- 데이터 준비하자
라이브러리 설정
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
print("👽 Hello.")
데이터 읽기
import os
csv_file_path = os.getenv('HOME')+'/aiffel/data_preprocess/data/trade.csv'
trade = pd.read_csv(csv_file_path)
trade.head()
결측치(Missing Data)
0.정의 : 누락된 값이 모델의 품질에 큰 영향을 준다
0.0예시(Missing value)
- Missing completely at random(MCAR)
- Missing at random(MAR)
- Not missing at random(NMAR)
1.0.0 데이터셋의 missing value 처리 10가지
i) 아무것도 하지 않기
-
가장 쉬운 방법.
-
결측값 무시 알고리즘(LightGBM의 use_missing = false)
-
일부 알고리즘(xgboost)은 결측 값 고려
-
처리하는 로직이 없는 알고리즘(sklearn의 LinearRegreesion)누락된 데이터 처리
ii) 누락된 데이터를 제거
: 중요한 정보를 가진 데이터 잃을 위험있음.
: tuple제거
: missing value가 많은 feature(column)을 제거
iii) Mean/Median Imputation
:다른 값들의 평균이나 중앙값 대체. 다른 feature고려 되지 않음. 숫자형데이터만 사용
-
장점
+) 쉽고 빠르다. 작은 크기의 숫자형 데이터셋에 잘 동작
-
단점
+) 다른 feature간의 상관관계가 고려 안됨.
+) 단순히 결측지가 존재하는 컬럼만 고려
+) 정확하지 않다.
+) 불확실성에 반대된다.(동일한 값이다.)
+) 인코딩 된 범주형 feature에 대해 안 좋은 결과를 제공한다.
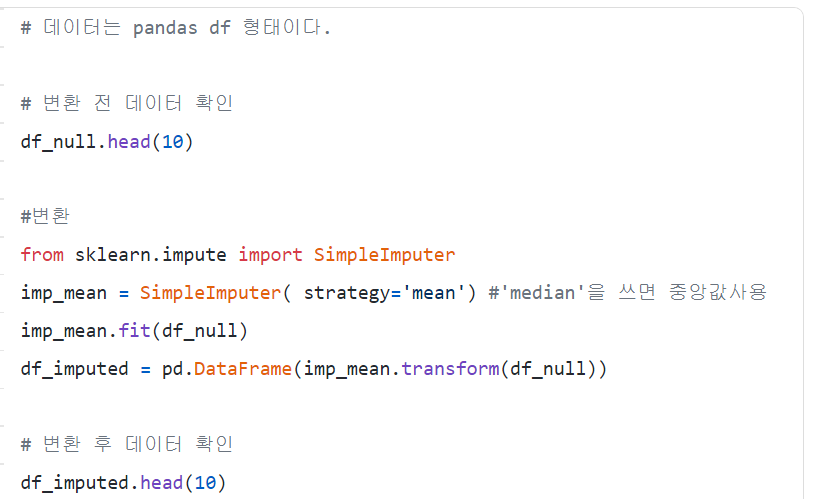
iv) Most Frequent Value / Zero / Constant Imputation
-
Most Frequent Value Imputation: 가장 빈번히 나온 값 대체. 범주형 feature동작
-
Zero Imputation: 말 그대로 0으로 대체
-
Constant Imputation: 지정한 상수값으로 대체
-
장점
: 이것도 쉽고 빠름
: categorical(범주형) feature에 잘 동작함.
-
단점
: 이것 또한 다른 feature간의 상관관계가 고려되지 않음 : 데이터에 bias를 만들 수 있다.
v) K-NN Imputation
: classification에 간단한 알고리즘이다.
: feature similarity -> 가장 닮은 데이터 K를 찾는 방식
: impyute 라이브러리 -> KNN
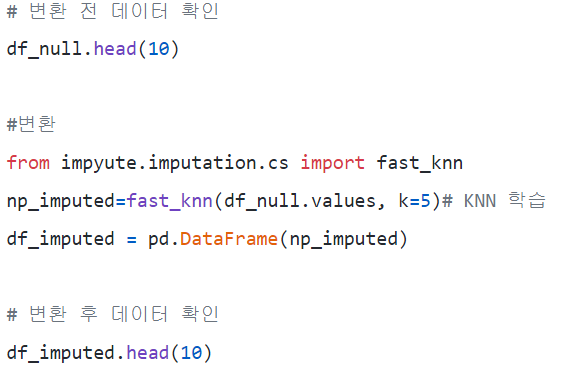
: KDTree 생성 후 가장 가까운 이웃(NN) 찾기
: K개의 NN을 찾은 뒤에는 거리에 따라 가중 평균 취함
-
장점
- mean, median이나 most frequent보다 정확할 때가 많다.(데이터셋에 따라 다름)
-
단점
-
메모리가 많이 필요한다.
-
전체 데이터 세트를 메모리에 올려야한다
-
outlier에 민감
-
vi) MICE(Multivariate Imputation by Chained Equation) Imputation
: 누락된 데이터를 여러 번 채우는 방식
: Multiple Implutation(MI) < Single Imputation (불확실성)
: chained equeation 접근법은 매우 유연해서 연속형, 이진형, 범위형, survey skip패턴 처리

- Imputation : distribution을 토대로 m개의 데이터셋을 imputation
- Analysis: m개의 완성된 데이터셋 분석
- Pooling: 평균, 분산, 신뢰 구간 계산하여 결과를 합침

vii) Deep Learning을 이용한 Imputation / Datawing
:categorical 혹은 non numerical feature에 매우 효과적
:DNN을 이용해서 머신러닝 모델 학습하고 누락된 값 유추
-
장점
- 다른 방법에 비에 꽤나 정확함
- 범주형 데이터(Feature Encoder)를 처리 기능
- CPU, GPU 지원
-
단점
- 한 번에 한 개의 칼럼만 대체 가능
- 대규모 데이터 셋에선 좋지 않음
- 다른 피쳐들은 직접 지정

Viii) Stochastic regression imputation
: 동일 데이터셋에 있는 관련된 다른 피쳐에서 missing value 예측
viiii) Extrapolation and Interpolation
: 이산형 범위 내에 있는 다른 데이터들로부터 값을 추정
x) Hot-Deck imputation
;데이터 셋에서 랜덤하게 선택한다.
-
코드로 결측치(Missing Data)이해하기
i) 결측치의 개수 아는 법
: len(trade) - trade.count()
ii) DataFrame.isnull()
: 데이터마다 결측치 여부를 True, False로 반환
iii) DataFrame.any(axis=1)
: 행마다 하나라도 True가 있으면 True , 그렇지 않은 False
iv) trade[trade.isnull().any(axis=1)]
: DataFrame에 넣어주면 값이 True데이터만 추출
v) dropna
:결측치를 삭제해주는 메서드
vi) subset옵션으로 특정 컬럼 선택
vii) how옵션으로 선택한 컬럼 전부가 결측치인 행 삭제(all)
viii) inplace-> DataFrame내부에 바로 적용
viiii) 예시
trade.dropna(how='all', subset=['수출건수', '수출금액', '수입건수', '수입금액', '무역수지'], inplace=True)
print("👽 It's okay, no biggie.")
trade[trade.isnull().any(axis=1)]
-
수치형 데이터 보완
3-1) 특정값 지정 그러나 결측치가 많아서, 같은 값으로 대체하면 분산 문제 생김
3-2) 평균, 중앙값 대체.
3-3) 다른데이터를 이용해 예측값 대체
3-4) 시계열특성을 가진 데이터를 통해서 결측치 대체
-
범주형 데이터 보완
4-1) 특정 값 지정
4-2) 최빈값등 대체
4-3) 예측값 대체
4-4) 시계열특성을 가진 데이터를 통해서 결측치 대체
-
중복된 데이터
i) 중복된 데이터 확인
: trade.duplicated()
ii) 중복된 데이터 손쉽게 삭제
: trade.drop_duplicates(inplace=True)
-
이상치(Outlier)
-정의 : 대부분 값의 범위에서 벗어나 극단적으로 크거나 작은 값 의미.
-
Min-Max Scaling
:0에 가깝고 이상치만 1에 가까운 값을 가지게 된다.
-
Z-score
i) 가장 간단한 방법으로 삭제 가능
ii) 이상치를 다른 값으로 대체 가능
iii) 예측 모델을 만들어 예측값 활용
iv) binning통해 수치형 데이터를 범주형으로 바꾼다.
v) 코드 예시
abs(df[col] - np.mean(df[col])) : 데이터에서 평균을 빼준 것에 절대값을 취합니다.
abs(df[col] - np.mean(df[col]))/np.std(df[col]) : 위에 한 작업에 표준편차로 나눔
df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index: 값이 z보다 큰 데이터의 인덱스를 추출합니다.
-
IQR method(사분위범위수)
: Z-score 방법의 한계점 해결
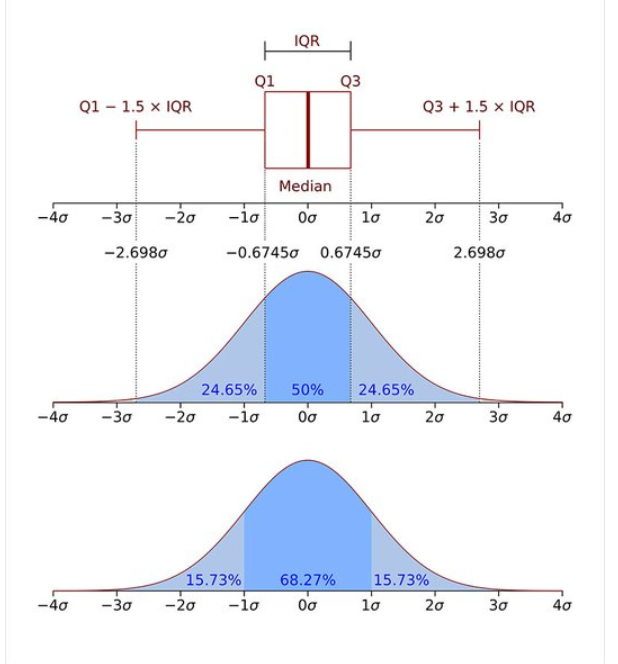
7.정규화(Normalization)
: 컬럼간에 범위가 크게 다를 경우 전처리 과정에서 데이터 정규화.
-
Standardization 데이터 평균은 0 , 분산은 1로 변환
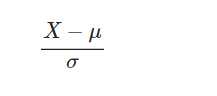
-
Min-Mac Scaling 데이터의 최솟값은 0 , 최댓값은 1
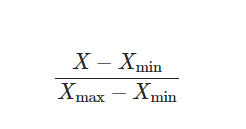

7-1. 정규화 하는 과정
i)임의의 데이터 생성 후 각각의 기법으로 데이터 정규화
#정규분포를 따라 랜덤하게 데이터 x를 생성합니다.
np.random.seed(2020)
x = pd.DataFrame({'A': np.random.randn(100)*4+4,
'B': np.random.randn(100)-1})
x#데이터 x를 Standardization 기법으로 정규화합니다.
x_standardization = (x - x.mean())/x.std()
x_standardization#데이터 x를 min-max scaling 기법으로 정규화합니다.
x_min_max = (x-x.min())/(x.max()-x.min())
x_min_max
-
원-핫 인코딩(One-Hot Encoding)
사용 경우: 머신러닝이나 딥러닝 프레임 워크에서 범주형 지원하지 않을 때 이용
정의: 카테고리별 이진 특성을 만들어서 해당하는 특성(1) 아니면 0
사용: pandas에서 get_dummies함수 사용해서 원-핫인코딩 가능
예시
#trade 데이터의 국가명 컬럼 원본
print(trade['국가명'].head())
#get_dummies를 통해 국가명 원-핫 인코딩
country = pd.get_dummies(trade['국가명'])
country.head()
#pd.concat함수로 데이터프레임 trade와 country합침
trade = pd.concat([trade, country], axis=1)
trade.head()
#필요없어진 국가명 칼럼 삭제 후 원하는 프레임 형성
trade.drop(['국가명'], axis=1, inplace=True)
trade.head()
9.구간화(Binning or bucketing)
:구간별로 데이터를 나누어 분석할 때 사용
-cut함수: 구간별로 나눠줌(함수에 데이터와 구간 입력하면됨)
-qcut함수: 데이터 분포를 비숫한 크기의 그룹으로 나눠줌
