결정 트리 학습이란?
어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델로,
이는 통계학과 데이터 마이닝 기계 학습에서 사용하는 예측 모델링 방법 중 하나이다.
트리 모델 중 목표 변수가 유한한 수의 값을 가지는 것을 분류 트리라 한다.
이 트리 구조에서 잎(리프 노드)은 클래스 라벨을 나타내고 가지는 클래스 라벨과 관련있는 특징들의 논리곱을 나타낸다. 결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가지는 것은 회귀 트리라 한다.
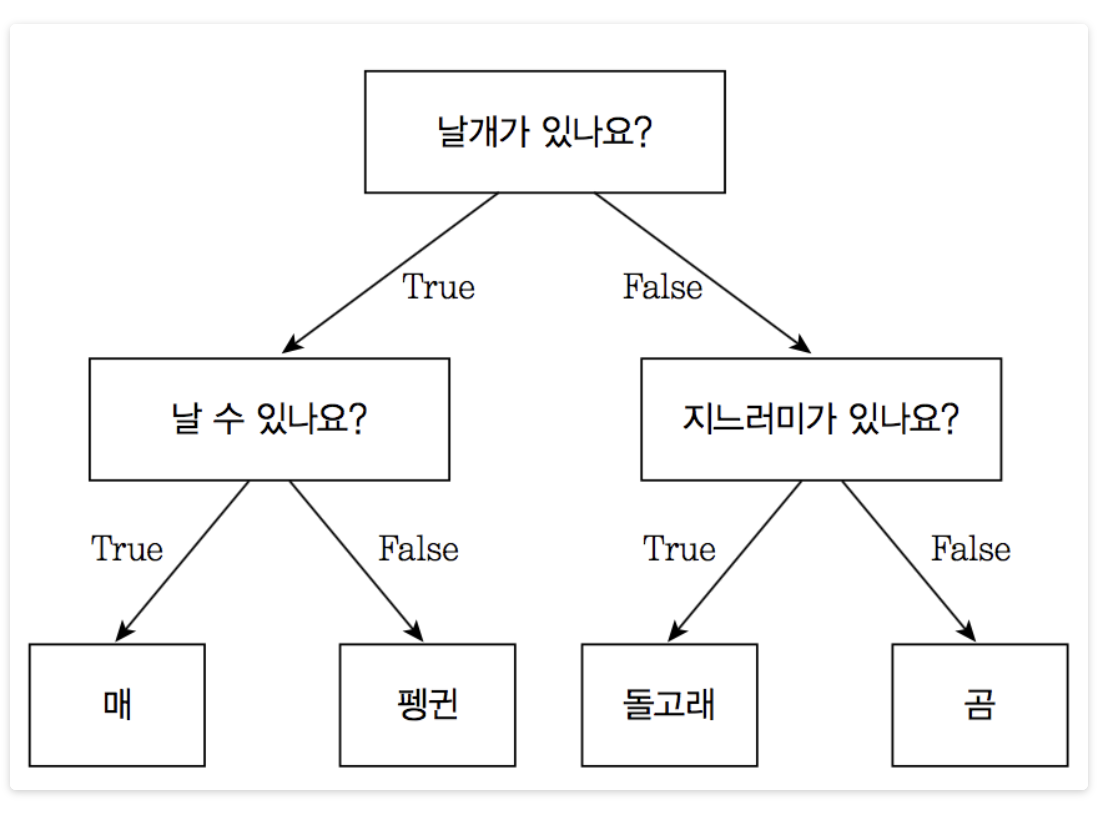
기본적으로 결정 트리는 결정에 다다르기 위해 예/아니오 질문을 이어 나가면서 학습합니다.
머신러닝 식으로 말하면
세 개의 특성 “날개가 있나요?”, “날 수 있나요?”, “지느러미가 있나요?”를 사용해 네 개의 클래스(매, 펭귄, 돌고래, 곰)를 구분하는 모델을 만든 것입니다. 이런 모델을 직접 만드는 대신 지도 학습 방식으로 데이터로부터 학습할 수 있습니다.
의사결정나무는 분류(classification)와 회귀(regression) 모두 가능합니다. 범주나 연속형 수치 모두 예측할 수 있습니다.
새로운 데이터가 특정 terminal node에 속한다는 정보를 확인한 뒤 해당 terminal node에서 가장 빈도가 높은 범주에 새로운 데이터를 분류하게 됩니다.
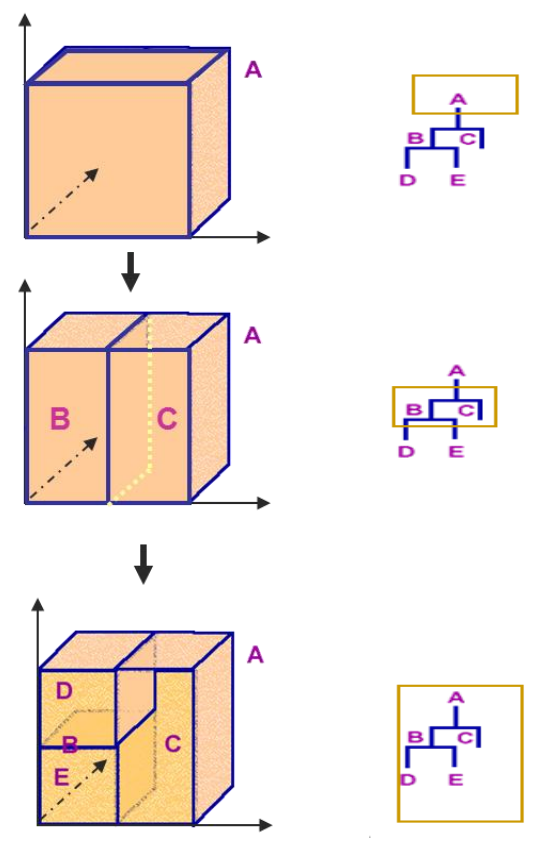
아무런 분기가 일어나지 않은 상태의 root node는 A입니다.
위에 예시 처럼 "날개가 있나요?”, “날 수 있나요?”, “지느러미가 있나요?" 와 같은 특성을 사용해 클래스를 구분했다고 보면,전체 데이터 A가 세 개의 부분집합으로 분할된 것 또한 알 수 있습니다.
D 특성을 갖고 있는 새로운 데이터가 주어졌을 때 의사결정나무는 D 집합을 대표할 수 있는 값(분류=최빈값, 회귀=평균)을 반환하는 방식으로 예측합니다.
엔트로피 지수
정보량(information content)은 확률에 반비례한다
주사위 던지기에서 일어나는 한 사건의 확률은 동전 던지기에서 일어나는 한 사건의 확률보다 작다. 즉, 여기서 엔트로피는 주사위 던지기가 동전 던지기보다 크다고 할 수 있다.
엔트로피는 '어떤 상태에서의 불확실성', 또는 이와 동등한 의미로 '평균 정보량'을 의미한다
정보 엔트로피가 커지는것은 역시 변수(불확실성)가 증가하는 것을 의미하므로, 변수를 제어함으로써 불확실성이 줄어드는 것은 결국 정보 획득을 의미하게 된다.
그러므로 획득을 증가시켜 불확실성을 감소시키는 것은 변수가 줄어드는 것으로 볼 수 있는데 이것은 결과적으로 엔트로피의 크기를 감소시키는 정보 이득과 관계있다.
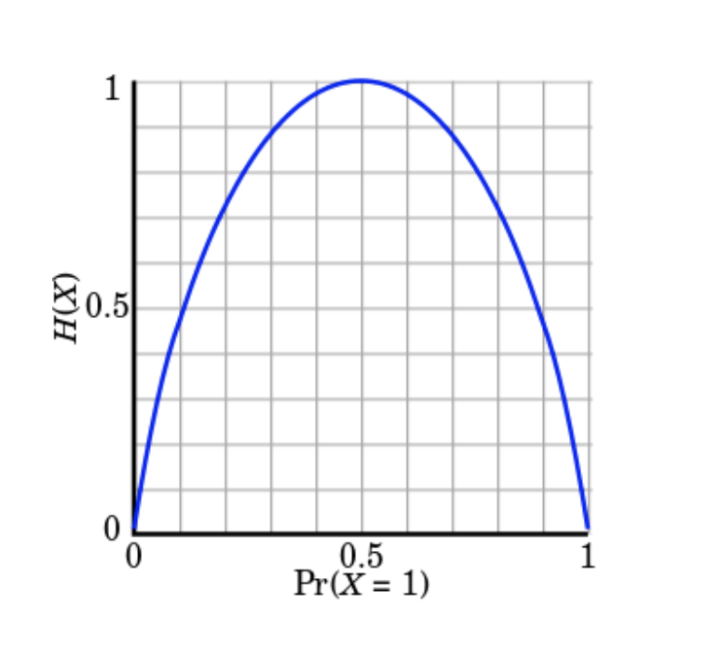
https://ko.wikipedia.org/wiki/%EC%A0%95%EB%B3%B4_%EC%97%94%ED%8A%B8%EB%A1%9C%ED%94%BC
