캐글 필사
1.타이타닉 캐글 필사(1) -데이터셋 확인

머신러닝이던 딥러닝이던 가장 먼저해야할 것은 필요할 라이브러리 호출입니다. 물론 보통은 필요한 경우 부르면서 사용합니다.하지만 Numpy, pandas, matplotlib, seaborn과 같은 아주 기초적인 것은 먼저 호출 후에 사용하는 것을 권장합니다. 왜냐하면,
2.타이타닉 EDA
데이터 안에 숨겨진 사실을 시각화를 통해서 찾아야합니다.시각화 라이브러리는 matplotlib, seaborn, plotly등이 있습니다.종류Pclass서수형 데이터 타입(ordinal)카테고리(순서가 있는 데이터 타입)생존률 차이 살피기피벗 차트와 유사하기에 pand
3.EDA(Pclass, Sex, Both sex and Pclass)
서수형 데이터 타입(ordinal)카테고리(순서가 있는 데이터 타입)생존률 차이 살피기피벗 차트와 유사하기에 pandas dataframe의 groupby이용하면 좋다pivot메소드 사용각 pclass마다 0,1로 count되고 평균내면 생존률count()를 사용하여
4.EDA + Feature Engineering01
생존자의 현황 다시 파악한 열씩 검토해 보겠습니다.Survived - Key: (0 - Not Survived, 1- Survived)Survived는 숫자로 값을 주지만 Categorical Variable인 셈입니다.죽던지 살던지 둘 중 하나의 값을 줍니다.coun
5.타이타닉EDA(Age, Pclass, Sex, Age,Embarked)
AgeAge feature살피기생존에 따른 Age의 histogram 그려보기생존자 중 나이가 어린 경우가 많다Class가 높을수록 나이 많은 사람의 비중이 높다나이대가 변하면서 생존률이 어떻게 되는지 보기나이 범위를 넓혀가며 생존률 확인나이가 어릴 수록 생존률이 확실
6.타이타닉 EDA(Family,Fare,Cabin,Ticket)
Family - SibSp(형제 자매) + Parch(부모, 자녀)SibSp와 Parch 합하면 FamilyFamily로 합쳐서 분석FamilySize와 생존 관계Figure(1): 가족의 크기가 1~11대부분 1명 혹은 2~4명입니다.Figure(2),(3): 가족의
7.DieTanic_EDA_Part1
f, ax=plt.subplots(1,2,figsize=(18,8))data'Survived'.value_counts().plot.pie(explode=0,0.1,autopct='%1.1f%%',ax=ax0,shadow=True)ax0.set_title('Survive
8.EDA Part 1 마무리
S에 가장 많은 탑승객이 있고, 대다수가 Pclass3에 속하였습니다.Pclass1과 Pclass2가 구조되기 적절한 위치이다.pd.crosstab(data.SibSp,data.Survived).style.background_gradient(cmap='summer_r'
9.DieTanic_Part2
주어진 데이터셋은 중요한 특징도 있고 그렇지 않은 특징도 있습니다.다른 특징으로부터 정보를 탐색하고 추출하여 새로운 features를 얻거나 추가할 수도 있습니다.이렇게 features를 다루는 과정이므로 매우 중요합니다.Agecontinous featureContin
10.Predictive_Modeling(Cross validation전)
Logistic RegressionSupport Vector Machines(Linear and radial)Random ForestK-Nearest NeighboursNaive BayesDecision Trestrain,test=train_test_split(data
11.Predictive Modeling의 cross validation
Cross validation
12.Predictive_Modeling의_confusion_matrix
분류기에 의해서 정확하게 분류했는지 아닌지를 값을 통해서 보여줍니다.머신러닝 모델은 블랙박스와 비슷합니다.그래서, 파라미터 값은 블랙박스의 초기값이기에 변화를 주어 더 나은 성능을 얻기도 합니다.예를 들어, SVM의 C와 감마같은 것입니다.
13.Predictive Modeling의 Ensembling
모델의 정확도와 성능을 높이는데 좋은 방식으로 다양한 모델을 결합하여 하나의 강력한 모델을 만드는 방식입니다.단순하고 다양한 머신러닝 모델의 prediction를 합치는 방식입니다.(가장 단순함)이를 통해서, 평균적인 예측값 결과를 할 수 있습니다.
14.Titanic Top 4% with ensemble modeling(1)
Feature analysis Feature engineeringModelingtrain = train.drop(Outliers_to_drop, axis = 0).reset_index(drop=True)train_len = len(train)dataset = pd.co
15.Titanic Top 4% with ensemble modeling(2)
Filling missing values Age
16.Titanic Top 4% with ensemble modeling(3)
Modeling
17.Introduction to Ensembling/Stacking in Python
Introduction Feature Exploration, Engineering and Cleaning Feature Engineering Visualisations
18.Ensembling & Stacking models
extend the inbuilt methods (such as train, predict and fit) common to all the Sklearn classifiers.
19.Interactive Porto Insights-A Plot (1)
A
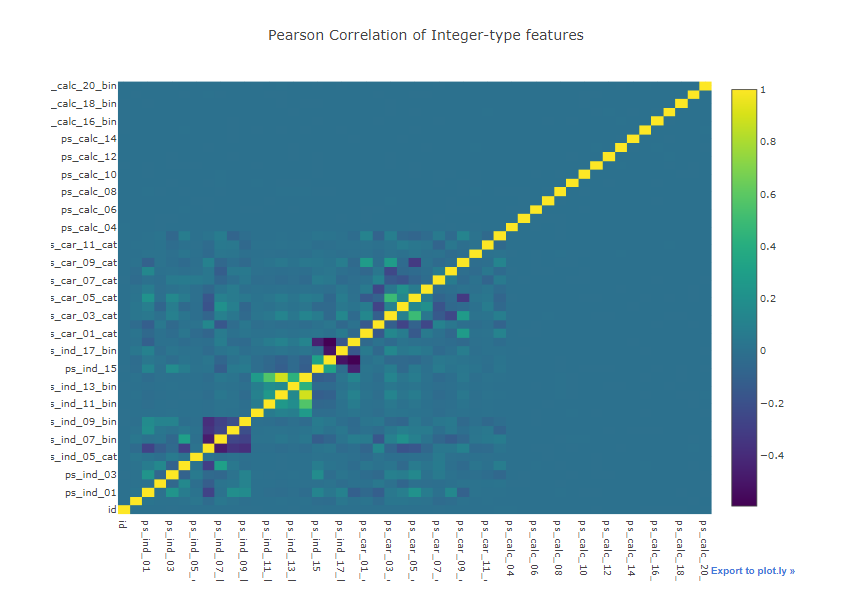
20.Interactive Porto Insights-A Plot (2)
직관적인 시각화 plots를 시도해 볼 것입니다.그래프적 시각화부터 통꼐적 시각화까지 API를 활용해 볼 것입니다.사용할 plotsSimple horizontal bar plot : Target variable distributionCorrelation Heatmap
21.XGBoost CV (LB .284)
IntroXGBoost를 이용하여 validation prediction을 스택킹하고 어셈블링합니다 그 후에 submission file를 만들어 보는 실습을 해봅니다.
22.Porto_Seguro_Exploratory_Analysis_and_Prediction
Rules postfix bin : binary features postfix cat : categorical features features without bin and cat: continous values of ordinal values missing v
23.Porto_Seguro_Exploratory_Analysis_and_Prediction(Data analysis and staticts)
Features with missing valuesps_reg_o3, ps_car_12, ps_car_14 : missing valuesRegistration featureps_reg_01 , ps_reg_32: fractions with denominator 10Ca
24.Porto_Seguro_Exploratory_Analysis_and_Prediction(Binary features)
Binary features Categorical features Data unbalance between train and
25.Porto Seguro Exploratory Analysis and Prediction_prepare the model
Stacking model이란 방식을 통해서 모델을 쌓으면 성능 향상을 이룩할 수 있다 왜냐하면, 좋은 것을 여러 개 모았기 때문입니다. 단, 연산량이 많아지는 건 주의해야합니다.참고: 링크텍스트\*CodeSpliit data in KFoldstrain the mode
26.Porto_Seguro’s Safe Driver_Prediction
def add_noise(series, noise_level): return series (1 + noise_level np.random.randn(len(series)))def target_encode(trn_series=None,
27.Introduction_Home_Credit_Default_Risk_Competition_load_data
\*GoalThe historical loan application is used data to predict probability of replaying a loan\*Supervised classification taskapplication_train/applic
28.Home Credit Default Risk Competition_EDA(1) and Check Column Types
Calculate statisticsMake figurestrends, anomalies, patterns or relationshipsInform modeling choicesFind areas of dataPrediction of Target 0: the loan
29.Home_Credit_Default_Risk_Competition_EDA(2)_label encoding and One hot encoding , Align
머신러닝 모델은 범주형 변수를 이용하면 학습을 시킬 수 없습니다.(단, LightGBM같은 모델 제외, LGBM,CatBoost논문 읽기)이런 이유로, 범주형 변수를 이산 변수로 바꾸는 encoding과정을 거쳐야합니다.Label encoding상수를 통해서 범주형 변
30.Home_Credit_Default_Risk_Competition_EDA(4)
나이에 따른 Repayment 현황을 체크하는 부분입니다.plt.style.use('fivethirtyeight')plt.hist(app_train'DAYS_BIRTH' / 365, edgecolor = 'k', bins=25)plt.title('Age of Clien
31.E_commerce데이터 활용하기
캐글에 있는 데이터를 활용하여 고객 분류(신/구)를 위한 데이터 전처리와 feature enginnering 그리고 시계열 데이터 시각화를 진행할 것입니다.더 나아가 EC3 / EC2를 활용해서 배포까지 하고 싶습니다.ContextTypically e-commerce
32.Kaggle 도전기
저는 플랫폼 데이터를 기반으로 추천시스템을 만드는 것에 관심이 많습니다.그러던 와중 캐글에서 H&M의 데이터를 가지고 상품 추천을 하는 것이 있어서 약 2주 정도 남았기에 힘들겠지만 시작하려고 합니다.첫 캐글부터 빡세지는 않을까 걱정이지만 재미있을 것 같습니다.캐글 대
33.H&M_data_load
NOTE: 7일 동안 구매를 진행하지 않는 고객은 스코어를 초과한 상태일 것입니다. 패션 취향을 추천하는 대회입니다.그래서 그런지, 데이터의 구성도 특이하고 재미있씁니다.articles.csv: detailed metadata for each article_id ava
34.Home Credit Default Risk
데이터 로드부터 Feature_engineering 부분을 다룬 것입니다.캐글 필사를 마치면, 데이터 집산, merge, iterate에 대해서 다룬 블로그를 만들 것입니다.링크텍스트