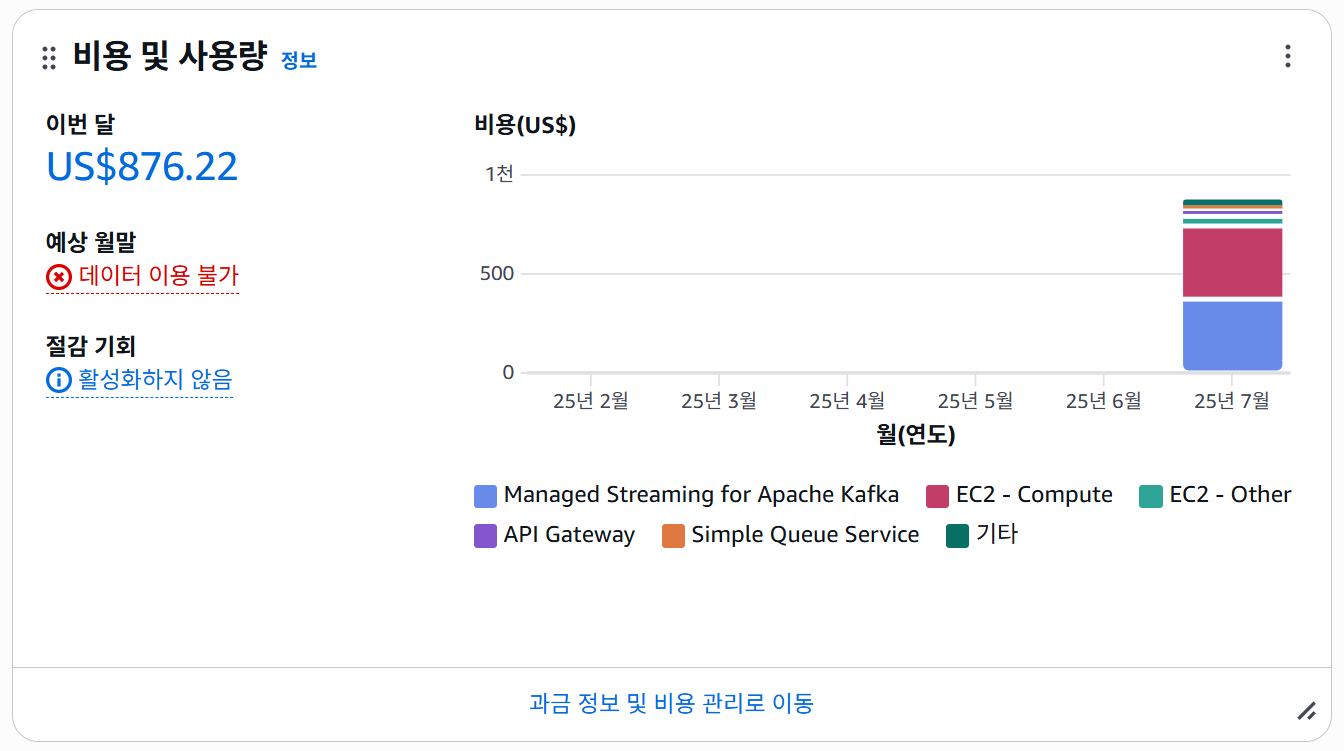
단순히 기술적인 이유만 있었던 것은 아니다.
우리는 다음과 같은 현실적인 인프라 제약에도 부딪히고 있었다:
Service Quotas에 따라 On-Demand 인스턴스의 vCPU 할당량이 96개로 제한되어 있었고,
백엔드 서버나 ClickHouse와 같은 필수 인스턴스에 이미 일부 vCPU가 할당된 상황이었다.
실제로는 사용 가능한 여유 vCPU가 74개뿐이었기 때문에
c6in.xlarge처럼 vCPU를 4개씩 사용하는 인스턴스를 계속 늘리는 것이 불가능했다.
그래서 병렬성을 극대화하기 위해
1개의 Vcpu를 가진 t2.small을 선택하여
인스턴스의 갯수를 최대한으로 늘리기로 했다.
게다가 우리에겐 AWS 크레딧 1,000달러라는 예산 한도도 존재했다.
고성능 인스턴스를 계속 쓴다면 빠르게 비용 한도를 초과할 수밖에 없는 구조였다.
결국 우리가 선택할 수 있는 전략은 명확했다.
싸고, vCPU가 적고, 비용을 예측할 수 있는 인스턴스를 많이 쓰는 것
기술적 이유와 비용 구조, 할당량 제약이 모두 맞물리며
'더 작고 많은 인스턴스' 전략이 선택된 것이다.
왜 더 작고 많은 인스턴스가 효과적일까?
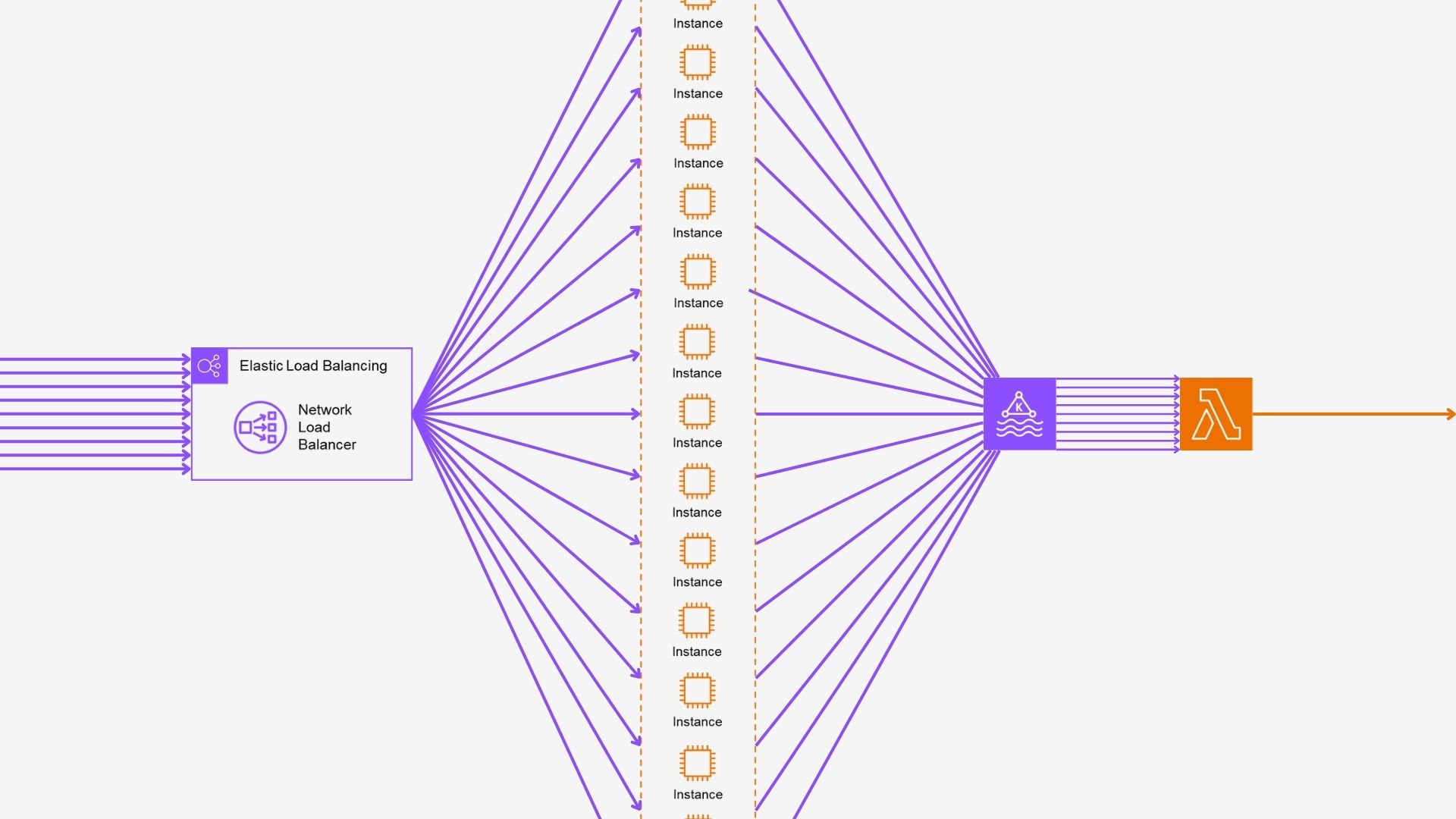
-
Stop-the-World GC의 영향 분산
t2.small인스턴스는 적은 요청을 처리하므로, GC가 발생하더라도 전체 서비스에 미치는 영향은 작다.- NLB가 요청을 분산시켜 GC 중인 인스턴스를 자동 회피할 수 있다.
-
힙 크기 대비 GC 주기 최적화
- RAM이 작기 때문에 기본 힙 크기도 작지만, 처리량 역시 적기 때문에 GC 주기도 길어지거나 GC 자체가 가볍게 끝난다.
- GC가 발생해도 해당 인스턴스에만 국한되어 전체 서비스가 멈추는 일은 없다.
-
비용 효율성
t2.small은 단가가 매우 낮다.- 인스턴스 수가 늘었지만, 비용 대비 성능 효율이 오히려 더 높아졌다.
해결 결과: RPS 10,000 달성
스케일 아웃 전략을 적용한 후 부하 테스트를 다시 실행했고, 다음과 같은 결과를 얻었다.
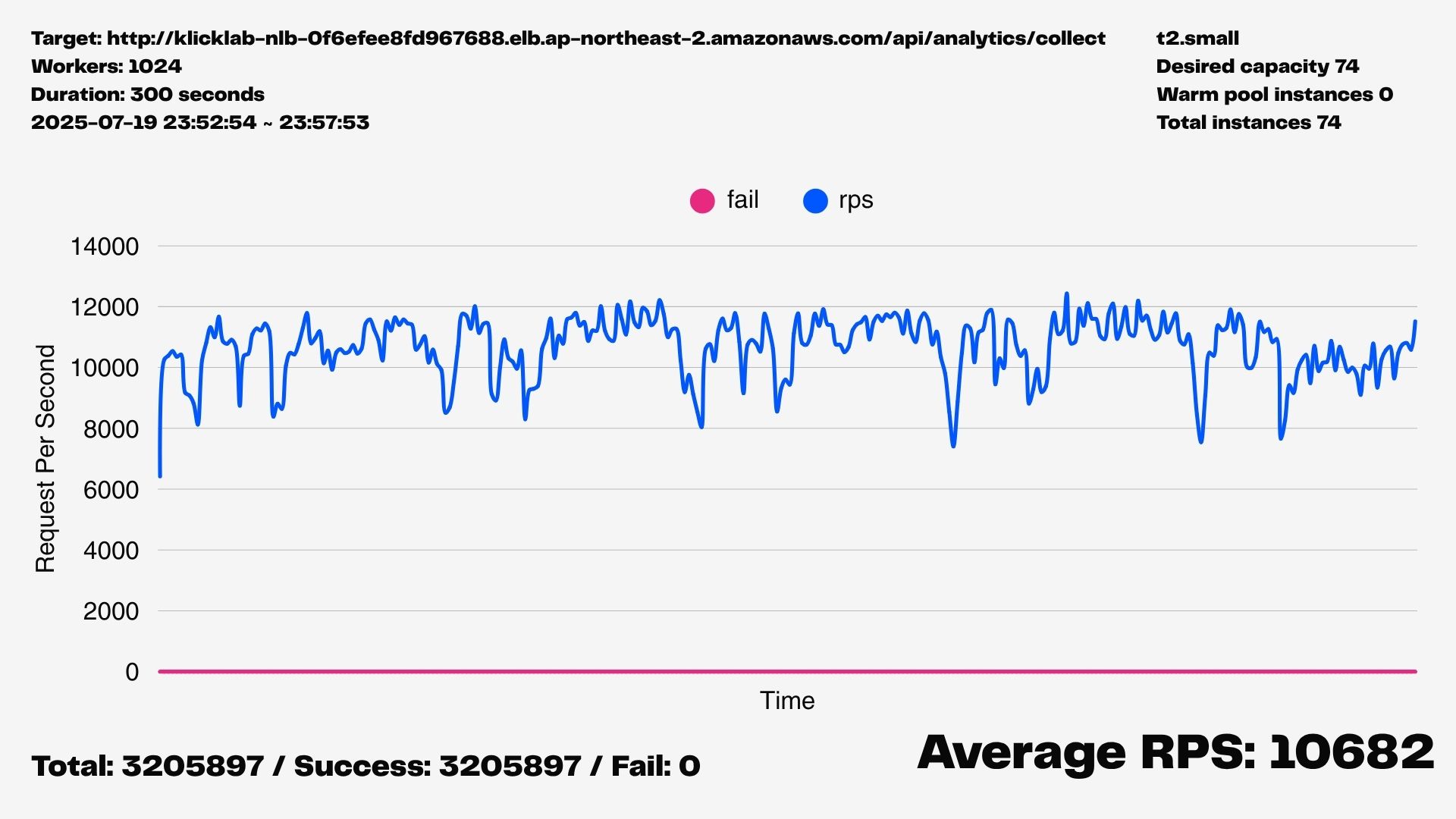
- 주기적인 RPS 급락 현상이 완전히 사라졌다
- RPS 10,000 이상을 안정적으로 유지했다
- 실패 요청은 한 건도 없었다
이 전략은 특히 Node.js처럼 단일 스레드 기반의 런타임에서 Stop-the-World GC를 분산시키는 데 매우 효과적이었다.
정리
- Node.js의 GC-Triggered Stop-the-World 현상을 파악했고,
- 두 가지 접근 방식인 힙 메모리 확장 vs. 인스턴스 스케일 아웃 전략을 비교했으며,
- "작은 인스턴스를 많이 쓰는 전략이 극적인 성능 개선을 가져왔다"는 점을 입증했다.
