R
1.R 기초 - 스칼라 데이터

R 프로그램
2.Vector Date Type 사용법, R의 Matrix, Array 데이터 구조

단일차원(1차원)의 값을 가진 데이터를 의미합니다.동일한 데이터 유형의 스칼라 데이터들이 일률적으로 입력된 형태입니다.벤터 선언시 c() 를 선언 해줘야합니다.떨어진 값을 추출할 때는 c(,)로 표기 해야합니다.연속된 숫자일 경우 c(:)를 이용해서 가져옵니다.
3.R - Data frame 데이터 구조

R에서 사용되는 데이터 구조 중 가장 많이 사용하는 자료구조는 데이터프레임입니다. 데이터프레임은 각 변수별로 다른 유형을 가질 수 있습니다. 데이터프레임 자료형은 data.frame()함수를 이용하여 선언합니다. c() 벡터를 선언해서 데이터 프레임을 만들어보겠습니
4.List데이터에서 데이터 추출
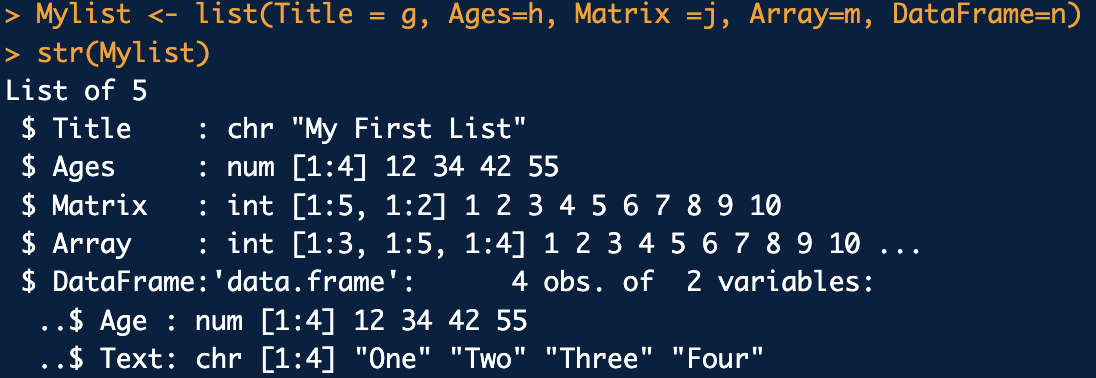
List Data는 모든 데이터유형의 데이터구조를 원소로 가질 수 있음List Data는 list()함수를 이용하여 선언 할 수 있음List를 만들어 보겠습니다.문자열과, 벡터, matrix, array, data.frame으로 배웠던 데이터 구조를 써서 만들었습니다.
5.데이터 입출력하기

getwd() :작업폴더 경로 확인setwd() : 작업폴더 지정list.files() : 폴더 안에 있는 파일을 알아보고자 하는 명령readLines() : 텍스트 파일을 읽을 때 사용하는 명령아이브 Kitsch 가사 앞부분을 가져와서 읽어봤습니다!택스트 파일은 문자
6.R - data.table
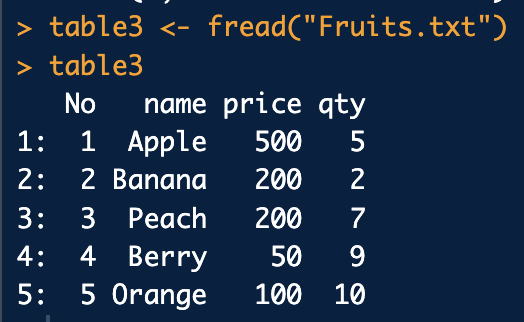
데이터프레임 형식을 확장시킨 데이터 구조속도가 빨라 데이터를 읽고 쓰는데에 큰 장점을 가짐read.table()함수를 사용하여 파일 읽음header = TRUE/FALSE첫 번째 행의 문자를 변수명으로 설정할지의 여부를 결정header = TRUE: 첫 번째 행의 문자
7.R - 기타유형의 데이터 입출력
R프로그램의 단점: 메모리 관리, 연산 속도, 코드의 효율성 문제대용량을 이용한 작업의 경우 R은 모든 연산을 메모리에 올려두고 실행하기 때문에 메모리 및 연산량 문제로 R studio가 종료되는 경우가 발생합니다.강제종료가 되면 작업하던 데이터들이 모두 메모리에서 삭
8.R - 조건문

조건에 따라 특정 명령을 실행하도록 하는 프로그래밍 명령문입니다.조건에 따라 다른 수행을 해야 하는 경우에 사용합니다.if(조건1){명령문1}else{명령문2}if 다음의 {} -> 조건이 참일 경우에만 실행할 명령문을 적음ELSE 뒤에 {} -> 조건이 거짓일 경우에
9.R - 반복문
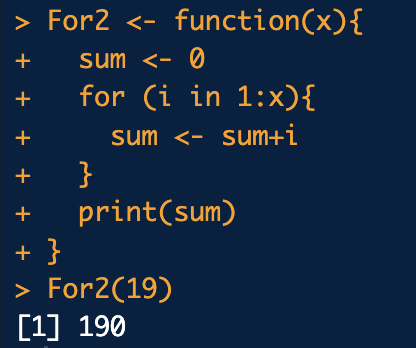
벡터,리스트,데이터프레임에 들어 있는 요소의 값에 접근할 때 반복문을 사용합니다.R함수 대부분은 벡테화 되어 있습니다. 각 요소에 대해서 연산을 수행하도록 로프를 돌릴 필요없이 함수가 벡터 모든 요소에 대해서 연산작업을 수행하도록 구성되어 있습니다.for(변수 in 횟
10.R - 데이터 전처리
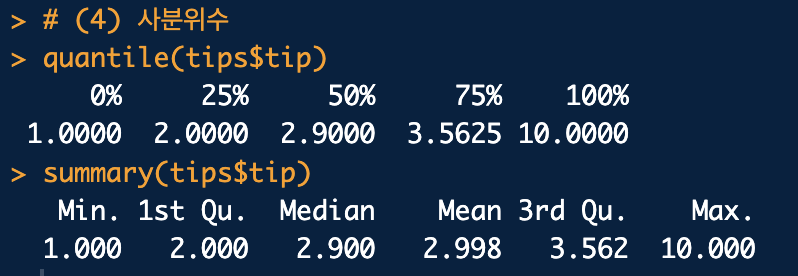
table() : 최빈수 (빈도가 가장 많은 것)median() : 중앙값mean() : 산술 평균var() : 분산sd() : 표준 편차range() : 범위quantile(): 사분위수
11.R - 특정 변수 선택
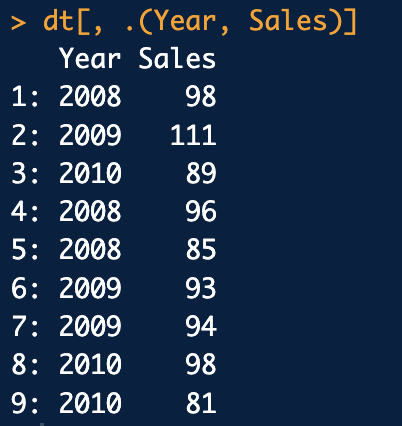
. : 변수이름을 적을때\-! : 특정한 변수 제거.. : 편집한 변수를 특정변수명으로 넣어서 인용할 때dplyr 사용%>% 사용
12.R - 데이터 전처리
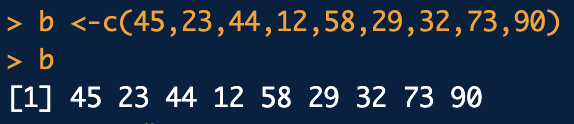
decreasing 내림차순order() : 오름차순으로 정렬된 index를 출력합니다.
13.R - 데이터 전처리 (2)
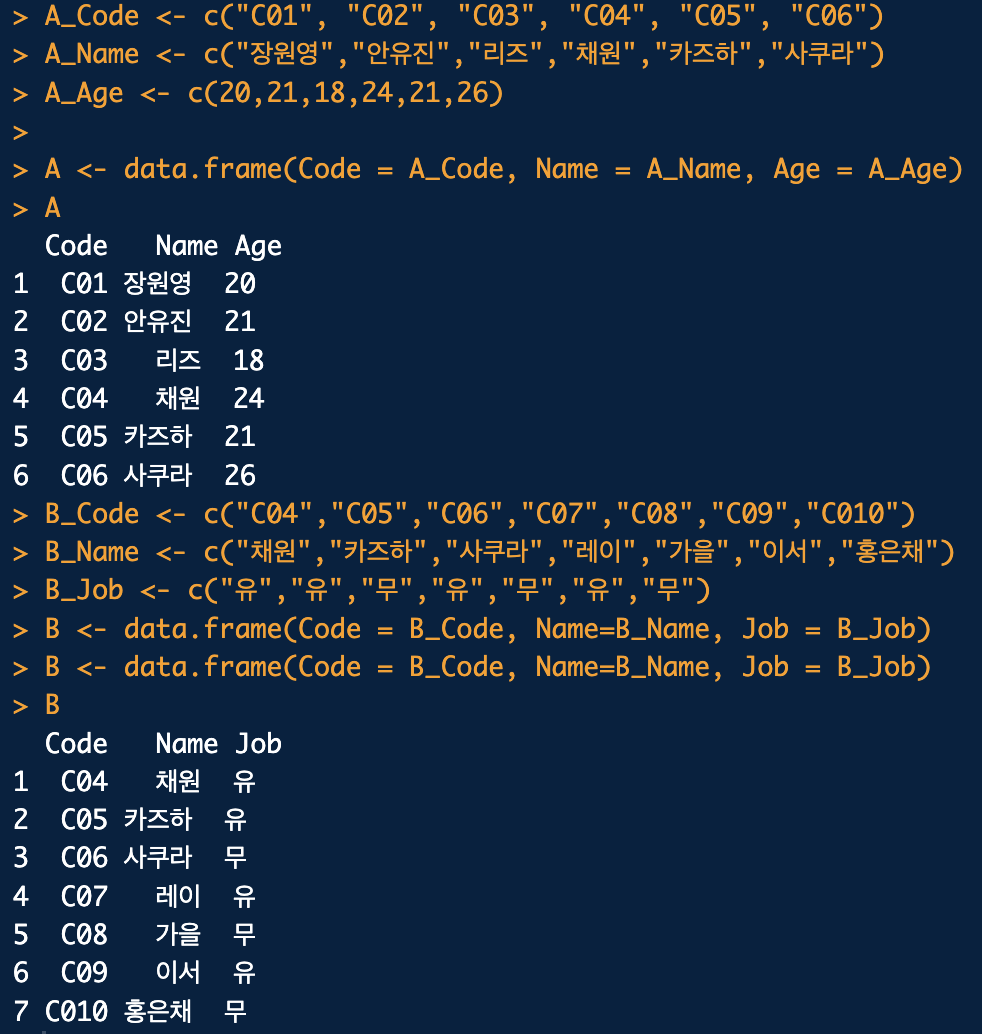
Inner Join : A와 B 중에서 공통적으로 있는 것들을 join하는 방법입니다. (교집합)Outer Join : A와 B 모두 있는 부분들을 다 확인해서 AB를 만드 방법입니다.Left Outer Join : 왼쪽 기준, A를 기준으로 해서 B와 겹치는 부분이
14.R-전처리 (3)

데이터 그룹 변경하기 결측치 데이터를 확인하여 대체하는 방법 is.na 함수 : NA인 데이터가 있으면 T, 없으면 F로 나타낸다 na.omit 함수 :NA인 데이터를 제거
15.R- 데이터 시각화
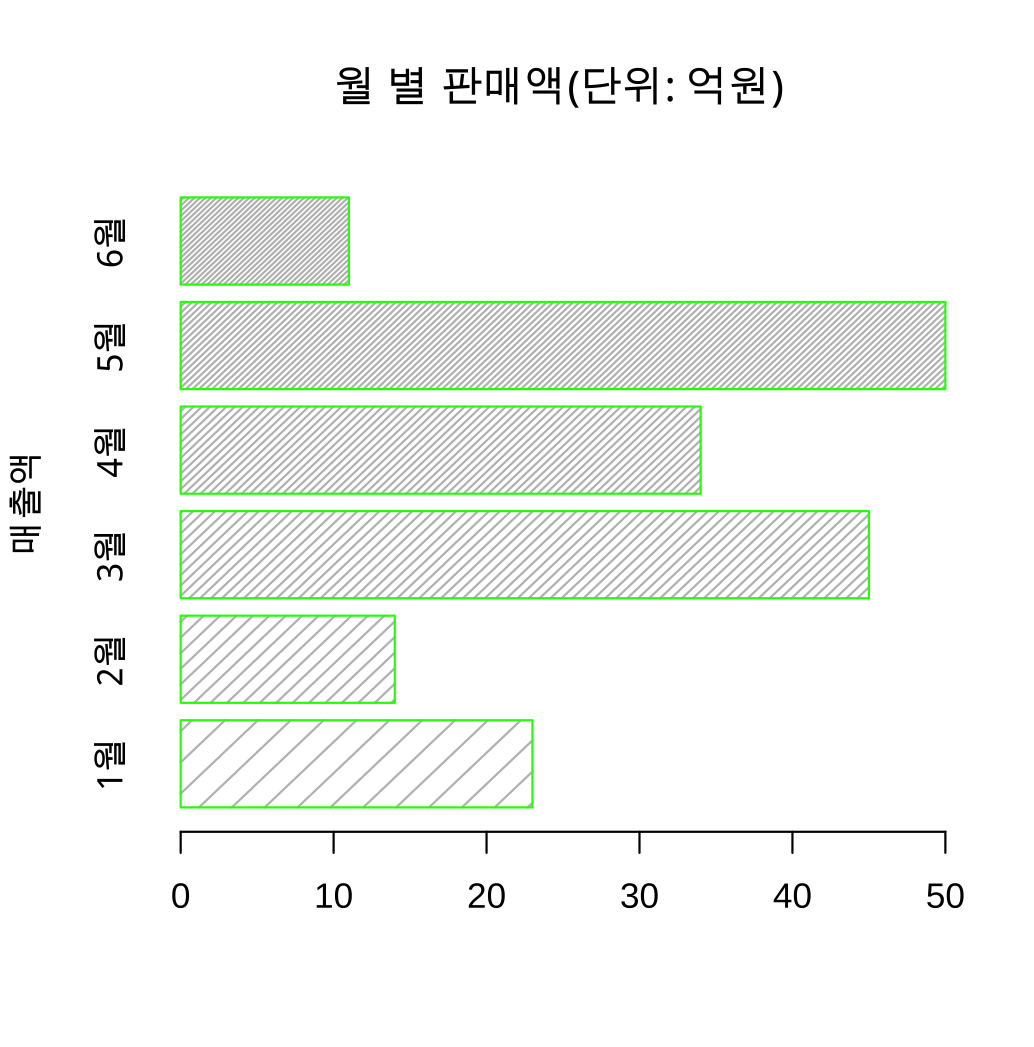
크게 작도함수와 작도디바이스 이용해서 그래프 작성작도함수 : 그래프를 출력하는 함수,작도 디바이스 : 그래프를 출력하는 함수 R스튜디오에서 plot창 통해서 출력고수준의 작도함수하나의 완성된 그래프를 그림plot() -> 산점도, hist() -> 히스토그램저수준의 작
16.R
통계학에서 자료를 연구하는 방법자료수집 -> 자료 요약 -> 자료 분석 -> 요약 결론모집단(Population) : 조사대상 전체 집단표본(Sample) : 모집단의 일부(부분집합)표본단위(Sampling Unit) : 표본을 구성하는 객체 하나하나표본추출(Sampl
17.R- 범주형 자료 요약
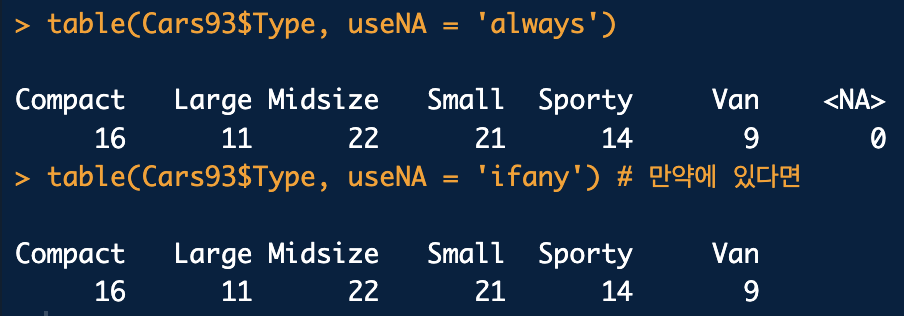
범주형 자료 요약하기범주형 자료를 표나 그래프로 요약하기범주형 자료 = 명목척도 + 순서척도도수분포표barplot(table(Cars93$Type), main = 'barplot of Type')pie(table(Cars93$Type))
18.R - 정규분포
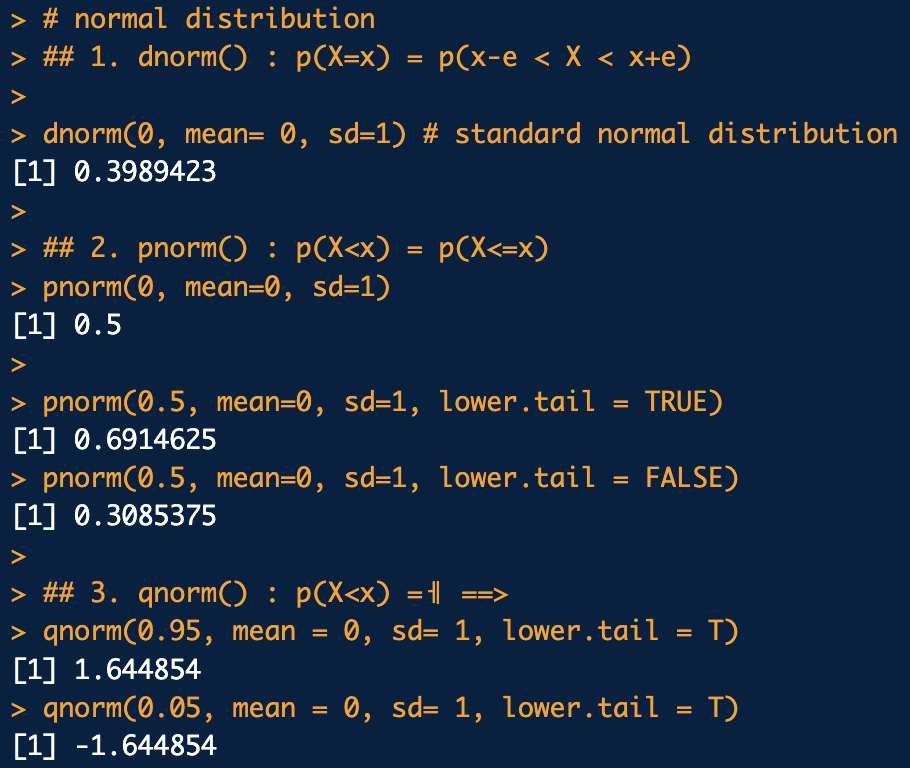
dnorm() -> 수치형 확률변수 X가 x의 확률을 계산 pnorm() -> 확률변수 X가 x보다 작을 확률 lower.tail 0보다 클 확률을 계산 또는 0보다 작을 확률을 계산 인자를 'FALSE'로 설정하면, 확률밀도함수의 우측 면적을 계산 qnorm() ->
19.통계적 가설 검정
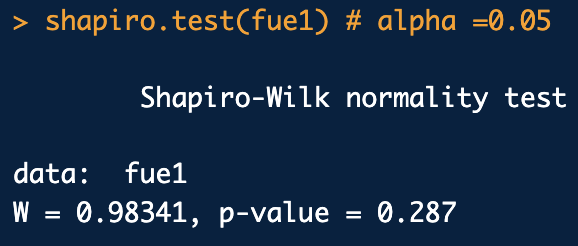
모집단의 모수에 대한 어떤 주장이나 진술에 대해 모집단으로부터 추출한 표본에 근거하여 기각여부를 결정하는 과정가설은 Hypothsis라고 하고 가설의 H자를 따서 대문자 H로 표현합니다.과학의 발전 과정에서 기존의 이론이나 법칙을 부정하는 강한 반증이 관측이나 실험의
20.윌콕슨 순위합 검정 & 대응표본 평균 차이 검정
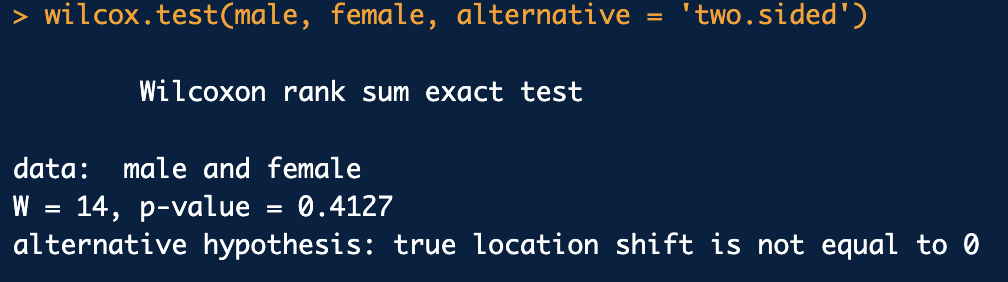
월곡슨 순위합 검정두 독립표본의 위치 차이에 대한 비모수적 검정 (모집단의 분포를 정규 분포로 가정하지 못할 때)rank() 작은값 부터 큰 값의 순서를 저장wilcox.test() 작은 집단의 순위합을 바로 알 수 있음x : 첫 번째 모집단으로부터 추출한 자료y :
21.일원배치 분산분석

일반적으로 3개 이상의 모집단에서 모평균을 비교하는 문제3개 이상 모집단에서 3개 이상의 평균을 비교하는 경우범주형 변수 (3가지 이상의 범주값) 수치형 변수 (평균 비교에 사용되는 변수)평균을 비교하기 전에 세 집단의 분포가 정규분포인지, 집단 간 분산이 동일한지에
22.반복측정 분산분석
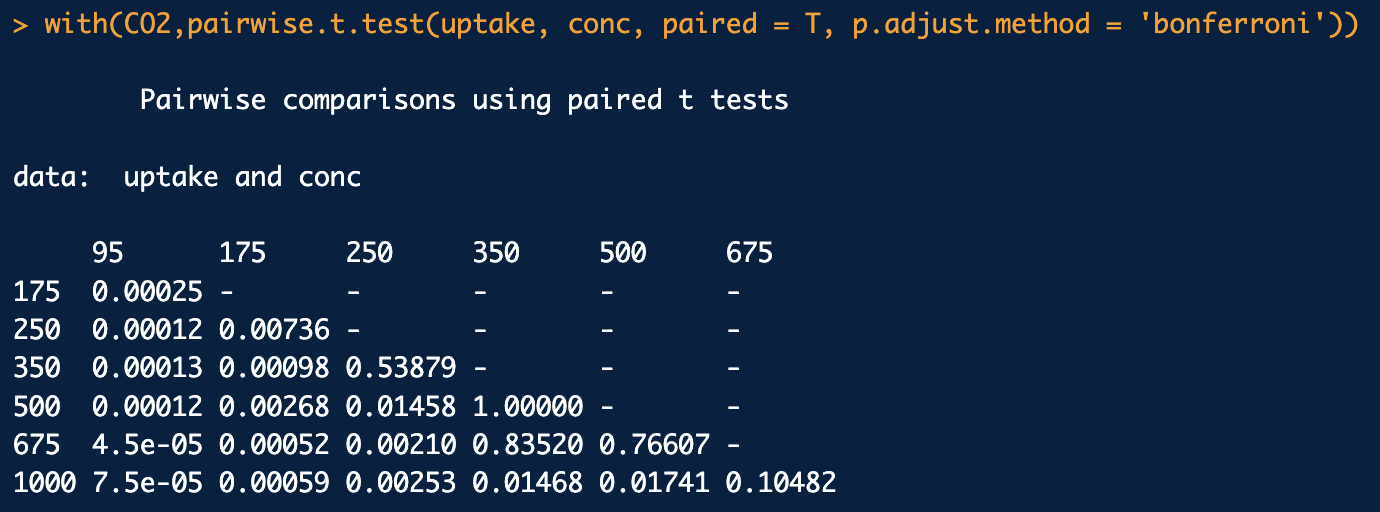
한 개의 요인이 있고 요인이 시간처럼 반복요인이라고 하면, 수치형 종속변수를 측정할 때 한 시험대상은 반복되는 시간마다 종속변수를 관측하게 됨K명의 실험대상자가 총 r번의 반복마다 종속변수를 측정하여 반복마다가 차이가 있는지 알아볼 경우한 개의 요인 (실험집단, 처리집
23.상관분석
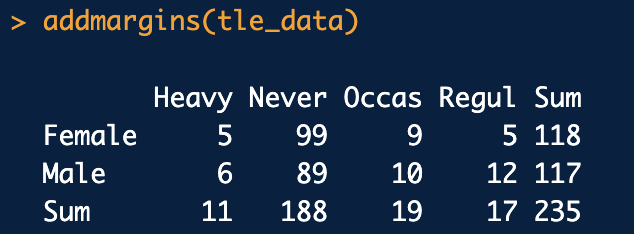
분류변수에 대한 검정 중 가장 빈번하게 사용됩니다. 한 모집단에서 두 개의 분류변수가 서로 독립적으로 움직이는지 확인 하기 위해 사용하는 분석법입니다.2개의 분류변수 혹은 범주변수가 주어진 경우, 관련성을 알아보기 위해서 표로 요약\-> 각 범주변수의 범주값을 가로와