Blog 목적

[저자: bskyvision]
[이미지 출처: 링크텍스트]
저번까지 CV와 딥러닝의 역사를 배웠다면, 이제는 CV의 여러 핵심 요소들을 공부하기 위한 여정을 달릴 겁니다.
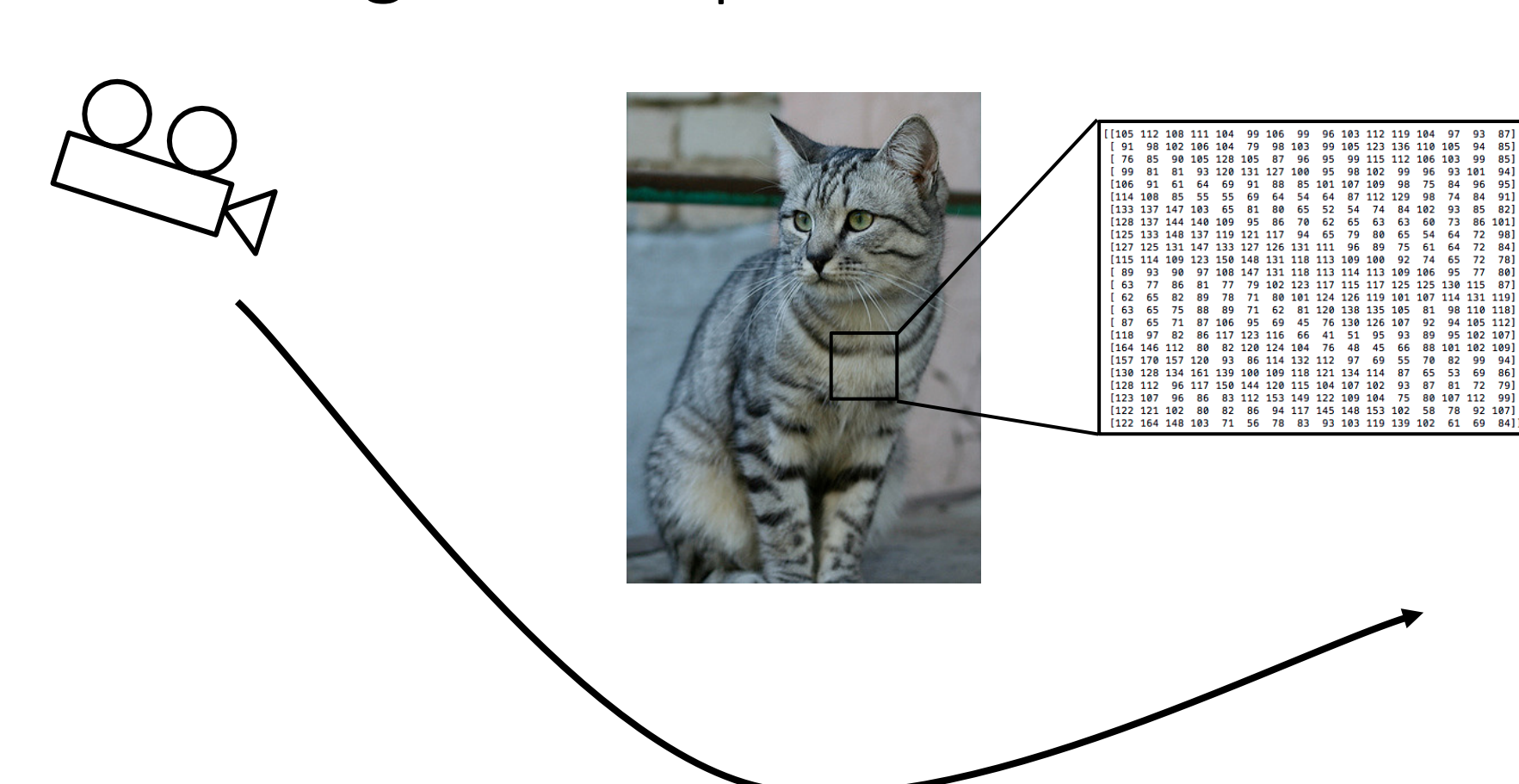
CV의 핵심 요소 중에 하나로 불리는 Image Classification을 함께 배울 것입니다.
Image Classification
Image Classification의 정의는 입력 이미지를 받아서 그 이미지가 속한 그룹이 어디인지 반환을 해주는 기능이라고 생각을하면 됩니다.
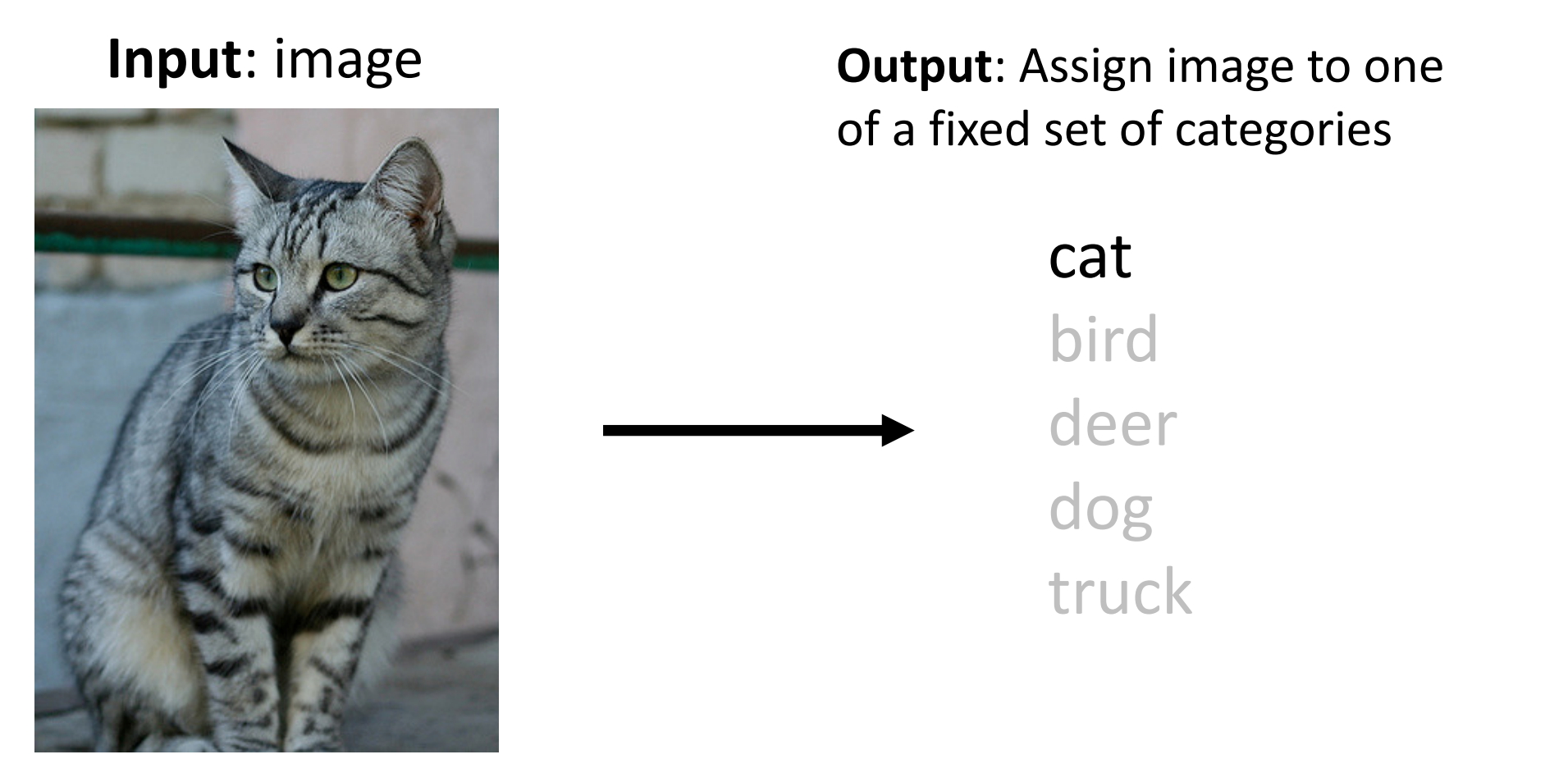
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
이렇게만 보면 정말 어떤 이미지가 들어와도 다 올바르게 인식을 할 수 있을 것 같으나 실제로 기계가 인지를 할 때는 여러 문제점들로 인해서 제대로 인식을 못하는 경우도 있게 됩니다.
Semantic Gap
사람은 물체를 볼 때 직관적으로 이 물체에 대해서 인지를 하지만 컴퓨터는 어떠한 값을 기반으로 이미지를 인식하고 카테고리를 분류하기 때문에 사람과의 차이가 나타나기 마련입니다.
이러한 차이, 즉 사람에겐 간단하지만 기계에게 어려운 것으로 인해 벌어지는 것들을 Semanctic Gap라고 합니다.
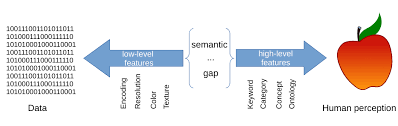
[저자: Wikimedia Commons]
[이미지 출처: 링크텍스트]
{kind=link}
Problems
왜? 컴퓨터는 사람처럼 직관적인 이해가 불가능하고 초반에 " 여러 문제점"으로 인해서 기계가 제대로 인식을 못하는 경우가 있다고는 설명했으나 구체적인 예시를 들진 않았고, 이제 그 부분에 대해서 이야기하려고 합니다.
이 부분은 이미지를 통한 직관적 이해하기를 권장합니다.
Viewpoint Variation(각도 변화)
입력 사진이 같아도 카메라의 각도가 달라지면 각 영역의 픽셀 값들이 달라지게 되어서 다르게 인식합니다.
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Intraclass Variation
같은 범주에 속한 것들이어도 당연히 약간의 차이 존재합니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Fine-Grained Categories(다양한 종류)
예를 들어, 고양이라는 이름은 같지만 종들이 다를 수 있는 것처럼, 이러한 경우엔 고양이라는 공통점을 무시하고 종 간의 차이점만으로 이미지를 분류해야합니다.(어려울 겁니다)

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Backgroud Clutter
만약 배경과 비슷한 색 즉, 보호색을 띄는 동식물들이 있다면 배경별로도 이미지 처리들 해줘야하는 어려운 부분이 생기게 됩니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Illumination Changes
조명의 차이로 인해서 인식을 하기 어려운 경우입니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Deformation
이미지의 객체들은 항상 같은 포즈를 취하지 않고 여러 포즈를 취합니다.

[저자: Jusin Johnson]
[이미지 출처: 링크텍스트]
Occlusion
일부만 찍히거나 전체가 찍혀도 가려진 경우입니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
이러한 문제가 있음에도 계속해서 Image Classification을 연구하려는 이유가 뭘까요?
Advantages
여러 실생활에서 다양하게 사용되고 있음을 예시를 통해서 알려드립니다.
의료데이터, 환자의 데이터를 보고 정확한 진단이 가능해지게됩니다.
은하 연구, 이 은하를 보고 어떤 은하인지를 판단하게 도와줄 수 게 됩니다.
이처럼 사람이 보기 어렵고 방대하고 중요한 데이터를 Image Classification의 정교한 알고리즘을 이용한다면, 여러 이점을 주게 됩니다.
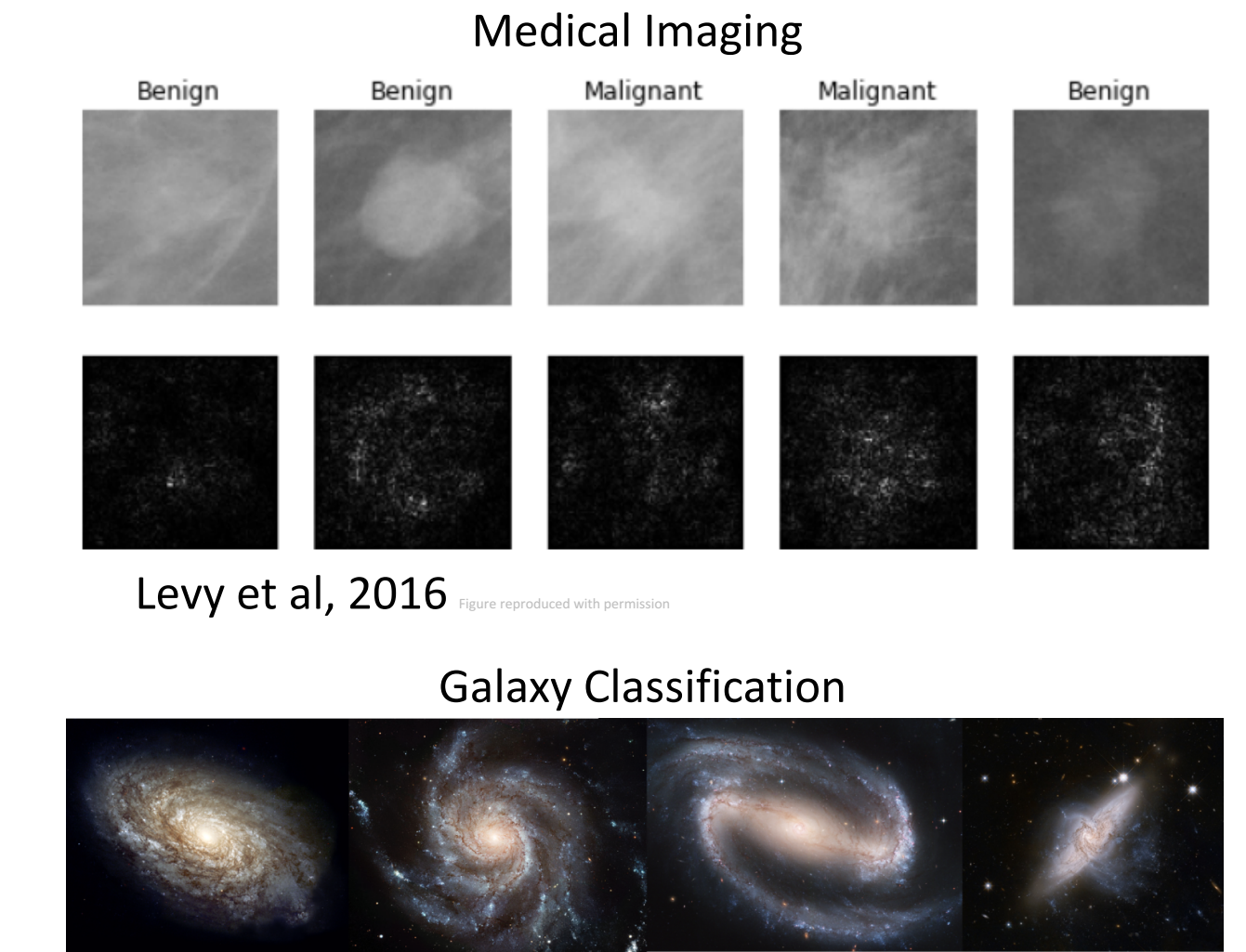
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
총 정리
위의 상황들이 사람에게는 정말 당연하게 분류하고 인식을 정확하게 하겠지만 컴퓨터에게는 왜 사람처럼 직관적인 능력을 부여할 수 없는지에 대해서 이야기했고
만약 이 상황들을 해결하게 된다면 Image classification은 의료계 ~ 우주~ 동식물까지 여러 연구분야에게 너무나 큰 이점을 가져다 주게 될거라는 전망을 해봅니다.
Image Classification with Block
이제부터 어떻게 Image Classification이 여러 연구 분야에서 어떻게 쓰이는지 알아보는데 이 기술은 단독으로 쓰이는 것보다 다른 작업을 구성하는 하나의 block형태로 자주 쓰입니다.
Object Detection(물체 탐색)
Object Detection은 이미지 안에 있는 객체를 박스로 그려서 가둔 후 그 이미지가 무엇인지 예측하는 것으로
Image Classification과 같이 쓰면 이미지 속 각 물체가 어디에 위치했는지를 표현하는 것으로 박스 옮겨 가며 Sliding Window라는 작업을 수행하며 물체 탐색를 합니다.
Sliding window는 사진을 윈도 사이즈에 맞춰 나눈 다음 매 윈도우로 잘린 이미지를 입력값으로 모델을 통과해서 결과를 얻는 방법입니다.


[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Image Captioning(이미지 캡션)
Image Captioning은 문자 그대로 이미지를 하나의 인지적 언어로 바꿔주는 것으로 예를 들면, 남자 사진을 보고 man으로 출력하는 것입니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Playing Go
컴퓨터 게임을 할 때도 AI 시스템이 들어가는데 그 중 Image Classification 기술 또한 도움을 줍니다.
바둑으로 예를 들면, AI는 좌표를 픽셀 값으로 받은 후Image Classification을 이용하여 바둑돌이 놓인 위치를 인식할 수 있게 됩니다.(알파고를 연상하시면 편합니다.)
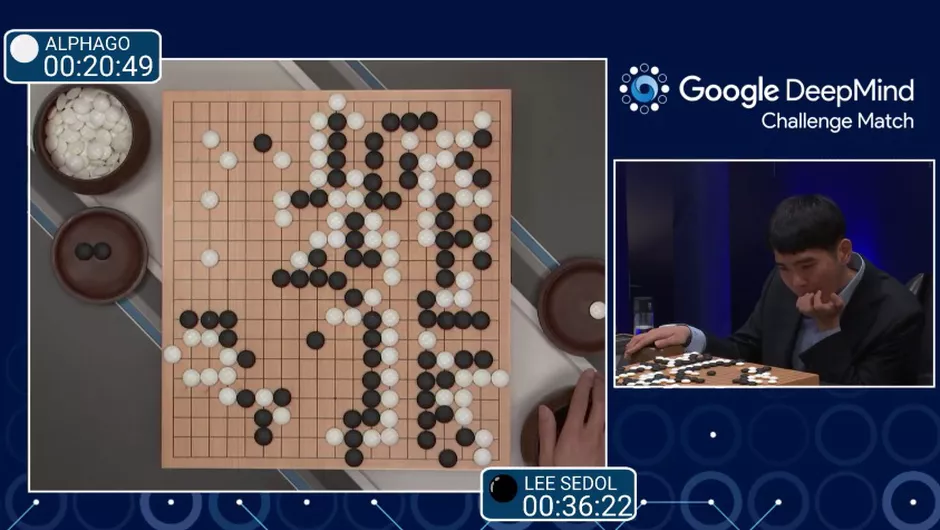
[저자: Screenshot by Claire Reilly/CNET]
[이미지 출처: 링크텍스트]
위의 여러 가지 기능 뿐만 아니라 더욱 영향력이 있게 Image classification을 이용하여 기술 구현이 가능합니다.
허나, 다양한 상황이 있기에 정석적인 알고리즘 코드가 없다는 것이 어려운 부분이긴 하지만 다르게 이야기하면 그만큼 연구가 활발하게 진행이 되어야하는 부분이기도 합니다.
Edges
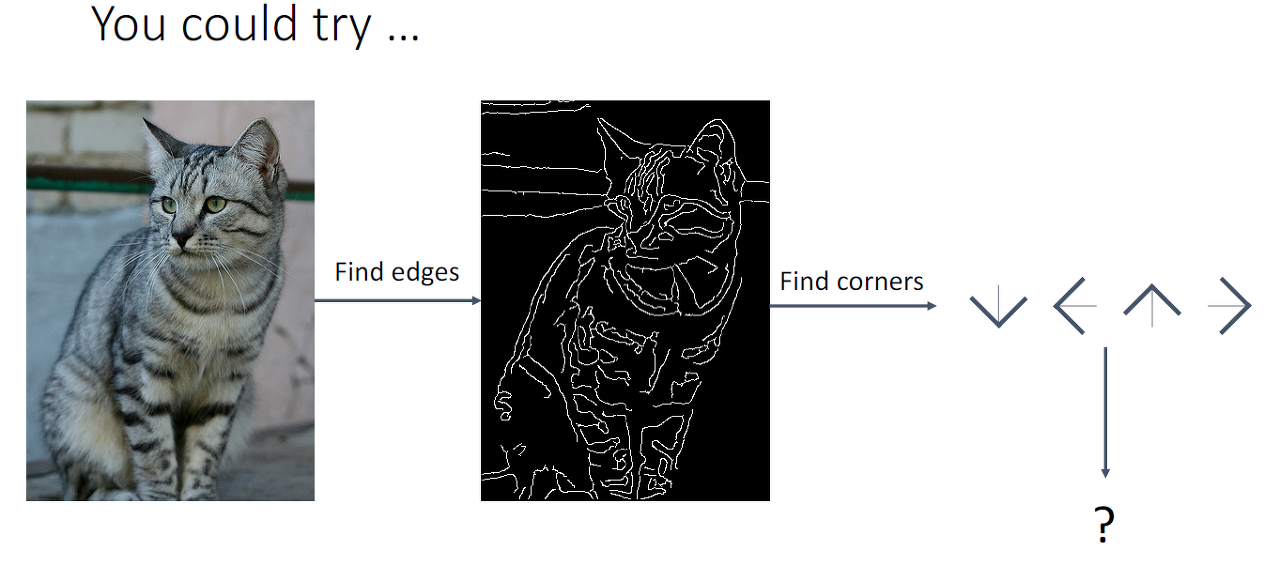
[저자: Justin Johnson]
[이미지 제출: 링크텍스트]
Edges를 통해서 이미지를 분류할 수 있으면 좋겠지만 실제로는 그렇지 못하는 이유는 위의 Problems뿐만 아니라 여러 무한한 경우의 수로 인해 같은 이미지도 다르게 인지와 인식을 할 수 있게 됩니다.
그래서 저희는 방대한 경우의 수를 대비하여 만든 데이터 셋이 필요했습니다.
Data-Driven Approach

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
머신러닝 기반으로 만든 데이터 저장소입니다. 컴퓨터에 데이터와 그에 관한 레이블(정답값)만 학습을 시켜서 특징을 추출하면 나중에 새로운 데이터가 들어와도 알아서 특징을 잡아낼 수 있기에 적절한 분류가 가능해집니다.
프로그래머는 기계를 어떻게 학습시키고 결과처리할지에 대한 알고리즘만 구현하면 되기에 편합니다.
이러한 이유를 바탕으로 머신러닝을 잘 조작하면, 원하는 종류의 사진을 분류하고 판단하는 Generic Program을 만들 수 있게됩니다.
Generic Program은 사용자가 원하는 작업을 수행하는 컴퓨터 프로그램을 찾아내는 방식입니다.
Image Classification Datasets of Generic Program
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
이 부분은 그저 이러한 데이터가 있고 이렇게 구성이 되어있다 정도만 이해하고 넘어가셔도 됩니다.
MNIST
1980~1990년대 CV에서 글자인식 프로그램을 테스트할 때 직접 사용된 데이터이지만 너무 단순한 데이터이기에 실생활에서 유용한지는 의문입니다.
데이터 구성
-
Classes: 10개, Digits 0 ~ 9
-
Grayscale Images: 28X28
-
Training Images: 50K
-
Test Images: 10K

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
CIFAR 10 & CIFAR 100
MNIST보단 복잡한 데이터셋이지만 머신러닝 모델 증명하기에는 부족하고 토이 프로젝트할 때 주로 쓰입니다.
CIFAR 10

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
데이터 구성
-
Classes: 10개
-
Training Images: 50K (5K per class)
-
Test images: 10K (1K per class)
-
Images: 32X32 RGB
CIFAR100

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
데이터 구성
-
classes : 100개
-
Training images: 50K (500 per class)
-
Testing images: 10K (100 per class)
-
Images: 32x32 RGB
-
Superclasses : 20개
ImageNet

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Object분야에서 표준 데이터라 할 수 있을 정도로 머신러닝 모델의 성능을 보여줄려면 필수로 사용하고 이미지 크기는 원하는 크기의 이미지를 받을 수 있지만 보통256 X 256 크기를 사용합니다.
그리고 이미지에서 보통 1개의 object만 존재하지 않기에 보통 top 5 accuracy라는 방식을 이용합니다.
데이터 구성
-
Classes: 1000
-
Training images : ~ 1.3M training images(~1.3K per class)
-
Validation Images: 50K (50 per class)
-
Test Images : 100K (100 per class)
MIT Places
이름 그대로 배경 유형에 집중한 데이터 셋입니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
데이터 구성
-
Class : 365개의 다른 배경
-
Train images: ~8M
-
Val images: 18.25K( 50 per class)
-
Test images: 32.5K (900 per class)
-
Image size: 265X256
Omniglot
카테고리별로 20개 정도 밖에 안되는 작은 데이터 셋이지만 머신러닝 모델이 적은 수의 데이터에 잘 작동하는지 확이할 때 사용합니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
- Categories: 1623개 (50개의 다른 알파벳)
Nearest Neighbor (NN)
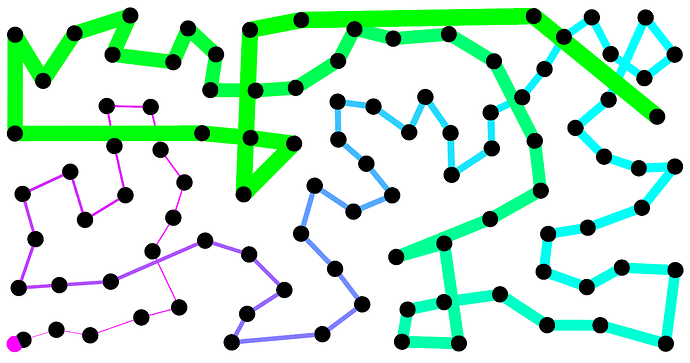
[이미지 출처: 링크텍스트]
Machine Learning Algorithm of Image Classification
부분에서 가장 간단한 알고리즘입니다.
왜냐하면, 훈련 과정에서 훈련 데이터를 저장하고 예측 과정에서는 예측 이미지를 입력해서 사전에 저장한 훈련 데이터와 가장 유사한 이미지를 찾고 그 레이블을 리턴하는 구조입니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
즉, 암기를 잘해서 잘 맞추는 분류기를 만드는 것이다.
이 암기를 잘하려면 이미지 간의 유사성을 잘 파악해야하고 이 유사성의 판별 기준은 거리 행렬을 통해서 이미지를 비교하는 것이다.
대표적인 예로, L1 distance를 뽑을 수 있고 L1 distance의 값이 작을 수록 유사하다.
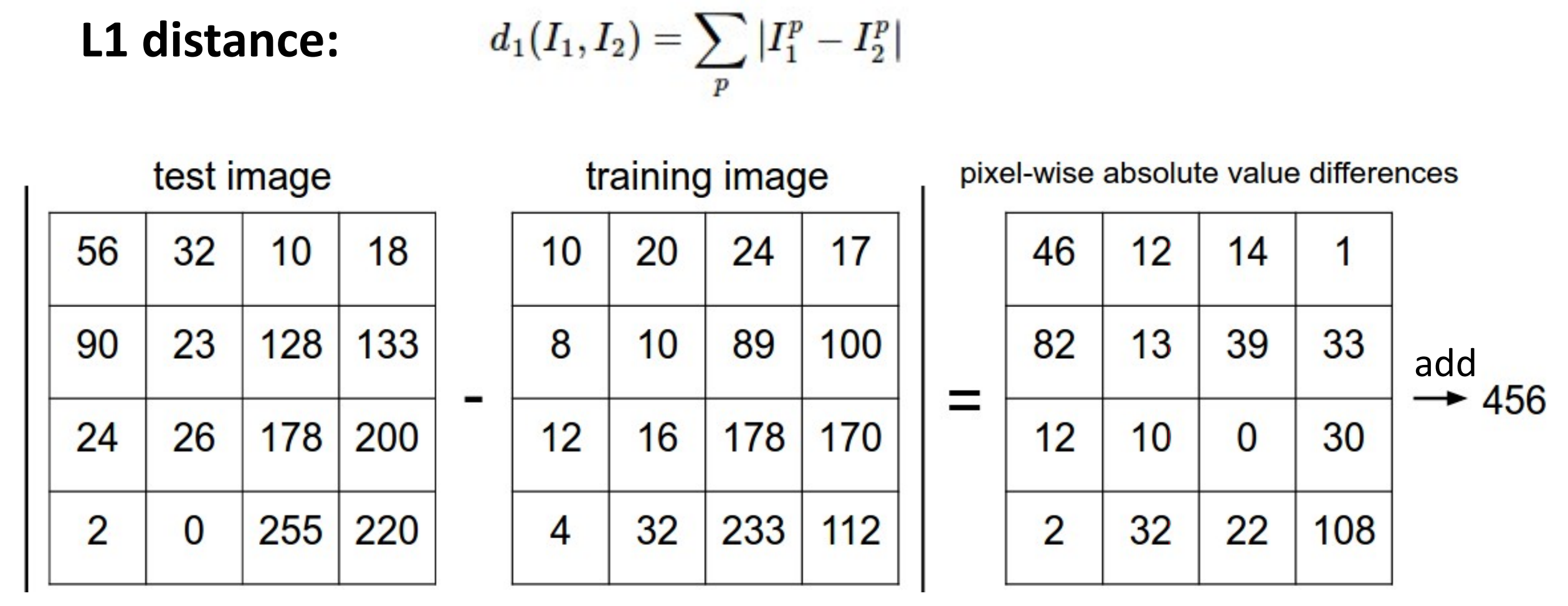
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
Mechanism of NN
시간 복잡도는 문제를 걸리는 시간과 함수의 관계를 나타내는 것입니다.
훈련 과정에서 포인터 같은 매커니즘 이용 시 O(1)이 쓰입니다.
*0(1): 입력값이 아무리 커도 실행 시간은 일정해서 최고의 알고리즘입니다.
테스트 과정에선 모든 데이터를 다 봐야하므로 O(N)만큼 시간이 걸리게 됩니다
*O(n): 입력값만큼 실행 시간에 영향을 받으며, 알고리즘을 수행하는 데 걸리는 시간은 입력값에 비례합니다.
이로 인해서 예측 과정에서 시간이 너무 오래 걸려서 좋은 모델이라고 평가를 받지 못합니다.
NN 분류기의 결과

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
위 사진은 NN 과 L1 distance를 적용한 이미지 분류기가 추출한 결과를 의미하는 것으로 제대로 인식한 것은 4개에 불과하고 나머지는 전혀 다르게 인지한 것입니다.
결론은 이미지의 유사도를 L1 distance로만 구하는 NN은 이미지를 정확하게 분류하지 못한다는 것입니다.
Decision Boundaries(결정영역)
결정 영역으로 NN기반으로 수행하는 것으로 같은 카테고리에 속한 것을 묶어서 집합을 구성합니다.
여러 집합들이 생기고 그 집합 간의 영역을 그어서 예측 데이터를 넣을 시, 해당 데이터 영역의 카테고리가 데이터의 카테고리가 되는 방식입니다.
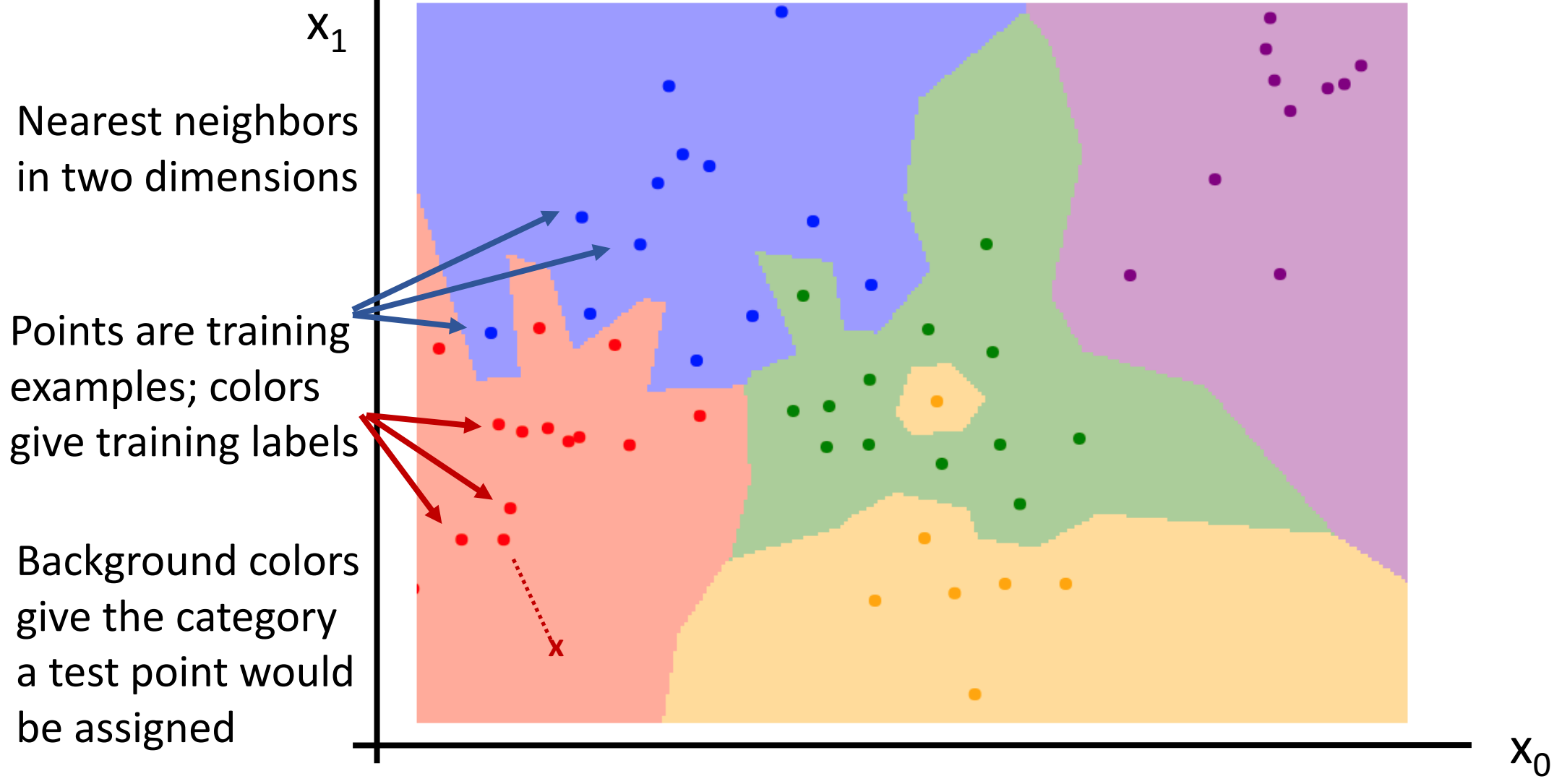
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
*점: 훈련 이미지. 배경: 테스트 카테고리영역
즉, 사진에서와 같이 파란색 데이터를 넣으면 파란색 영역으로 빨간색 데이터를 넣으면 빨간색 영역으로 가는 것이지만 간혹 특정 영역에서 튀어나오거나 동떨어지는 노이즈가 발생합니다.
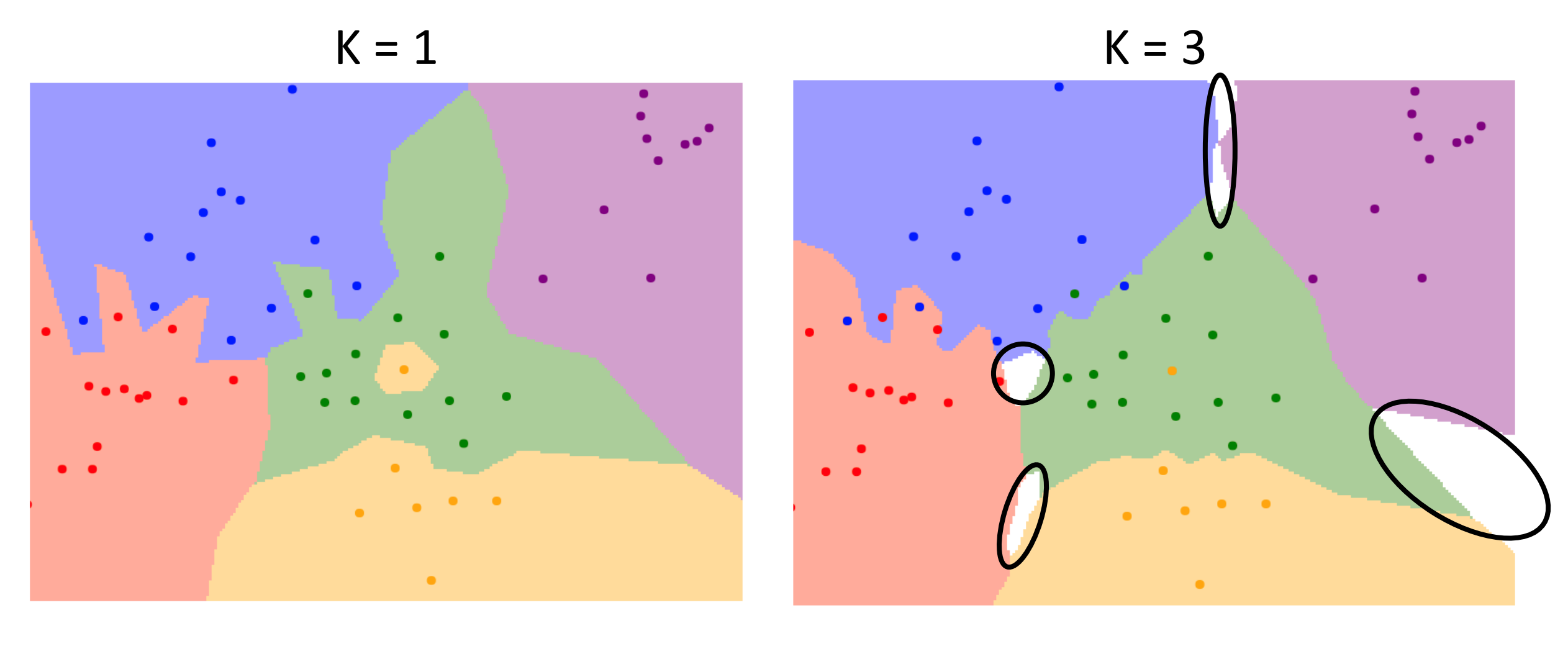
K Nearest Neighbor (KNN)
*K: 주변 개수
Decision Boundaries에서 노이즈로 인해서 이상한 점이 하나 생겼을 겁니다 그것을 해결하기 위한 방식으로 주변에 있는 점들을 K개 만큼 봐서 가장 많은 것을 골라내는 것입니다.
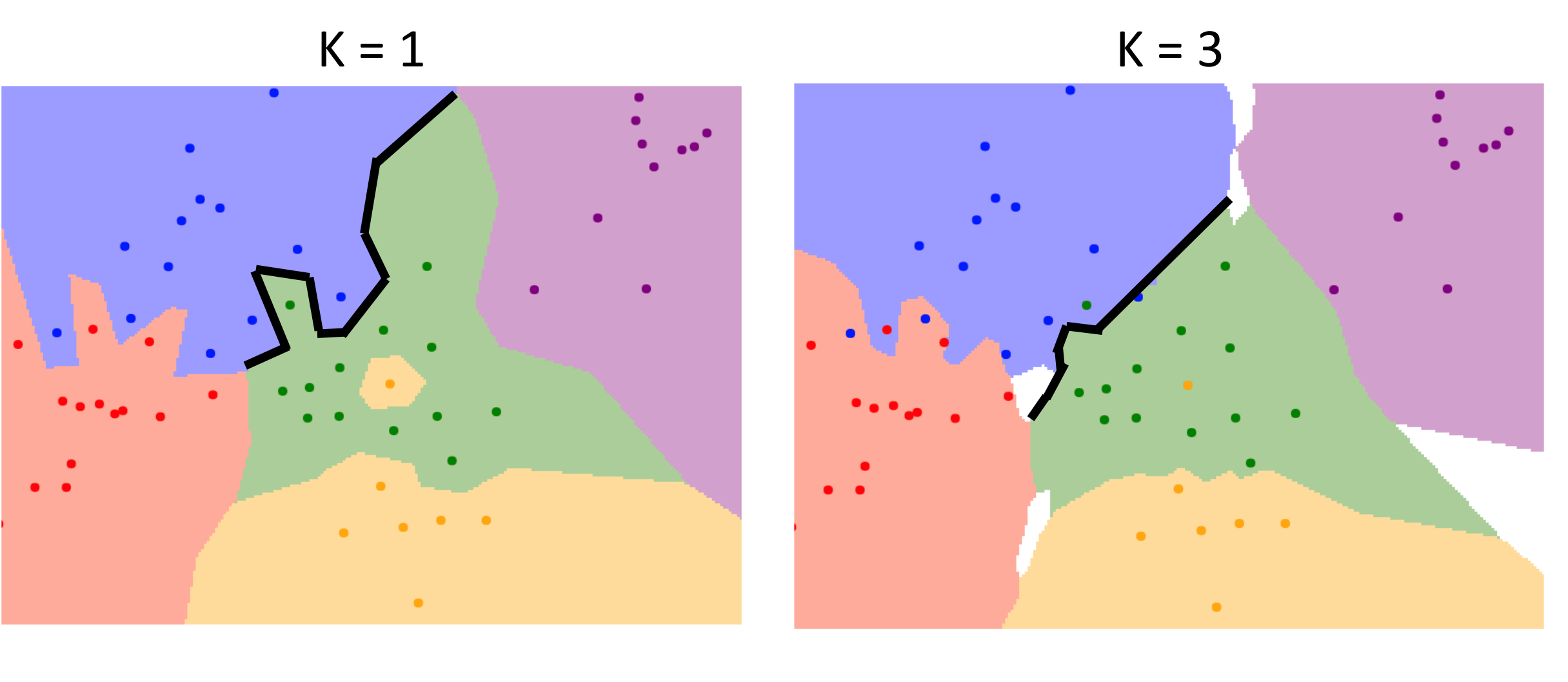
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
또한 다른 데이터와 동떨어져서 생기는 이상치도 해결이 가능합니다.
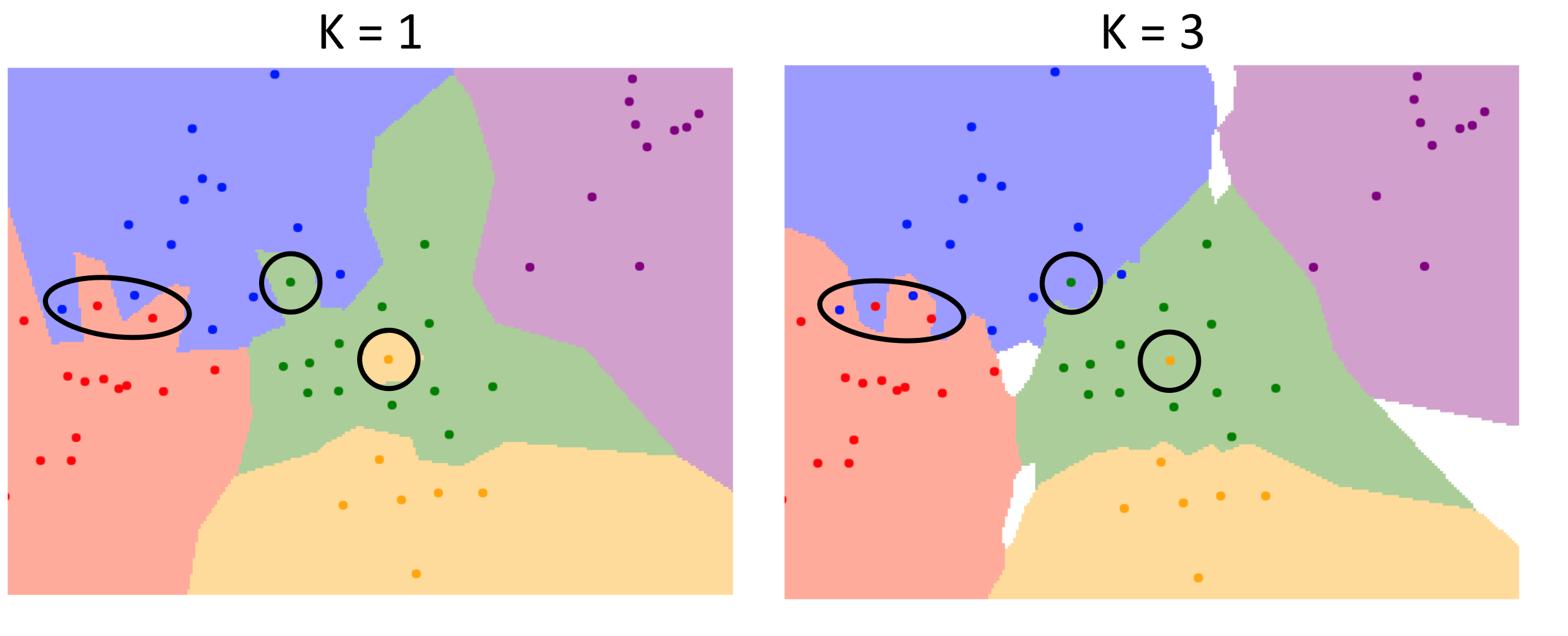
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
물론 이로 인해 어느 카테고리도 정해지지 않은 공백 지역이 생깁니다.
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
그러므로 K개를 엄청 크게 늘릴수 없기에 최적의 K를 찾기 위해서 계속 연구 중입니다.
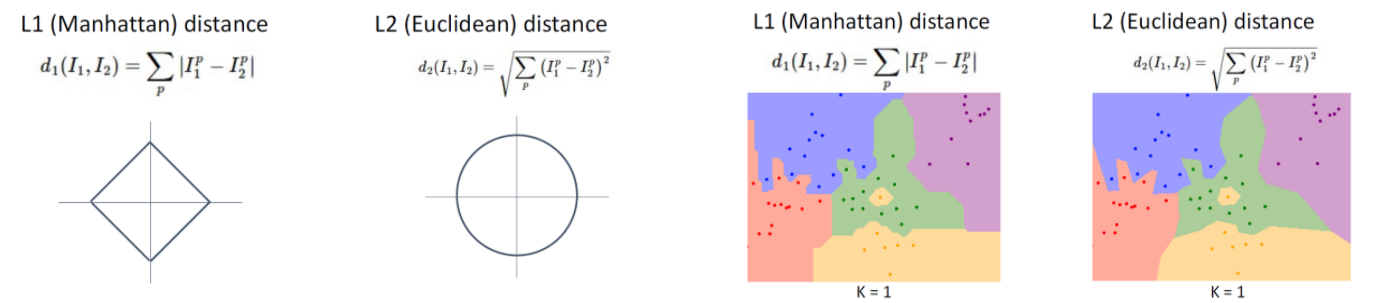
Distance Metrics
NN이야기할 때 배웠던 거리 행렬을 기억하시나요? 결정영역은 거리 행렬에 따라서 모양이 조금씩 달라지는데 2차원 데이터에서 L1 사용 시 수직이나 수평과 평행하게 45각도를 이루지만 L2를 사용하면 제약없이 형성이 됩니다.
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
이렇게 단편적으로만 보면 L2가 가장 좋아보일 수 있지만 상황에 따라 L1이 좋을 때도 있어서 상황에 따라 맞게 잘 사용해야 합니다.
그러나 하나 확실한 것은 적절한 거리 행렬과 KNN 알고리즘을 이용하면 어떤 데이터가 들어와도 좋은 결과를 나타낼 수 있게 됩니다.
*거리행렬과 모델을 설정하여 실제로 직관적 실습을 할 수 있는 코드 입니다.
http://vision.stanford.edu/teaching/cs231n-demos/knn/
Hyperparameters
이제는 하이퍼파라미터라는 인공지능에서 가장 중요하고 필요한 것을 배우게 되니 집중해주시길 바랍니다.
중요한 이유는 모델이 learning을 할 때 효과를 좋게 하는 변수이기 때문입니다.
Hyperparameter란 학습 데이터를 통해서 Training을 하는 것이 아닌 사전에 미리 정한 parameter를 말하고 보통 모든 경우를 포괄하는 최적해는 존재하지 않게 됩니다.
그래서 Hyperparameter을 정할 때는 직접 값을 변경하면서 해본 후에 최고의 parameter 선택해야합니다.
parameter은 서브 인풋 같은 것입니다.
예시를 들자면, KNN의 K값과 distance metric입니다.
Hyperparmeter선택 방법
주어진 데이터에 가장 적합한 하이퍼파라미터 정하기
직관적으로 보기엔 가장 좋아보이지만 예측을 해야하는 상황에선 사전 훈련 데이터에 없던 것으로 입력 데이터가 들어오면 잘 작동할 수 없고 노이즈 문제에서도 자유롭지 못합니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
데이터를 학습(train) 과 실험(test)로 나눈 후에 학습
데이터로 모델 학습시켰을 시에 실험 데이터를 예측했을 때 최고의 결과를 내는 방식입니다.
맨 처음 방식보다는 좋을 수 있지만 결국 실험 데이터에만 의존을 하는 결과를 내기에 너무 이상하게 잘된 현상인 overfitting을 불러 일으킬 수 있습니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
데이터를 train, validation, test로 나누는 방식
모델을 먼저 훈련시킨 후 validation data을 통해서 제일 좋은 hyperparameter를 정한 후에 test를 하면 두번째 방식처럼 test data만 의존하지 않게 됩니다.
그러므로 overfitting문제를 해결할 수 있게 됩니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
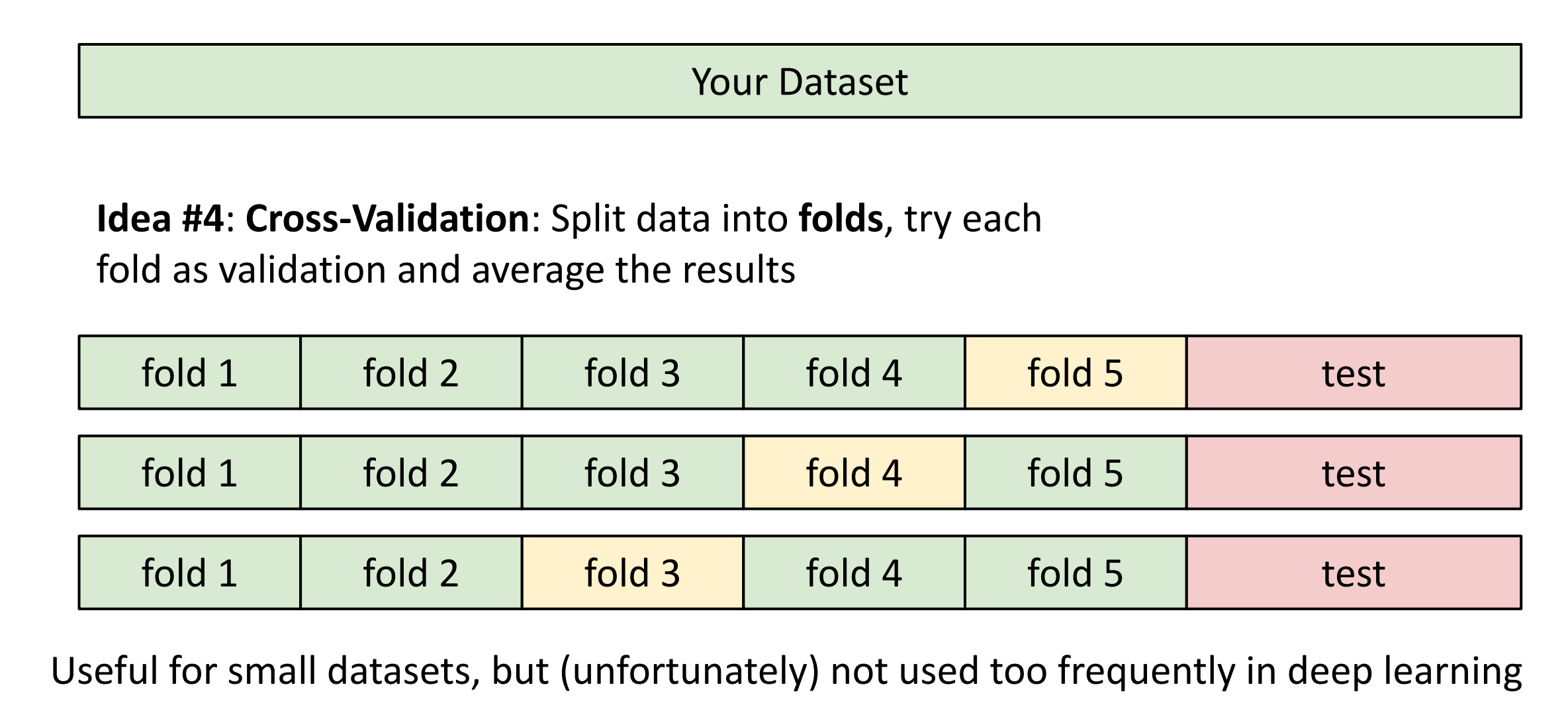
데이터와 data set을 train 과 test으로 나눈다음에 train을 한 번 더 여러개의 fold로 나누기
그리고 fold를 번갈아가며 validation data로 정하면서 3번의 방식으로 진행이됩니다.
이론적으로는 가장 좋으나 계산량이 너무 오래 걸려서 대규모에선 사용이 안됩니다.
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
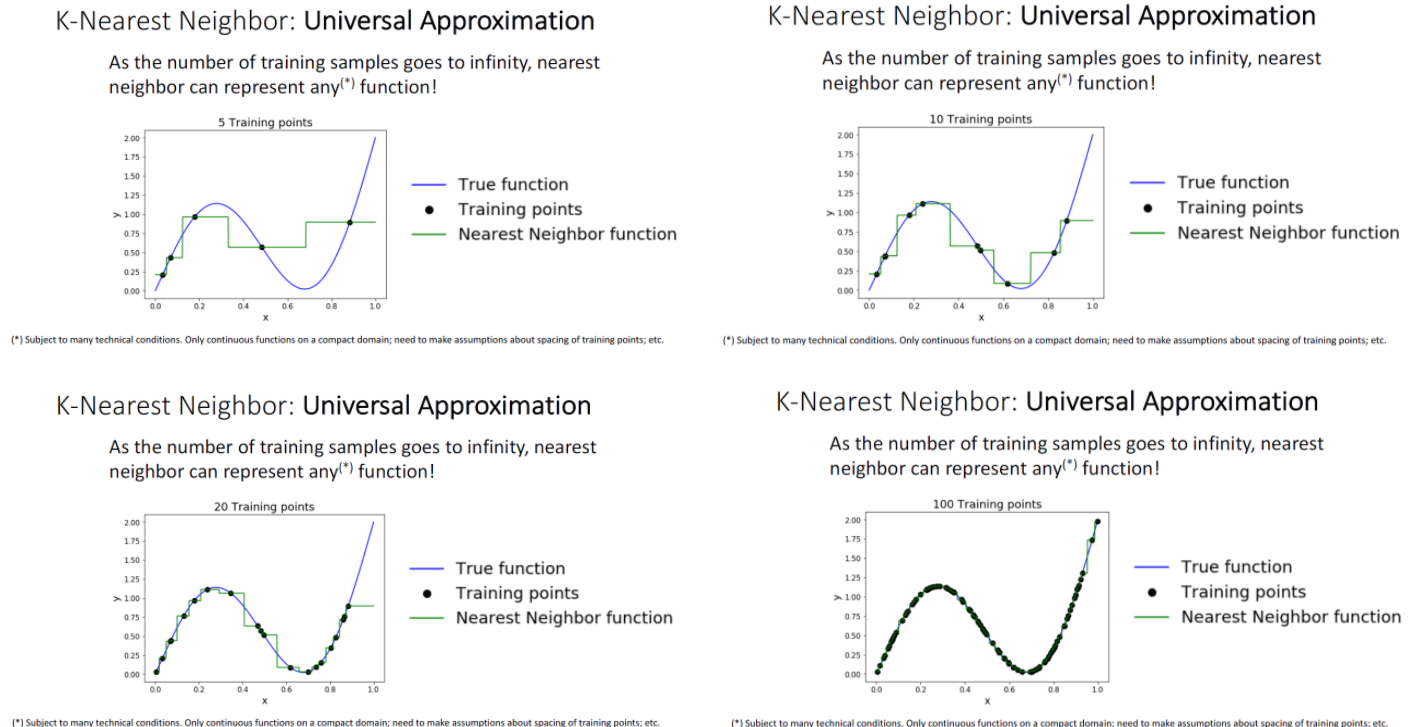
KNN 근사치 찾기
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
KNN는 training sample이 많으면 많을수록 어떤 함수는 표현이 정밀하게 가능하게 됩니다.
머신러닝 모델의 입력이 데이터이고, 출력은 예측값인 함수로도 표현이 가능하여 어느 문제던 처리가 가능하게 됩니다.
차원의 저주
우리가 데이터 차원이 커지고 데이터 양이 많아지면 무조건 좋을 것 같지만 실제로는 그렇지 않은 현상입니다.
특정 data space를 모두 포괄하는 훈련셋이 차원이 증가할 때마다 지수적으로 증가하게 됩니다.

[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
예를 들면, 32 X 32크기의 이진 이미지를 사용하는 경우 존재 가능한 이미지가 너무 크므로 이 이미지가 모든 공간을 감당할 데이터를 모으는 게 불가능하다는 것을 알게됩니다.
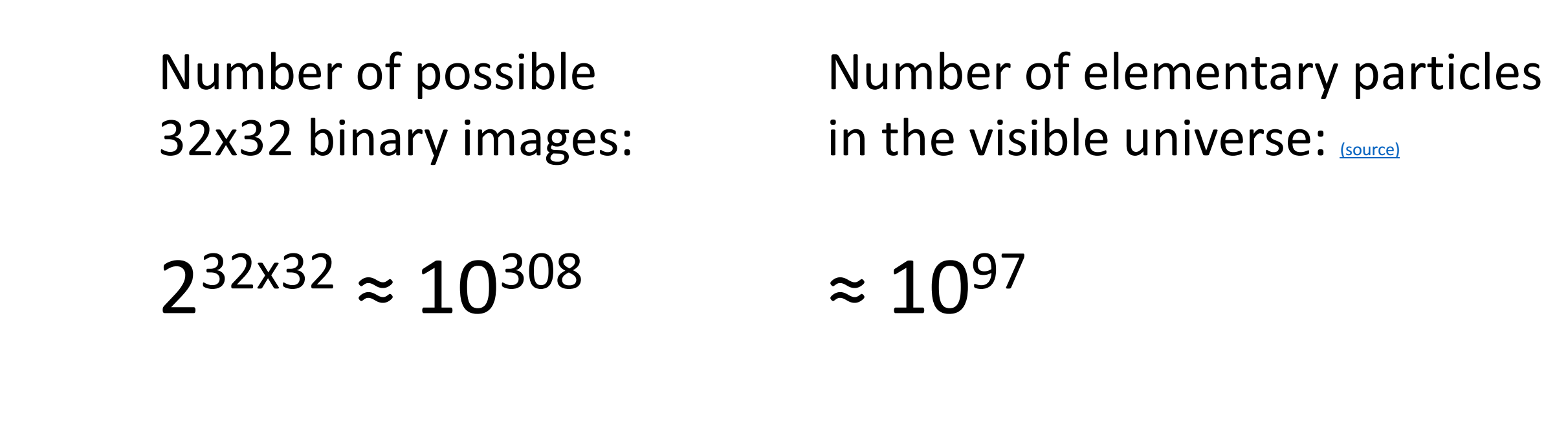
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
KNN의 실용성
데이터가 많으면 많을수록 KNN을 사용하지 않는데 왜냐하면 예측을 하는 시간도 너무 오래 걸리고 예측이 잘 되려면
너무나 많은 데이터 셋이 필요하게되어 차원의 저주에 빠지게 되기 됩니다.
그리고 실험한 결과도 그렇게 유의미함을 나타내지 못하기도 합니다.
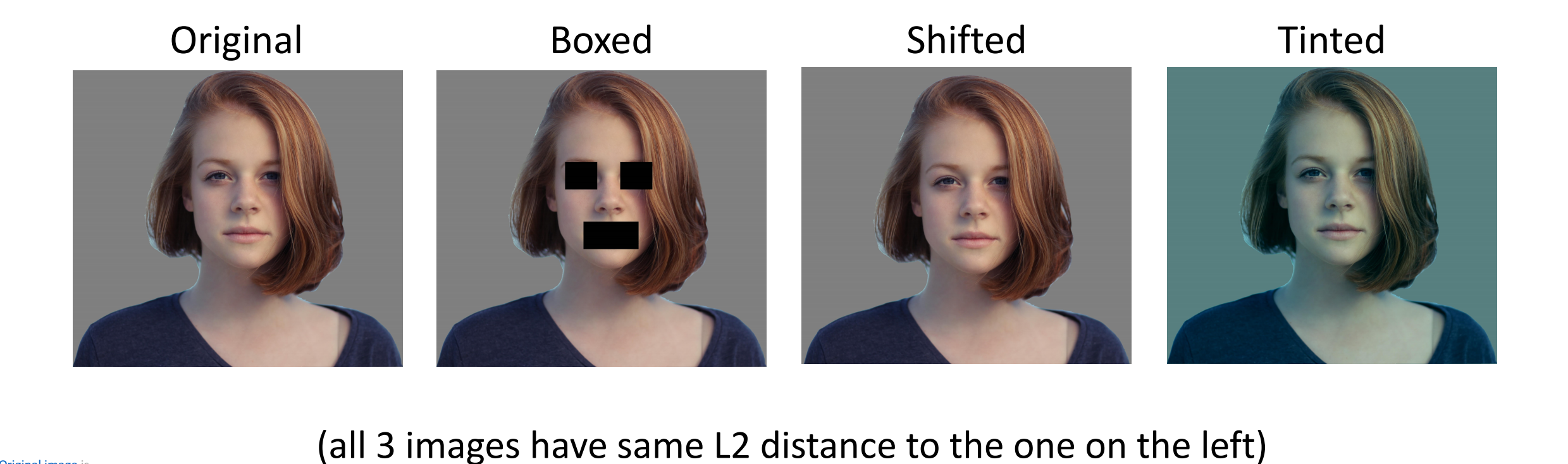
[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
그러나 이러한 문제를 해결하는 방법을 알려드립니다.
해결책
입력 이미지 벡터를 바로 받지 않고 ConvNet을 적용시킨 후에 특성 벡터(feature vector)로 바꾸고 이를 KNN의 입력 데이터로 사용하면 유의미한 결과를 얻게 됩니다.


[저자: Justin Johnson]
[이미지 출처: 링크텍스트]
이번 블로그를 마치려고 합니다. 우리는 지금까지 이미지 분류에 대한 전반적인 큰 틀을 배웠고 다음에는 Linear classifier을 배울 겁니다.

이미지 분류에 대한 큰 그림을 그려주셨네요! 어투가 통일성이 있거나 글의 흐름이 조금만 더 매끄러우면 어떨까 하고 조심스럽게 제안해 볼게요~