여러 가지 시각화 도구
-
Pandas
-
Matplotlib
-
Seaborn
Pandas
- 선 그래프 그리기
-
데이터 정의
:모듈을 import하고 그래프로 그릴 데이터 정의.

- Pandas Series 데이터 활용
-
Series 데이터 활용(선 그래프 그리기 최적 구조)
price = date['Close']
price.plot(ax=ax, style='black') :Pandas의 plot 사용, matplotlibe에서 정의한 subplot공간 ax사용
-좌표축 설정
plt.xlim(), plt.ylim() : x,y좌표축의 적당한 범위 설정
-주석
annotate() :그래프 안에 추가적으로 글자나 화살표 등을 그릴 때 사용
-그리드
grid() : 격자눈금 추가
- pandas. plot 메서드 인자
label: 그래프의 범례이름.
ax: 그래프를 그릴 matplotlib의 서브플롯 객체.
style: matplotlib에 전달할 'ko--'같은 스타일의 문자열
alpha: 투명도 (0 ~1)
kind: 그래프의 종류: line, bar, barh, kde
logy: Y축에 대한 로그스케일
use_index: 객체의 색인을 눈금 이름으로 사용할지의 여부
rot: 눈금 이름을 로테이션(0 ~ 360)
xticks, yticks: x축, y축으로 사용할 값
xlim, ylim: x축, y축 한계
grid: 축의 그리드 표시할 지 여부
- pandas의 data가 DataFrame일 때 plot메서드 인자
subplots: 각 DataFrame의 칼럼을 독립된 서브플롯에 그린다.
sharex: subplots=True면 같은 X축을 공유하고 눈금과 한계를 연결한다.
sharey: subplots=True면 같은 Y축을 공유한다.
figsize: 그래프의 크기, 튜플로 지정
title: 그래프의 제목을 문자열로 지정
sort_columns: 칼럼을 알파벳 순서로 그린다.
-
예시
<막대그래프>
fig, axes = plt.subplots(2, 1)
data = pd.Series(np.random.rand(5), index=list('abcde'))
data.plot(kind='bar', ax=axes[0], color='blue', alpha=1)
data.plot(kind='barh', ax=axes[1], color='red', alpha=0.3)
<선 그래프>
df = pd.DataFrame(np.random.rand(6,4), columns=pd.Index(['A','B','C','D']))
df.plot(kind='line')
ex)
pivot = flights.pivot(index='year', columns='month', values='passengers')
pivot
sns.heatmap(pivot)
sns.heatmap(pivot, linewidths=.2, annot=True, fmt="d")
sns.heatmap(pivot, cmap="YlGnBu")
Matplotlib
- 막대그래프 그리기
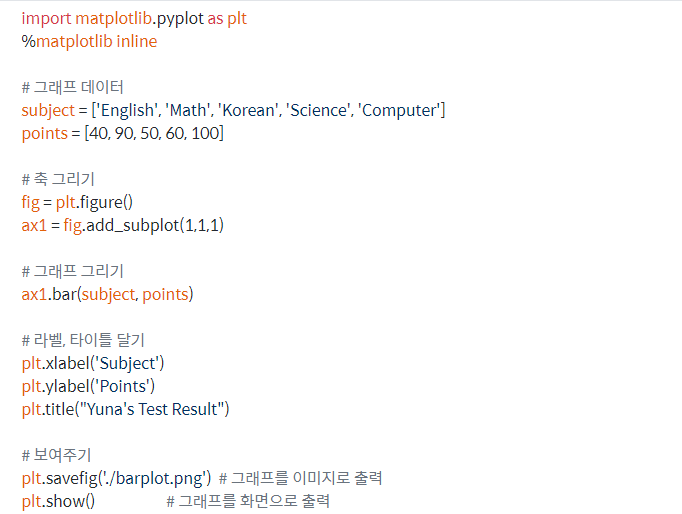
-
%matplotlib inline : IPython 매직 메소드
-
fig = plt.figure(): 데이터 정의
-# 축 그리기
fig = plt.figure() #도화지(그래프) 객체 생성
ax1 = fig.add_subplot(1,1,1) #figure()객체에 add_subplot 메소드를 이용해 축그림
-add_subplot : 그래프를 여러 개 그릴 수 있음
-# 막대 그래프 그리기
-
bar()메소드 추가

그래프 요소 추가
-
xlabel() , ylabel() , title()메소드

Plot 사용법
-
원래 방식: figure()객체 생성 후 add_subplot() 서브 플룻 생성 후 plot 그리기
-
빠른 방식: plt.plot()명령 -> matplolib는 가장 최근의 객체와 서브 플룻 그림.
-
plt.plot() : x데이터, y데이터, 마커옵션, 색상 등의 인자 이용
-
linestyle,marker옵션: 라인 스타일
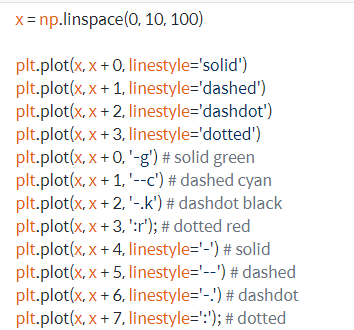
그래프 그리기 정리
-
fig = plt.figure() : figure 객체 선언해서 도화지에 펼쳐줌
-
ax1 = fig.add_subplot(1,1,1) :축을 그림
-
ax1.bar(x,y) 어떤 그래프를 그릴지 메소드 선택 후 인자로 데이터 넣기
4.plt의 메소드로 : grdi, xlabel, ylabel 설정
-
plt.savefig 메소드로 저장.
-
각 요소 명칭
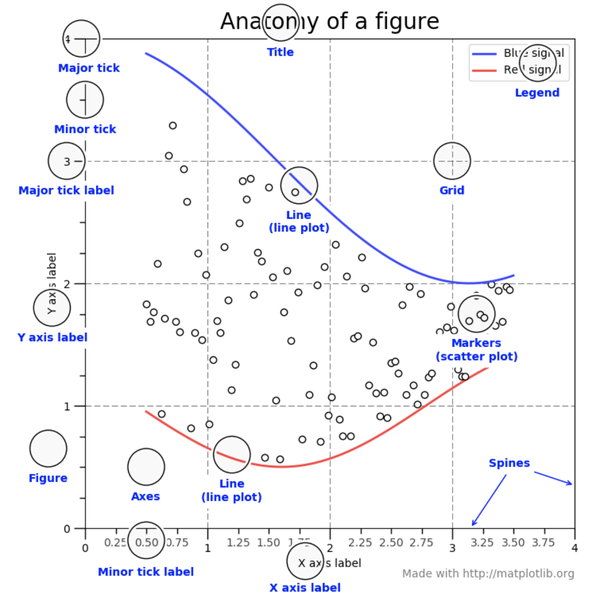
Seaborn
그래프 핵심 TOP 4 정리
-
데이터 준비
1)데이터 불러오기
load_dataset() 메소드 이용하여 예제 다운로드.
import pandas as pd
import seaborn as snstips = sns.load_dataset("tips")
2)데이터 살펴보기(EDA)
i)데이터 구성
df = pd.DataFrame(tips)
df.head()ii) 데이터 모양
df.shape
iii) 데이터 설명
df.describe()
iv) 데이터 정보
df.info()
v)결측치 정보
결측치 있으면 처리 없으면 그냥 진행
vi)범주형 변수의 카테고리별 개수 구하기
print(df['sex'].value_counts())
print("===========================")
-
범주형 데이터
-사용 그래프 : 가로, 세로, 누적, 그룹화된 막대 그래프
2-1) 막대 그래프(bar graph)
2-1-1) Pandas 와 Matplotlib 활용 방안
Matplotlib안에 pandas데이터를 바로 이용할 수 없기 때문에
x를 series 또는 list, y에 list형태로 각각 나눠준다.
df.head() 통해 대략적 확인
padas의 groupby메소드 : 각 그룹에 대한 정보 지정.
grouped = df['tip'].groupby(df['sex'])
import numpy as np
sex = dict(grouped.mean()) #평균 데이터를 딕셔너리 형태로 바꿔줍니다.
sexgrouped.size() # 성별에 따른 데이터 량(팁 횟수)
위의 데이터들을 가지고 평균 막대 그래프 그리기.
import numpy as np
sex = dict(grouped.mean()) #평균 데이터를 딕셔너리 형태로 바꿔줍니다.
sex
x = list(sex.keys())
x
y = list(sex.values())
y
sns.barplot(data=df, x='sex', y='tip')
2-2-2) Seaborn과 Matplotlib
- sns.barplot의 인자에 df 넣고 원하는 컬럼 지정.
sns.barplot(data=df, x='sex', y='tip')
- 그래프에 다양한 옵션 가능.(with Matplot)
plt.figure(figsize=(10,6)) # 도화지 사이즈를 정합니다.
sns.barplot(data=df, x='sex', y='tip')
plt.ylim(0, 4) # y값의 범위를 정합니다.
plt.title('Tip by sex') # 그래프 제목을 정합니다.
- 다양한 방식으로 표현
fig = plt.figure(figsize=(10,7))
ax1 = fig.add_subplot(2,2,1)
sns.barplot(data=df, x='day', y='tip',palette="ch:.25")
ax2 = fig.add_subplot(2,2,2)
sns.barplot(data=df, x='sex', y='tip')
ax3 = fig.add_subplot(2,2,4)
sns.violinplot(data=df, x='sex', y='tip')
ax4 = fig.add_subplot(2,2,3)
sns.violinplot(data=df, x='day', y='tip',palette="ch:.25")
-palette 옵션을 통해 더 이쁘게 만든다.
fig = plt.figure(figsize=(10,7))
ax1 = fig.add_subplot(2,2,1)
sns.barplot(data=df, x='day', y='tip',palette="ch:.25")
ax2 = fig.add_subplot(2,2,2)
sns.barplot(data=df, x='sex', y='tip')
ax3 = fig.add_subplot(2,2,4)
sns.violinplot(data=df, x='sex', y='tip')
ax4 = fig.add_subplot(2,2,3)
sns.violinplot(data=df, x='day', y='tip',palette="ch:.25")
3.수치형 데이터
3-1) 사용 그래프: 산점도 혹은 선 그래프
3-2) 산점도(scatter plot)
sns.scatterplot(data=df , x='total_bill', y='tip', hue='day')
3-3) 선 그래프(line graph)
sns.lineplot(x, np.sin(x))
sns.lineplot(x, np.cos(x))
3-4)히스토그램
:도수 분포표를 그래프화
-용어 정리
-
가로축
++ 계급: 변수의 구간, bin (or bucket)
-
세로축
++ 도수: 빈도수, frequency
-
전체 총량: n
ex) 히스토그램 예시 (x1 평균 = 100, x2 평균 = 130, 표준편차 =15, 도수 = 50)
#그래프 데이터
mu1, mu2, sigma = 100, 130, 15
x1 = mu1 + sigmanp.random.randn(10000)
x2 = mu2 + sigmanp.random.randn(10000)
#축 그리기
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
#그래프 그리기
patches = ax1.hist(x1, bins=50, density=False) #bins는 x값을 총 50개 구간으로 나눈다는 뜻입니다.
patches = ax1.hist(x2, bins=50, density=False, alpha=0.5)
ax1.xaxis.set_ticks_position('bottom') # x축의 눈금을 아래 표시
ax1.yaxis.set_ticks_position('left') #y축의 눈금을 왼쪽에 표시
#라벨, 타이틀 달기
plt.xlabel('Bins')
plt.ylabel('Number of Values in Bin')
ax1.set_title('Two Frequency Distributions')
#보여주기
plt.show()
3-5) 밀도 그래프
df['tip_pct'].plot(kind='kde')
정의: 연속된 확률분포를 나타냄
그리는 방식
-일반적으로 kernels 메서드 섞어서 분포를 근사하는 식으로 그림
-정규분포(가우시안)으로 나타냄
-위 밀도 그래프는 KDE 커널 밀도 추정 그래프
시계열 데이터 시각화
- 데이터 가져오기
csv_path = os.getenv("HOME") + "/aiffel/data_visualization/data/flights.csv"
data = pd.read_csv(csv_path)
flights = pd.DataFrame(data)
flights
-
다양하게 그래프 그리기
2-1) 막대 그래프
sns.barplot(data=flights, x='year', y='passengers')
2-2) 점 그래프
sns.pointplot(data=flights, x='year', y='passengers')
2-3) 선 그래프
sns.lineplot(data=flights, x='year', y='passengers')
2-4) 선 그래프 + 새로운 거 추가
sns.lineplot(data=flights, x='year', y='passengers', hue='month', palette='ch:.50')
plt.legend(bbox_to_anchor=(1.03, 1), loc=2) #legend 그래프 밖에 추가하기
2-5)히스토그램
sns.distplot(flights['passengers'])
