혼동 행렬 이란?
분류 모델에서 학습 시킨 뒤, 모델에서 데이터의 X값을 집어넣어 얻은 예상되는 y값과, 실제 데이터의 y값을 비교하여 정확히 분류 되었는지 확인하는 메트릭(metric)이라고 할 수 있습니다.
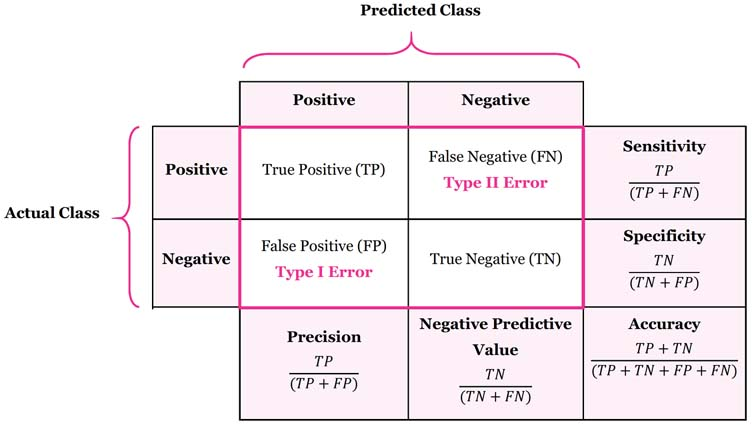
True Positive(TP) : 실제 값은 Positive, 예측된 값도 Positive.
False Positive(FP) : 실제 값은 Negative,예측된 값은 Positive.
False Negative(FN) : 실제 값은 Positive, 예측된 값은 Negative.
True Negative(FN) : 실제 값은 Negative, 예측된 값은 Negative.
예시;
TP : 암환자를 암환자라고 한 경우
FP : 암환자가 아닌데, 암환자라고 한 경우 (1종 오류)
FN : 암환자인데, 암환자가 아니라고 한 경우 (2종 오류)
FN : 암환자가 아닌 사람을 암환자가 아니라고 한 경우
Accuracy란?
Accuracy(정확도)는 올바른 총 예측 수의 비율입니다.
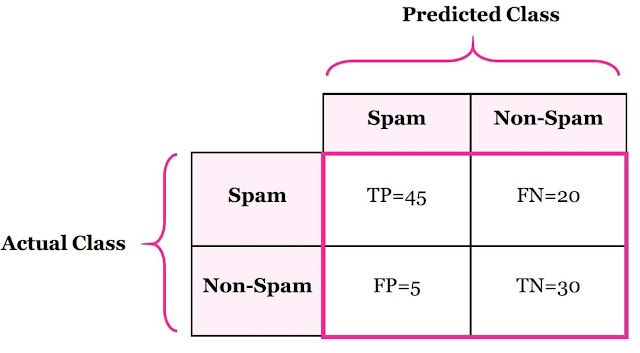
Accuracy = (45+30)/(45+20+5+30) = 75%
Precision란?
Precision(정밀도)는 올바르게 분류된 긍정적인 예의 총 수와 예측된 긍정적인 예의 총 수의 비율입니다. 긍정적인 예측에서 얻은 정확성을 보여줍니다.
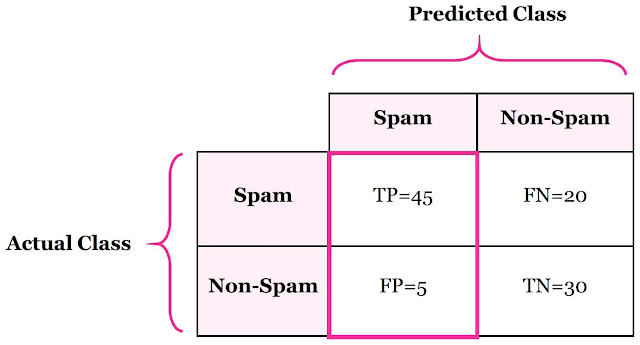
Precision = 45/(45+5)= 90%
Sensitivity = Recall란?
Sensitivity(민감도)는 True Positive Rate 또는 Recall이라고도 합니다.
분류기에 의해 양성으로 분류된 양성 사례의 척도입니다
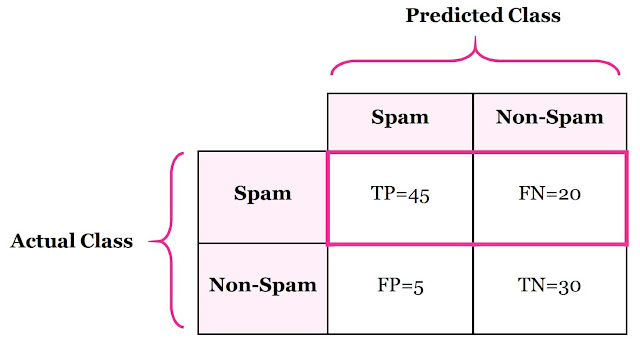
Sensitivity = 45/(45+20) = 69.23%
*출처 https://manisha-sirsat.blogspot.com/2019/04/confusion-matrix.html
F1 Score 란?
F1 Score 는 분류 모델에서 사용 되는 머신 러닝 metric(평가지표)입니다. Precision(정밀도)과 Recall(재현도)으로 F1 score가 구성되고 불균형한 데이터가 잘 동작하는지에 대한 평가지표가 됩니다.
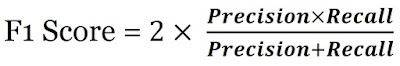
일반 평균은 모든 값을 동일하게 취급하지만, 조화 평균은 낮은 값에 더 많은 가중치를 부여합니다. F1 Score는 항상 유사 분류자를 선호하는 것이 아니지만, 일반적으로 precision(정밀도)와 recall(재현도)가 유사한 분류자를 선호합니다.
F1 Score는 0.0 ~ 1.0 사이의 값을 가지며 높을수록 좋고, 특히 정밀도와 재현율이 근접할 때 훨씬 더 잘 수행되는 경향이 있습니다.
