
웹 스크래핑 (Web Scrapping)
웹 스크래핑(Web Scrapping) 은 위키백과를 따르면, 웹사이트에서 데이터를 추출하는데 사용되는 데이터 스크래핑이다. 웹 스크래핑은 HTTP 또는 웹 브라우저를 사용하여 World Wide Web에 직접 액세스할 수 있다. 웹 스크래핑은 소프트웨어 사용자가 수동으로 수행할 수 있지만 이 용어는 일반적으로 봇 또는 웹 크롤러를 사용하여 구현된 자동화된 프로세스를 나타낸다고 한다.
웹 스크래핑은 쉽게 말하면, 웹사이트에서 HTML을 가져와 필요한 데이터를 추출하는 기술이다.
우리들 사이에 흔히 알려진 기술은 웹 크롤링이다. 주로 빅데이터쪽에서 데이터 수집을 할 때 사용하는 것으로 알고 있다. 웹 스크래핑은 웹 크롤링과 혼용되어 사용되고 있지만, 엄연히 따지면 둘은 차이가 있다.
웹 크롤링과 웹 스크래핑
웹 크롤링 (Web Crawling) 과 웹 스크래핑 (Web Scrapping) 의 역할은 같다. 둘 다 특정 웹사이트에서 HTML을 가져와 필요한 데이터를 추출한다. 두 기술을 한 줄로 정리하자면,
웹 크롤링 (Web Crawling) : 자동화 bot (spider) 인 웹 크롤러가 정해놓은 규칙에 맞게 다수의 웹사이트에서 브라우징 (인터넷에 들어가 필요한 정보를 찾아내는 일) 하는 행위
웹 스크래핑 (Web Scrapping) : 웹사이트 상에서 원하는 위치, 필요한 특정 데이터를 추출하는 작업
웹 크롤링은 웹사이트 전체의 정보를 가져오는 것이고, 웹 스크래핑은 전체 중에 특정 데이터를 추출하는 것이다. 하지만 웹 스크래핑에서도 특정 정보를 추출하기 위해서는 웹 크롤링과 같이 웹사이트의 HTML 전체를 가져와야한다.
웹 스크래핑 사용 예시
웹 스크래핑 (웹 크롤링)을 사용하기 쉽게 하기 위한 라이브러리들이 있다. 하지만 해당 예시에서는 라이브러리를 사용하지 않는다.
여기서는 axios를 사용하고, 네이버 금융의 코스피 정보를 스크래핑 해본다. Local 환경에서 시도를 하면 CORS 문제를 마주할 수 있다. 이는 Chrome을 사용한다면, 확장 프로그램 설치로 해결할 수 있다.
✔ 먼저, 필요한 정보가 있는 웹사이트의 HTML 전체를 가져와야한다. 요청은 Restful API로 GET method를 사용한다.
axios.get('https://finance.naver.com/');✔ 해당 요청에 대한 response의 log를 확인해보면, 해당 웹페이지의 모든 정보가 담겨있다.

✔ 해당 웹페이지 HTML 정보는 request 밑에 response, response Text에서 확인을 해볼 수 있다.

✔ 해당 HTML은 엘리먼트를 만들고 그 안에 HTML을 삽입한다.
const el = document.createElement('body');
axios.get<any>('https://finance.naver.com/')
.then(res => res.request)
.then(res => res.responseText)
.then(res => {
el.innerHTML = res;
})✔ 해당 HTML에서 .queryselector()를 이용하여 className을 검색하면 데이터를 찾을 수 있다. 코스피 데이터를 가져와 본다.
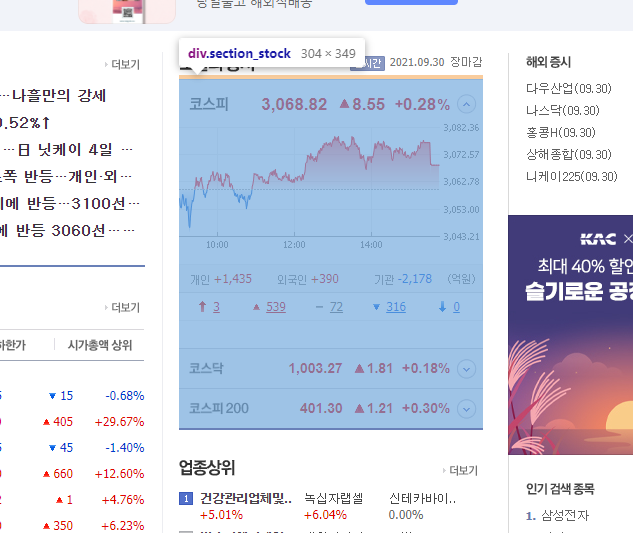
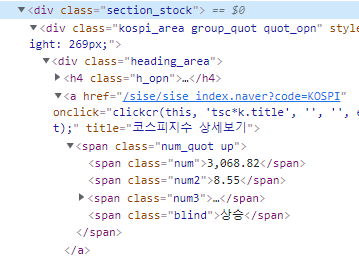
✔ 해당 코스피 정보는 정확하게 'section_stock' 밑에 'kospi_area.group_quot.quot_opn' 밑에 'heading_area' 밑에 'a' 태그 밑에 'num_quot.up'에 있다.
✔ .queryselector()를 사용하여 코스피 지수의 class까지 내려가면 오늘 날짜인 2021-09-30의 코스피 지수의 데이터를 가져올 수 있다. 아래 이미지는 log를 찍어본 결과다.
(el.querySelector(`.article > .section2 > .section_stock_market > .section_stock > .kospi_area.group_quot.quot_opn >.heading_area > a > .num_quot.up > .num`) as HTMLElement)
✔ 해당 값은 .innerText를 이용하면 태그없이 텍스트만 추출이 가능하다. 이와 같이 데이터를 추출하여 원하는 형태로 데이터를 파싱하여 사용할 수 있다.
reference: https://98yejin.github.io/2020-11-02-crawling-vs-scraping/
