1. 필수 구현 기능
동시성 제어 적용 시나리오
- 주문 시 상품 재고 감소에 대한 동시성 처리
동시성 이슈 테스트 코드
@Test
@DisplayName("여러개의 주문이 동시에 남은 재고를 구매하려 할 때")
void createOrder_concurrency_test() throws BrokenBarrierException, InterruptedException {
// given
OrderRequest orderRequest = OrderRequest.builder()
...
.build();
// 스레드 수 설정
// 배타락 테스트시 히카리 db풀 크기 -1 만큼 설정
int numberOfThreads = 21;
// 멀티 스레드 풀
// 스레드 수 * 2 권장
ExecutorService executorService = Executors.newFixedThreadPool(48);
// 동기화 제어
// CountDownLatch : latch.countDown / latch.await
// 카운트 다운이 설정한 횟수에 도달할 때 까지 정지
// CyclicBarrier : barrier.await
// 설정한 횟수만큼 await가 호출되면 한번에 실행
// 동기화 제어가 필요한 이유 : 멀티 태스크와 같은 비동기 작업들은 종료 시점을 알 수 없음
// = 호출한 함수보다 늦게 끝날 수 도 있음
CyclicBarrier barrier = new CyclicBarrier(numberOfThreads);
// 시작 시간 측정
long start = System.currentTimeMillis();
AtomicInteger executeCount = new AtomicInteger(0);
// when
for (int i = 0; i < numberOfThreads - 1; i++) {
executorService.execute(() -> {
try {
barrier.await();
orderService.createOrder(orderRequest);
executeCount.incrementAndGet();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
}
// 작업 시작점
barrier.await();
// 멀티 스레드 종료
executorService.shutdown();
// 위의 shutdown은 새로운 작업을 받지 않겠다는 뜻일 뿐
// 작업이 완료되는걸 기다려주지 않는다.(none blocking)
// awaitTermination으로 모든 작업이 끝날 때까지 블로킹 해줄 수 있다.
if (!executorService.awaitTermination(30, TimeUnit.SECONDS))
// 지정된 시간까지 완료되지 않으면 강제 종료한다.
executorService.shutdownNow();
// 종료 시간 측정
long end = System.currentTimeMillis();
System.out.println("멀티스레드 실행 횟수 : " + executeCount.get() + "실행 시간 : " + (end - start) + "ms");
// then
Product product = productRepository.findById(productId).get();
Assertions.assertEquals(80, product.getStock());
}Lettuce 를 이용해 Redis Lock 구현
lock, unlock 코드
@RequiredArgsConstructor
@Repository
public class RedisLockRepository {
private final RedisTemplate<String, String> redisTemplate;
public Boolean lock(String key, String uuid, long ttl) {
return redisTemplate
.opsForValue()
.setIfAbsent(key, uuid, Duration.ofMillis(ttl));
}
public Boolean unlock(String key, String uuid) {
// 키에 해당하는 값이 UUID와 같으면 삭제
String luaScript =
"if redis.call('GET', KEYS[1]) == ARGV[1] then return redis.call('DEL', KEYS[1]) else return 0 end";
RedisScript<Long> script = RedisScript.of(luaScript, Long.class);
Long deleteResult = redisTemplate.execute(script, Collections.singletonList(key), uuid);
return deleteResult > 0;
}
}spin lock 적용
public boolean tryLock(String key, long timeout) throws InterruptedException {
long startTime = System.currentTimeMillis();
while (System.currentTimeMillis() - startTime < timeout) {
if (redisLockRepository.lock(key))
return true;
Thread.sleep(50);
}
return false;
}Redis를 사용해 락을 구현할 때 고려해야할 것
1) Lock 획득에 실패했을 때 어떻게 할 것인가?
- spin lock을 구현해 50ms 마다
RedisTemplate를 통해 lock이 가능한지 확인하고, 정해둔 timeout 시간에 lock 획득에 실패하면 false를 반환하도록 설정했다. redisLockRepository.lock은 TTL을 5000ms로 설정해 시간이 지나면 락이 해제돼서 데드락을 방지할 수 있다.- timeout된 lock들은 최대 3회 재시도를 하고 그래도 실패할 경우 예외 처리하도록 했다.
2) Redis 를 이용해 Lock 을 구현한 이유는 무엇일까?
- 속도 자체는 배타락보다 느리지만 배타락을 걸때 생기는 커넥션 풀 이슈를 회피할 수 있다.
- 메모리 저장소라 접근 속도가 빨라 Lock 검증에 걸리는 시간이 적다.
- TTL으로 자동 해제가 가능해 메모리 관리가 편하다.
- 종합적으로 DB의 부하를 줄이기 위해 사용한다.
- 비교군으로 spring의 로컬 캐시인 caffeine이 있는데 로컬에만 적용되는 캐시라 서버가 여러대일 경우 정합성 문제가 생길 수 있다.
3) Redis 에서 Lock 을 걸때 Key 로 어떤 값을 사용했고, 왜 해당 Key 를 이용해 Lock 을 만들었을까?
- 상품의 재고에 대한 무결성이 보장되야하기 때문에 상품 아이디를 키로 사용했다.
- 추가로 멀티 스레드 환경에서 락 획득에 실패한 다른 스레드가 락을 해제할 수 있기 때문에 이를 검증하기위한 UUID를 value에 넣어 사용했다.
Lettuce를 사용해 분산 락 구현 시 발생한 이슈
-
락이 트랜잭션 내부에 있을 경우 영속화가 끝나기전에 락이 해제될 수 있다.
트랜잭션 시작
락
저장
락 해제
! << 이 틈에 다른 스레드가 들어온다면 트랜잭션이 종료되기 전에 락이 걸릴 수 있음
트랜잭션 종료 -
트랜잭션이 영속성을 db에 적용하기전에 락이 해제될 수 있다.
락
트랜잭션 시작
저장
트랜잭션 종료
락 해제
! 트랜잭션 커밋 << 락이 트랜잭션 작업 종료 후 영속성 저장을 기다려주지 않기 때문에 발생 -
멀티 스레드 환경에서 락 소유자 확인 없이 unlock을 호출하면, 다른 스레드가 소유한 락을 실수로 해제하여 정합성 문제가 발생할 수 있다.
-
스핀락을 사용할 때 타임아웃 설정이 너무 짧으면 락 획득 경쟁이 심해져 스레드가 락을 얻지 못하고 실패할 수 있다.
(테스트로 50개의 스레드를 한번에 보낼 때 timeout을 5초로 설정해야만 정상적으로 완료됐고, 그 이하로 설정 시 스레드가 락 획득에 실패해 실행되지 않았다.) -
딜레이(Time.sleep)를 짧게 설정하면 레디스에 부하가 크고 길게 설정하면 지연이 되기 때문에 적절한 시간을 설정해야한다.
2. 선택 구현 기능
Lock 을 AOP 방식으로 적용할 수 있도록 코드 리팩토링
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
public class LettuceLockAspect {
private static final String LOCK_PREFIX = "LOCK:";
private final LettuceLockService lockService;
@Around("@annotation(lettuceLock)")
public Object lettuceLock(ProceedingJoinPoint joinPoint, LettuceLock lettuceLock) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
// key 추출
EvaluationContext evaluationContext = new StandardEvaluationContext();
Object[] args = joinPoint.getArgs();
String[] paramNames = signature.getParameterNames();
for (int i = 0; i < args.length; i++) {
evaluationContext.setVariable(paramNames[i], args[i]);
}
ExpressionParser parser = new SpelExpressionParser();
String stringKey = parser.parseExpression(lettuceLock.key()).getValue(evaluationContext, String.class);
if (stringKey == null || stringKey.isBlank()) {
log.info("Key value is null or blank");
throw new IllegalArgumentException("Key value is null or blank");
}
// lock
String uniqueId = UUID.randomUUID().toString();
String lockPrefixKey = LOCK_PREFIX + stringKey;
int maxRetryCount = 3;
for (int i = 1; i <= maxRetryCount; i++) {
try {
boolean available = lockService.tryLock(lockPrefixKey, uniqueId, 4000, 50, 5000);
// 락 획득 실패
if (!available) {
log.info("{} : Retry Count{}", uniqueId, i);
continue;
}
// 락 획득 성공
log.info("프로세스 락 : {}", uniqueId);
Object result = joinPoint.proceed();
//
if (TransactionSynchronizationManager.isSynchronizationActive()) {
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
// DB 커밋 성공 후 호출
@Override
public void afterCommit() {
lockService.unlock(lockPrefixKey, uniqueId);
log.info("프로세스 언락 (트랜잭션 완료) : {}", uniqueId);
}
});
} else {
// 트랜잭션이 없는 경우 바로 언락
if (lockService.unlock(lockPrefixKey, uniqueId))
log.info("프로세스 언락 : {}", uniqueId);
}
return result;
} catch (Throwable e) {
// 트랜잭션 롤백 시 처리
if (lockService.unlock(lockPrefixKey, uniqueId))
log.info("프로세스 언락 (트랜잭션 롤백) : {}", uniqueId);
throw e;
}
}
// 재시도 3회 모두 실패 시
log.info("To many Request");
throw new IllegalArgumentException("To many Request");
}
}AOP 구현시 발생한 트랜잭션 이슈
트랜잭션이 락에 맞지 않게 실행되는 이슈
AOP Around before 시점에 락
트랜잭션 시작
영속 상태
트랜잭션 종료 및 커밋
AOP Around after 시점에 락 해제
- 위와 같은 순서로 실행될것이라 예상했지만
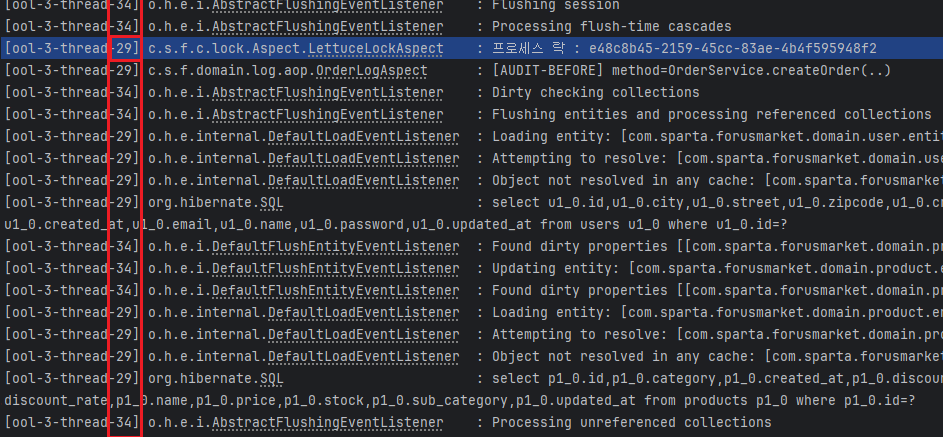
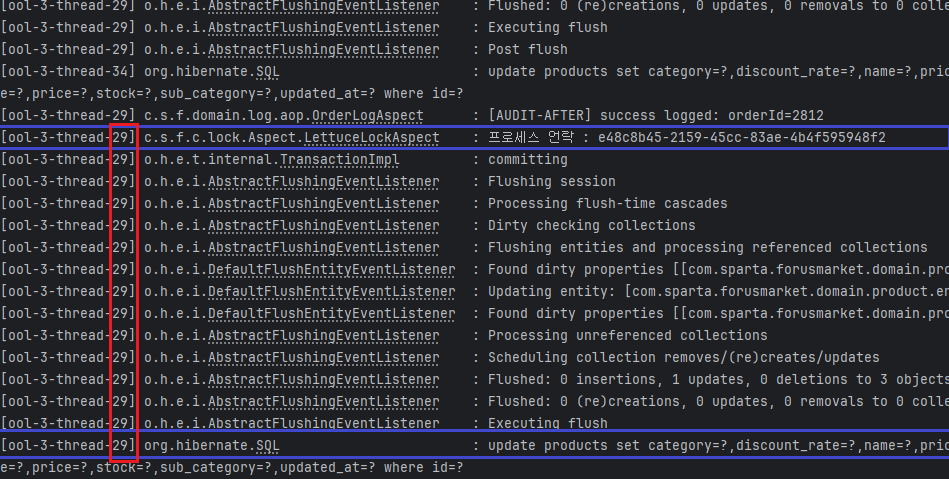
-
트랜잭션이 영속성을 DB에 저장하기 전에 락이 먼저 해제되는 문제가 발생했다.
이는 AOP가 트랜잭션이 종료되고 영속성 컨텍스트를 플러시(flush)하기 전에 스레드를 종료시키면서 finally 블록의 언락 로직이 먼저 실행되었기 때문이었다. -
이 문제를 해결하기 위해, Spring의
TransactionSynchronizationManager를 활용했다.
lock 획득 후afterCommit()콜백에 언락 로직을 등록함으로 락 해제가 DB 커밋이 완료된 후에 실행되도록 시점을 정확히 동기화하여 문제를 해결했다.
for (int i = 1; i <= maxRetryCount; i++) {
boolean available = lockService.tryLock(LockPrefixKey, uniqueId, 8000, 50, 10000);
// 락 획득 실패
if (!available) {
log.info("{} : Retry Count{}", uniqueId, i);
continue;
}
// 락 획득 성공
log.info("프로세스 락 : {}", uniqueId);
Object result = joinPoint.proceed();
// 현재 실행 중인 스레드에 트랜잭션이 활성화 돼있는지 검사
if (TransactionSynchronizationManager.isSynchronizationActive()) {
// 콜백으로 트랜잭션이 종료될 때 실행할 함수를 등록
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
@Override
// 트랜잭션 커밋 종료 후 호출
public void afterCommit() {
lockService.unlock(LockPrefixKey, uniqueId);
log.info("프로세스 언락 (트랜잭션 완료) : {}", uniqueId);
}
});
} else {
// 트랜잭션이 없는 경우 바로 언락
lockService.unlock(LockPrefixKey, uniqueId);
log.info("프로세스 언락 : {}", uniqueId);
}
lockService.unlock(LockPrefixKey, uniqueId);
return result;
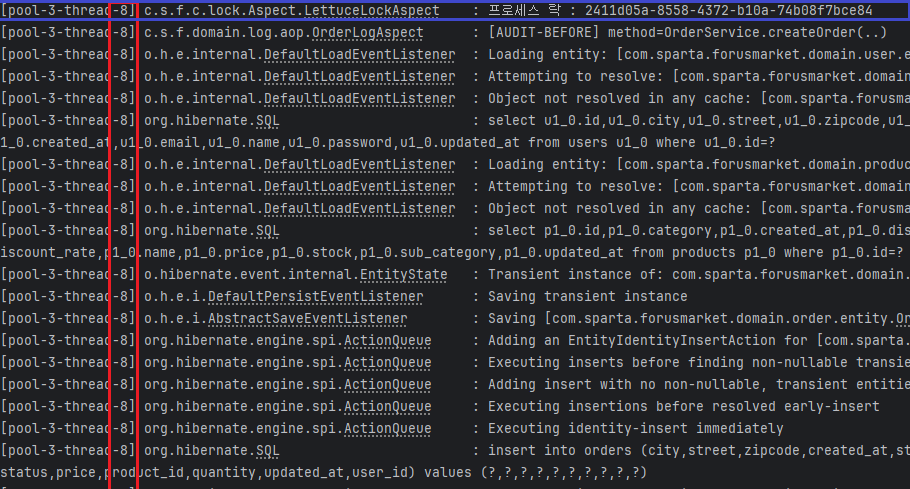
}
-
TransactionSynchronizationManager를 사용하여 unlock 시점을 DB 커밋 후로 미뤘음에도 불구하고, 테스트를 실행할 때 첫 lock이 두 번 걸리는 오류가 발생했다.
이는@TransactionalAOP와 custom lock AOP의 실행 순서 충돌로 인해, lock AOP가 트랜잭션 경계를 벗어나거나 트랜잭션이 활성화되기 전에 동기화 로직이 실행되었기 때문이었다. -
이 문제를 해결하기 위해
@Order어노테이션으로 순서를 정하는 방법과 서비스 계층의 경계를 명확하게 분리하는 방법이 있었는데 후자를 선택해서 기존OrderService는@Transactional을 유지하여 순수 DB 트랜잭션만 담당하도록 하고, 새로 구현한OrderLockService에 custom lock AOP를 달아 분산락 획득/해제만 담당하도록 했다. -
OrderLockService가OrderService를 호출하는 구조로 변경함으로써 lock 로직이 트랜잭션을 확실하게 감싸게 되었고,TransactionSynchronizationManager가 트랜잭션 활성화 상태에서 정확히 등록되어 최종적으로 데이터 정합성 문제를 해결할 수 있었다.
@Service
@RequiredArgsConstructor
public class OrderLockService {
private final OrderService orderService;
@LettuceLock(key = "#orderRequest.getProductId()")
public OrderResponse createOrderWithLettuceLock(OrderRequest orderRequest) {
// @Transaction
return orderService.createOrder(orderRequest);
}- 트랜잭션 로깅 설정
logging:
level:
org:
hibernate:
SQL: DEBUG
type: TRACE
engine:
transaction:
internal:
TransactionImpl: DEBUG
spi: TRACE
event: TRACE3. 심화 구현 기능
Redis 대신 MySQL 을 이용해 Lock 구현
낙관적 락
@Version컬럼을 통해 동시성 제어- 충돌이 적게 발생할 때 고려
- 속도가 중요할 때 (검증 로직이 없기 때문에 충돌이 없을 경우 가장 빠름)
- 충돌이 발생할 시 무결성 유지를 위해 최초로 커밋을 성공한 스레드만 데이터 베이스에 반영됨
- 처음 진입한 스레드가 version을 올리고 다음 들어온 스레드는 바뀐 version 때문에 예외처리로 롤백이 되기 때문
낙관적 락 구현
@Version Long version
@Lock(LockModeType.OPTIMISTIC)
@Query("select p from Product p where p.id = :id")
Optional<Product> findByIdWithOptimisticLock(Long id);@Retryable(
retryFor = {
OptimisticLockException.class,
ObjectOptimisticLockingFailureException.class
},
maxAttempts = 5,
backoff = @Backoff(delay = 100)
)
public OrderResponse createOderWithOptimisticLock(OrderRequest orderRequest) {
return orderService.createOrderWithOptimisticLock(orderRequest);
}
@Version을 사용해 낙관적 락 구현 시 발생한 이슈
- 동시에 같은 스레드가 낙관적 락에 접근할 시 한 개의 요청만 적용되고 나머지는 데드락 발생
비관적 락
- DB에 배타락(x-lock)을 설정해 동시성 제어
- 주로 충돌이 많이 발생할 때 고려
- 무결성이 중요할 때
- lock 때문에 DB 성능이 저하될 수 있음
- 배타락은 커넥션 풀이 중요하기 때문에
maximum-pool-size크게 설정해야 함
비관적 락 구현
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select p from Product p where p.id = :id")
Optional<Product> findByIdWithPessimistLock(Long id);배타락을 사용해 비관적 락 구현 시 발생한 이슈
// application.yml hikari cp 설정
spring:
datasource:
hikari:
maximum-pool-size: 60
// 커넥션이 풀에서 가져간 뒤 2000ms 이상 반납되지 않으면 누수로 간주
leak-detection-threshold: 2000
pool-name: MyHikariCP- 설정된
maximum pool size(기본값 10) 이상의 스레드가 접근하면 커넥션 풀에 자리가 없어서 무한히 대기하게 되며, 이 상황을 누수가 발생했다고 부른다. - 누수 발생 시 DB가 커넥션 풀의 타임아웃 시간동안
connection-timeout(기본값 30초) 정지 상태가 된다.
-maximum pool size를 10개로 설정했을때 9개의 스레드만 접근해야 정상 작동하는데 상태 변환을 위한 여유 풀이 필요하기 때문이다.
Caused by: java.sql.SQLTransientConnectionException: MyHikariCP - Connection is not available, request timed out after 30010ms (total=10, active=10, idle=0, waiting=1)
Redisson 을 이용한 Redis Lock 개발
Lettuce와의 차이점
- Lettuce
- Redis를 DB처럼 사용할때 주로 사용
- 단순 key-value 자료형의 CRUD기능
- 분산 락 필요 시 직접 구현해야 함
- 캐시에 특화
- Redisson
- 분산 락, 분산 컬렉션, 분산 서비스 등 자체 지원하는 기능들이 많음
- 기능이 많아서 무겁다는 단점이 있음
- 동시성 제어에 특화
Redisson 락 특징
- 스핀 락 방식이 아닌 pub/sub 방식 사용 (옵저버 패턴)
(lock이 해제 될 때 subscribe한 클라이언트에 알림을 보내는 방식) - 기존 스핀 락에서 지속적으로 lock 획득 요청을 보내는 과정이 사라져 부하가 줄어든다.
lock, unlock 락
- 레포지토리에 구현할 필요 없이 이미 구현돼 있는 trylock과 unlock을 사용할 수 있다.
@Service
@RequiredArgsConstructor
public class RedissonLockService {
private final RedissonClient redissonClient;
public RLock tryLock(String key, long waitTimeMs, long leaseTimeS) {
RLock lock = redissonClient.getLock(key);
try {
boolean isLocked = lock.tryLock(waitTimeMs, leaseTimeS, TimeUnit.SECONDS);
if (isLocked) {
return lock;
}
return null;
} catch (InterruptedException e) {
// 스레드 강제 종료
Thread.currentThread().interrupt();
throw new RuntimeException("lock interrupted");
}
}
public void unlock(RLock lock) {
if (lock != null && lock.isLocked() && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}AOP
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
public class RedissonLockAspect {
private static final String LOCK_PREFIX = "LOCK:";
private final RedissonLockService lockService;
@Around("@annotation(redissonLock)")
public Object lettuceLock(ProceedingJoinPoint joinPoint, RedissonLock redissonLock) throws Throwable {
// key 추출
...
// lock
// 메서드 검증을 Redisson에서 해주기 때문에 스레드 검증을 하지 않아도 된다.
String uniqueId = UUID.randomUUID().toString();
String lockPrefixKey = LOCK_PREFIX + stringKey;
RLock lock = null;
try {
lock = lockService.tryLock(
lockPrefixKey,
redissonLock.waitTimeS(),
redissonLock.leaseTimeS()
);
// 락 획득 실패 (waitTime 초과)
if (lock == null) {
throw new IllegalArgumentException("To many Request");
}
// 락 획득 성공
log.info("프로세스 락 : {}", uniqueId);
Object result = joinPoint.proceed();
if (TransactionSynchronizationManager.isSynchronizationActive()) {
RLock localLock = lock;
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
// DB 커밋 성공 후 호출
@Override
public void afterCommit() {
lockService.unlock(localLock);
log.info("프로세스 언락 (트랜잭션 완료) : {}", uniqueId);
}
});
} else {
// 트랜잭션이 없는 경우 바로 언락
lockService.unlock(lock);
log.info("프로세스 언락 : {}", uniqueId);
}
return result;
} catch (Throwable e) {
// 트랜잭션 롤백 시 처리
lockService.unlock(lock);
log.info("프로세스 언락 : {}", uniqueId);
throw e;
}
}
}락 방식 별 장단점
| 락 방식 | 권장 환경 | 장점 | 단점 |
|---|---|---|---|
| 낙관적 락 (Optimistic) | 충돌 위험 낮음 (읽기 위주) | 락 대기가 없기 때문에 빠름. | 경쟁 심화 시 DB 데드락 가능성. |
| 비관적 락 (Pessimistic) | 충돌 위험 높음 (쓰기 위주) | 높은 데이터 무결성 보장. 충돌 즉시 차단. | 심각한 DB 성능 저하 및 긴 대기 시간 유발. |
| 분산 락 (Lettuce) | 서버 분산 (경량화) | Redis 명령 직접 사용해 락 로직을 커스텀 할 수 있음. | 복잡한 구현 (Lua Script 필수). |
| 분산 락(Redisson) | 서버 분산 | 안전성 및 편의성이 높음 (Watchdog, Pub/Sub 대기). | Lettuce 단독보다 오버헤드 있음. 기능들이 많기 때문에 Redis에 부하를 줄 수 있음 |
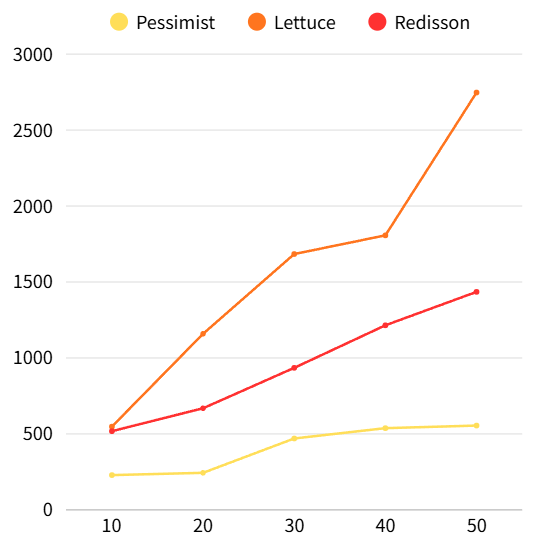
동시성 테스트 속도 비교
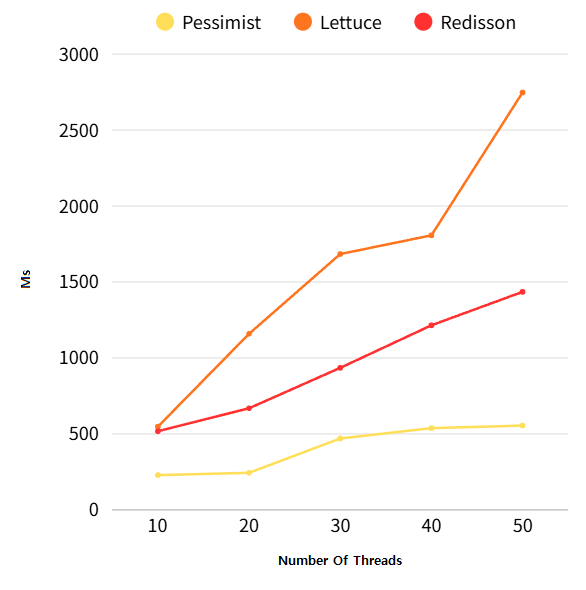
최종적으로 선택한 락
- Redisson을 이용한 분산락을 사용했습니다. 비관적 락에 비해 DB 부하가 적고, Lettuce를 활용해 Redisson의 pub/sub 방식 락과 같은 수준으로 최적화된 락을 직접 구현하기는 어렵다고 판단했기 때문에 Redisson을 선택했습니다.
