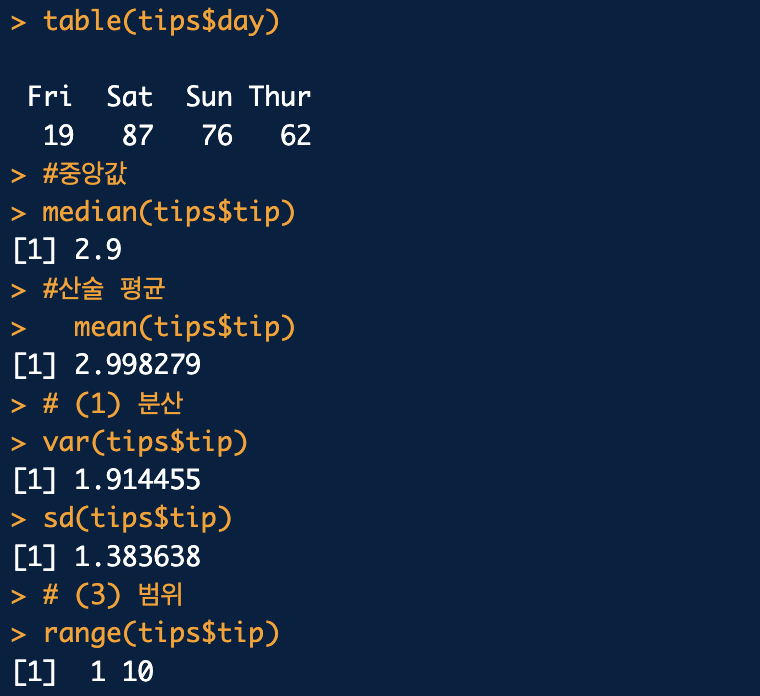
table() : 최빈수 (빈도가 가장 많은 것)
median() : 중앙값
mean() : 산술 평균
var() : 분산
sd() : 표준 편차
range() : 범위
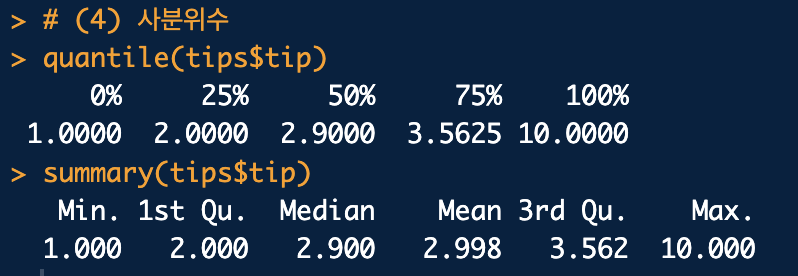
quantile(): 사분위수
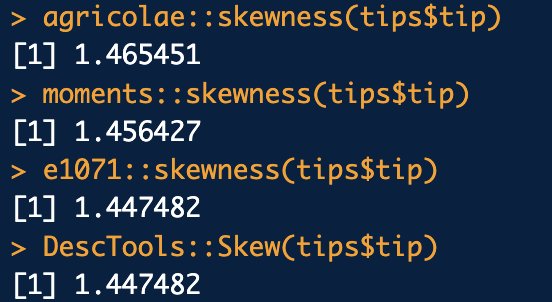
왜도
첨도
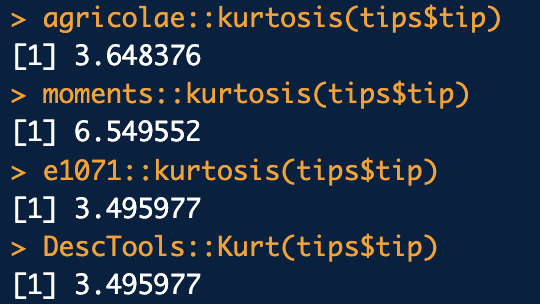
moments 3보다 큰 값이 나오는 경우 뽀죡한 형태
나머지는 첨도가 0보다 크면 값이 나오게 되면은 뽀죡한 형태
종합적인 기술통계량


trimmed -> 최댓값과 최솟값을 뺀 평균
mad -> 편차
aggregate(변수,by=list(그룹 변수들), 함수)


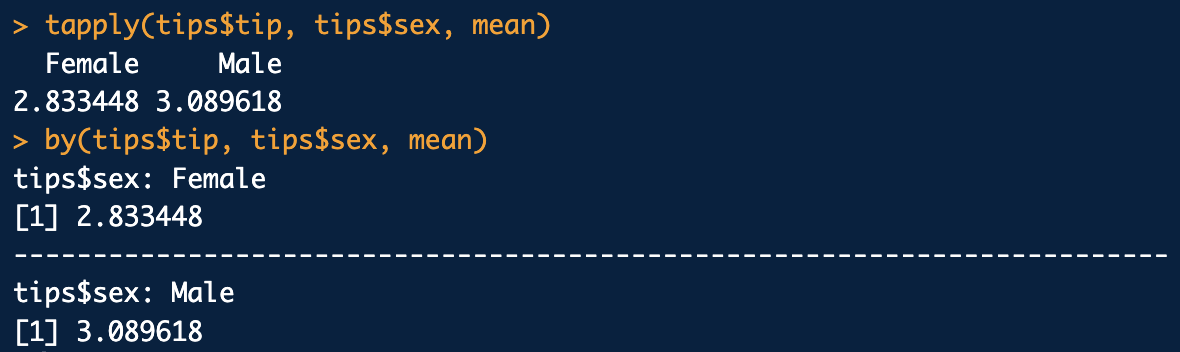
tapply(변수,그룹,함수)
by( 변수, 그룹, 함수)
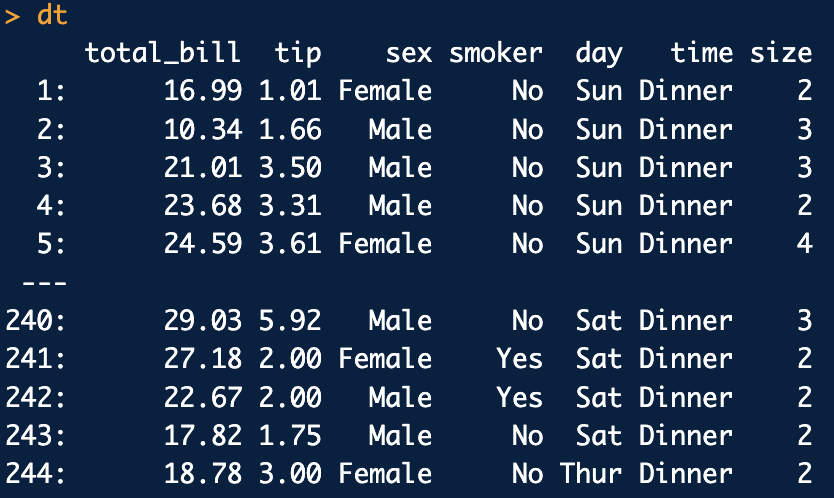
dataframe[,함수(변수),by ="그룹변수"]

그룹별 집계 방법
-
group_by()
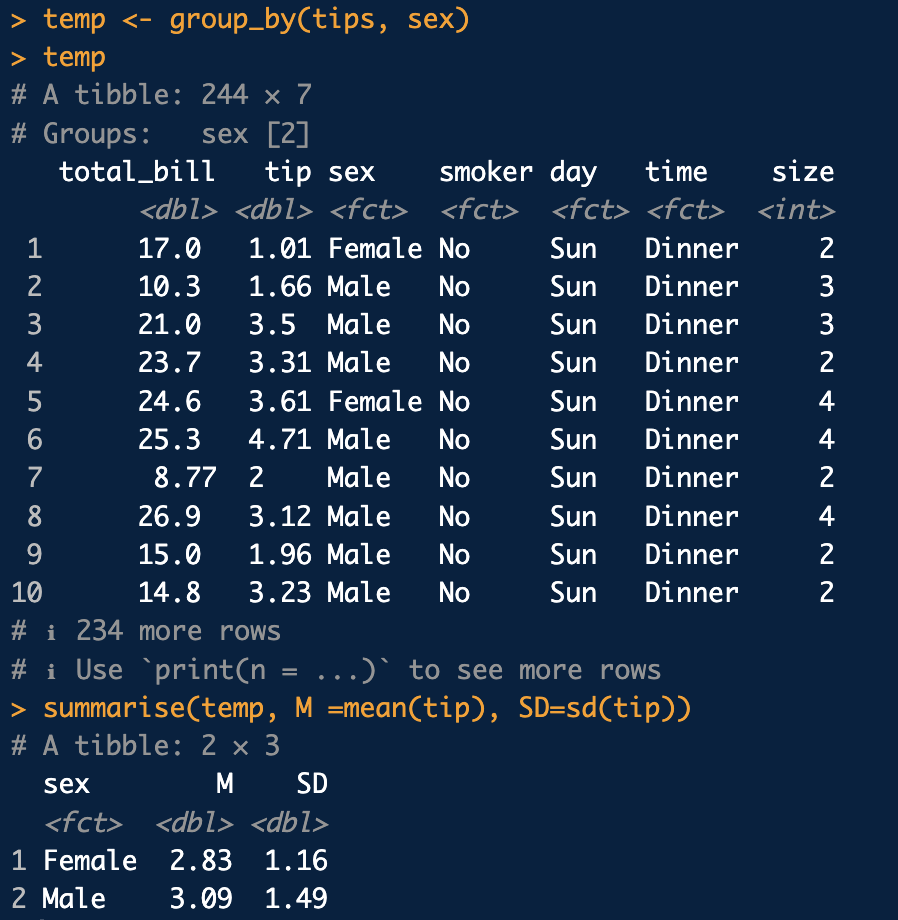
-
%>%을 활용(체인 함수)
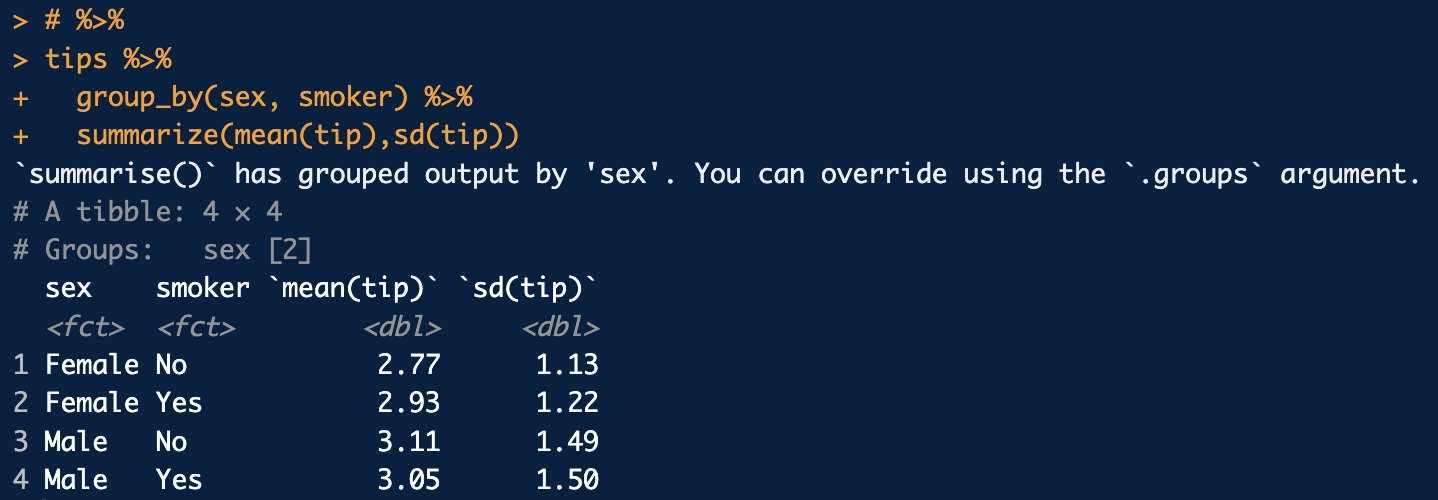
- 출처 통계청 통계교육원
