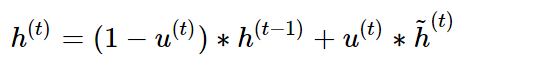분포가설과 분산표현
분포가설(distribution hypothesis)
- 정의: 유사한 맥락에서 나타나는 단어는 그 의미도 비슷하다는 것을 말한다.
분산표현(distributed Representation)
-
정의: 유사 맥락에 나타난 단어 사이의 거리를 가깝게 하거나 멀지 않게 조정하는 것
-
효과: 단어간의 유사도를 계산
희소표현(Sparse Representation)
- 정의: 벡터의 특정 차원에 단어 혹은 의미를 직접 매핑하는 방식
Embedding layer
-
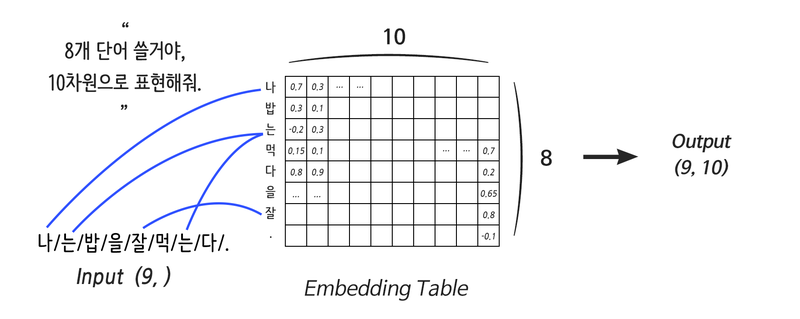
정의: 입력으로 들어온 단어를 분산 표현으로 연결해줌
-
특징:
- 단어의 분산 표현을 구현하기 위한 레이어이다.- 입력에 직접 연결되게 사용
-
훈련 방식: ELMo, Word2Vec, Glove, FastText
- Weight: 단어의 개수, Embedding 사이즈로 정의
- Lookup Table: Weight에서 특정 행을 읽기 (by One-hot Encoding)
*One-hot Encoding(그저 단어에 순번을 매겨서 표현)
: 텍스트를 유의미한 숫자로 바꾸는 방법으로 N개의 단어를 각각 N차원에 넣어 표현
: 직교인 상태 - 모든 단어가 단어끼리의 관계가 반영되지 못한 독립적인 상태
- Code
import tensorflow as tf
vocab = { # 사용할 단어 사전 정의
"i": 0,
"need": 1,
"some": 2,
"more": 3,
"coffee": 4,
"cake": 5,
"cat": 6,
"dog": 7
}
sentence = "i i i i need some more coffee coffee coffee"
# 위 sentence
_input = [vocab[w] for w in sentence.split()] # [0, 0, 0, 0, 1, 2, 3, 4, 4, 4]
vocab_size = len(vocab) # 8
one_hot = tf.one_hot(_input, vocab_size)
print(one_hot.numpy()) # 원-핫 인코딩 벡터를 출력해 봅시다.
distribution_size = 2 # 보기 좋게 2차원으로 분산 표현하도록 하죠!
linear = tf.keras.layers.Dense(units=distribution_size, use_bias=False)
one_hot_linear = linear(one_hot)
print("Linear Weight")
print(linear.weights[0].numpy())
print("\nOne-Hot Linear Result")
print(one_hot_linear.numpy())
some_words = tf.constant([[3, 57, 35]])
# 3번 단어 / 57번 단어 / 35번 단어로 이루어진 한 문장입니다.
print("Embedding을 진행할 문장:", some_words.shape)
embedding_layer = tf.keras.layers.Embedding(input_dim=64, output_dim=100)
# 총 64개의 단어를 포함한 Embedding 레이어를 선언할 것이고,
# 각 단어는 100차원으로 분산표현 할 것입니다.
print("Embedding된 문장:", embedding_layer(some_words).shape)
print("Embedding Layer의 Weight 형태:", embedding_layer.weights[0].shape)RNN in Recurrent layer
시퀀스 데이터
- 정의: 순차적인 특성을 갖는 데이터.
RNN
-
정의: 순차 데이터처리한다.
-
특징:
- RNN의 입력으로 들어가는 모든 단어만큼 Weight를 만드는 게 아니다.- (입력차원, 출력차원)에 해당하는 Weight를 순차적 업데이트
- 여러번의 연산이 필요하기에 속도가 느리다.
- 뒤로 갈수록 기울기가 손실하는 문제를 가짐
- 문장이 길수록 미분값이 매우작거나 커지는 현상이 발생
- Vanishing Gradient(매우 작음) [ 가중치 업데이트가 안되어서 학습이 덜 됨)
- Exploding Gradient(매우 큼) [ 가중치 업데이트가 너무 커서 학습이 불안정]
-
기울기 손실 문제 해결
- return_sequences인자 조절하면 됨
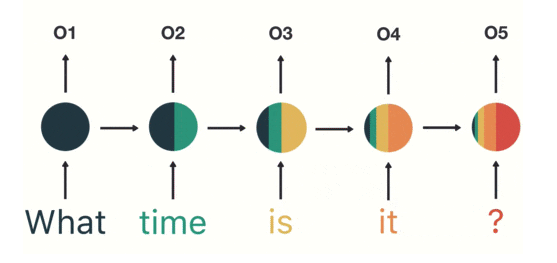
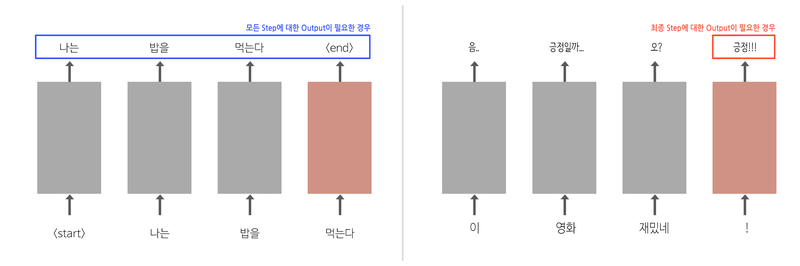
- 단순 긍정/ 부정 나누기: 최종 Step의 Output만 확인해도 됨
- 문장 생성 경우: 이전 단어를 입력으로 받아 생성된 모든 단어의 Output필요
- Code
sentence = "What time is it ?"
dic = {
"is": 0,
"it": 1,
"What": 2,
"time": 3,
"?": 4
}
print("RNN에 입력할 문장:", sentence)
sentence_tensor = tf.constant([[dic[word] for word in sentence.split()]])
print("Embedding을 위해 단어 매핑:", sentence_tensor.numpy())
print("입력 문장 데이터 형태:", sentence_tensor.shape)
embedding_layer = tf.keras.layers.Embedding(input_dim=len(dic), output_dim=100)
emb_out = embedding_layer(sentence_tensor)
print("\nEmbedding 결과:", emb_out.shape)
print("Embedding Layer의 Weight 형태:", embedding_layer.weights[0].shape)
rnn_seq_layer = \
tf.keras.layers.SimpleRNN(units=64, return_sequences=True, use_bias=False)
rnn_seq_out = rnn_seq_layer(emb_out)
print("\nRNN 결과 (모든 Step Output):", rnn_seq_out.shape)
print("RNN Layer의 Weight 형태:", rnn_seq_layer.weights[0].shape)
rnn_fin_layer = tf.keras.layers.SimpleRNN(units=64, use_bias=False)
rnn_fin_out = rnn_fin_layer(emb_out)
print("\nRNN 결과 (최종 Step Output):", rnn_fin_out.shape)
print("RNN Layer의 Weight 형태:", rnn_fin_layer.weights[0].shape)
lstm_seq_layer = tf.keras.layers.LSTM(units=64, return_sequences=True, use_bias=False)
lstm_seq_out = lstm_seq_layer(emb_out)
print("\nLSTM 결과 (모든 Step Output):", lstm_seq_out.shape)
print("LSTM Layer의 Weight 형태:", lstm_seq_layer.weights[0].shape)
lstm_fin_layer = tf.keras.layers.LSTM(units=64, use_bias=False)
lstm_fin_out = lstm_fin_layer(emb_out)
print("\nLSTM 결과 (최종 Step Output):", lstm_fin_out.shape)
print("LSTM Layer의 Weight 형태:", lstm_fin_layer.weights[0].shape)LSTM in Recurrent layer
- 정의: 기울기 소실 문제를 해결하기 위해 고안된 레이어
-
특징:
- 4 종류의 서로 다른 weight를 가진 RNN이다.- Gate: 각 weight가 가지고 있는 것으로 정보를 기억하고 전달할지 정하는 단계
- Cell state: 긴 문장이 들어와도 큰 손실 없이 오랫동안 기억함
- 엿보기 구멍(peephole connection): Gate Layer들이 Cell state를 보게함
-
Gate Layer
-
input와 hidden state만 참조하여 값을 결정
1.Forget Gate Layer : cell state의 기존 정보를 얼마나 잊어버릴지를 결정
2.Input Gate Layer : 새롭게 만들어진 cell state를 기존 cell state에 얼마나 반영할지를 결정
3.Output Gate Layer : 새롭게 만들어진 cell state를 새로운 hidden state에 얼마나 반영할지를 결정
-
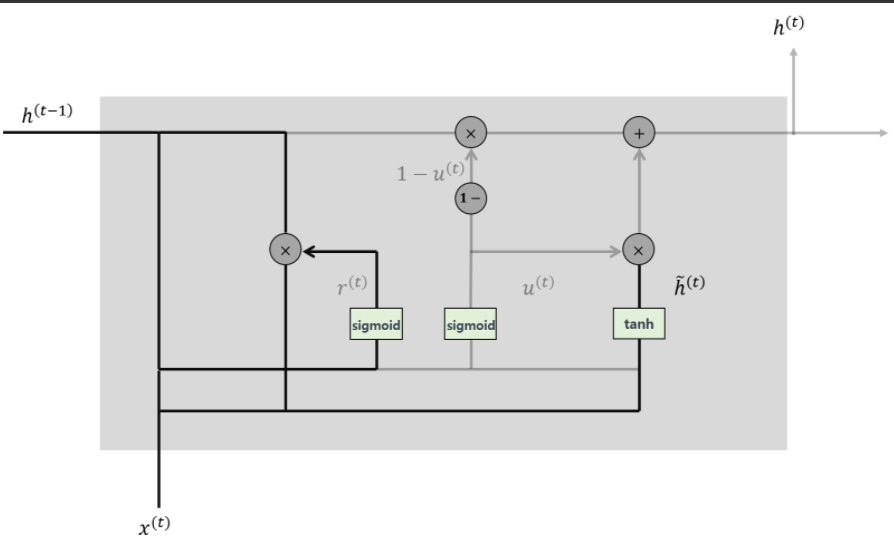
GRU
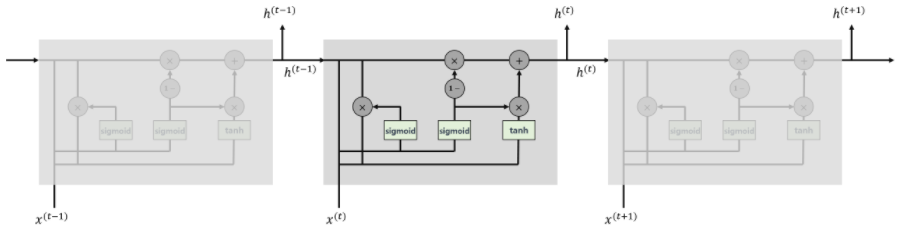
-
LSTM의 변형 모델로 Forget Gate와 Inpurt Gate를 Update Gae로 합침
-
Cell State와 Hidden State합침
-
학습할 가중치가 적다(LSTM의 1/4)
- Reset Gate
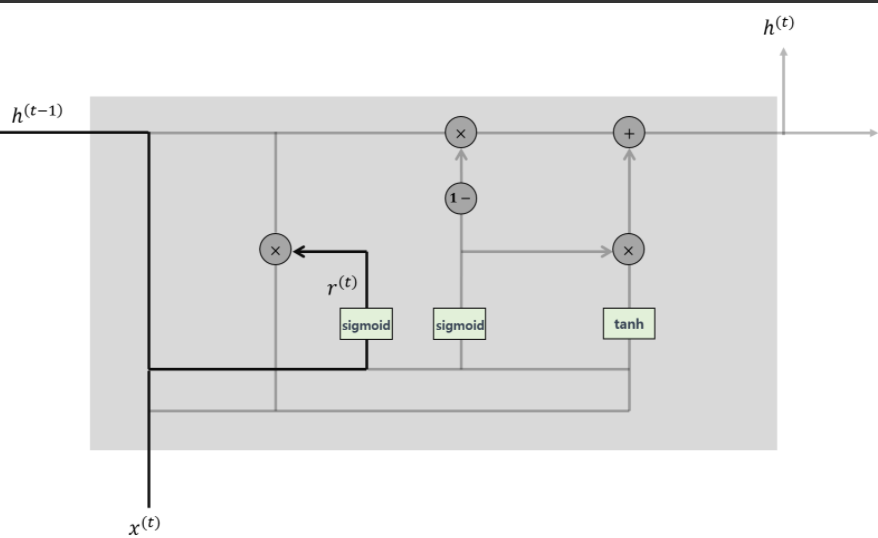
: 과거의 정보를 적당히 리셋시키는 것으로 sigmoid함수를 출력으로 이용하여 (0,1)값을 이전 은닉층에 곱해줌
- 수식:
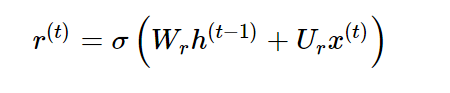
- Update Gate
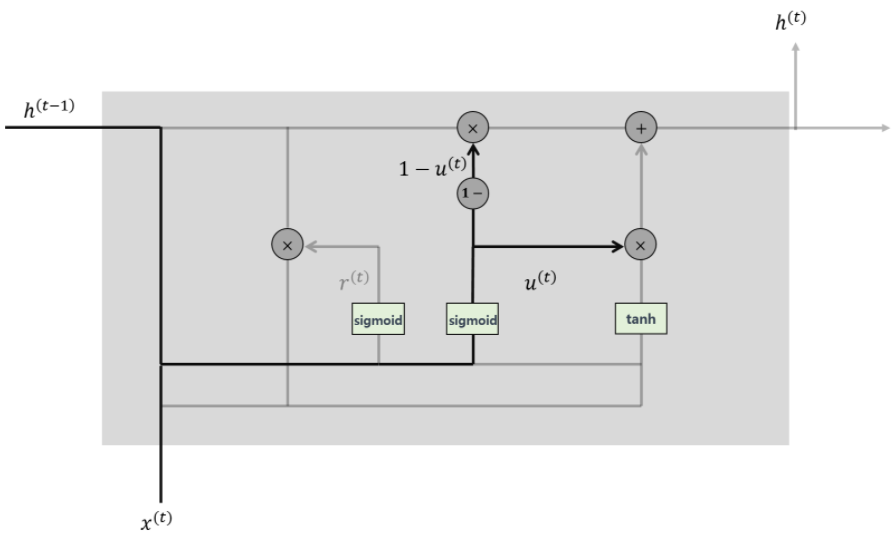
: 과거와 현재 정보의 최신화 비율을 결정하는 것으로 sigmoid로 출력된 결과는 정보의 양을 결정하고 1을 뺀 값은 직전 시점의 은닉층의 정보를 곱해줌
- 수식:
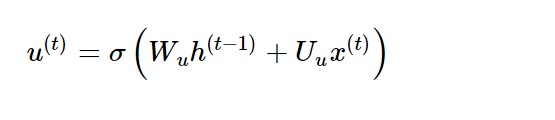
- Candidate
: 정보 후보군을 계산하는 단계로 은닉층의 정보를 그대로 이용하지 않고 리셋 게이트의 결과를 곱하여 이용.
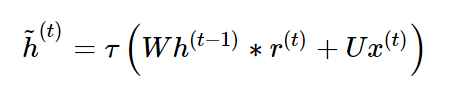
T는 tangent hyperbolic, pointwise operation
- 은닉층 계산
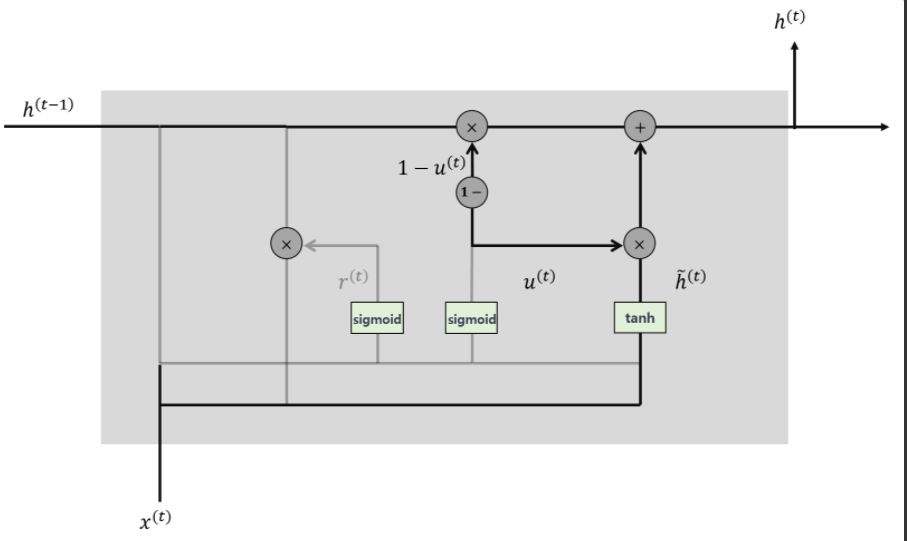
: update gate 결과와 candidate 결과를 결합하여 현시점의 은닉층 계산으로 sigmoid 함수의 결과는 정보의 양을 결정하고, 1-sigmoid 함수의 결과는 과거 시점의 정보양 결정
- 수식: