Pclass
-
서수형 데이터 타입(ordinal)
-
카테고리(순서가 있는 데이터 타입)
-
생존률 차이 살피기
-
피벗 차트와 유사하기에 pandas dataframe의 groupby이용하면 좋다
-
pivot메소드 사용
-
각 pclass마다 0,1로 count되고 평균내면 생존률
-
count()를 사용하여 각 class의 몇 명인지 확인도 가능
-
sum을 사용하여 216명 중 생존한 사람 총합
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).count()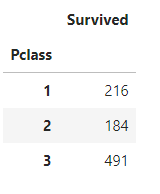
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).sum()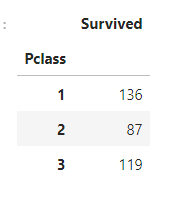
pd.crosstab(df_train['Pclass'], df_train['Survived'],margins=True).style.background_gradient(cmap='summer_r')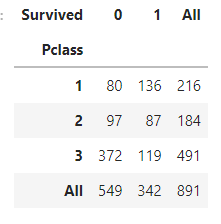
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).mean()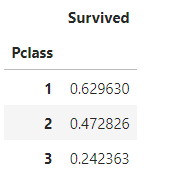
df_train[['Pclass','Survived']].groupby(['Pclass'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar()
#Pclass가 좋을수록 생존률이 높다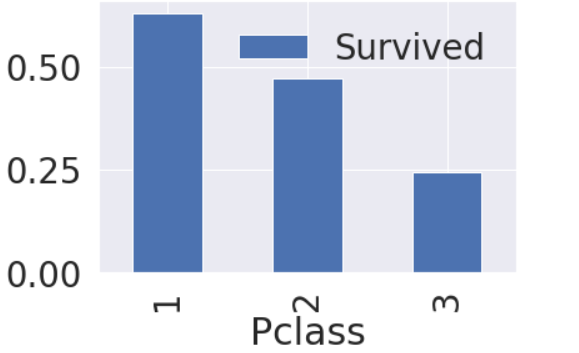
#seaborn의 countplot이용
y_position = 1.02
f, ax = plt.subplots(1, 2, figsize=(18,8))
df_train['Pclass'].value_counts().plot.bar(color=['#CD7F32','#FFDF00','#D3D3D3'], ax=ax[0])
ax[0].set_title('Number of Passengers By Pclass', y=y_position)
ax[0].set_ylabel('Count')
sns.countplot('Pclass', hue='Survived', data= df_train, ax=ax[1])
ax[1].set_title('Pclass: Survived vs Dead', y=y_position)
plt.show()
#클래스가 높을 수록 생존 확률이 높다.
# 생존에 Pclass가 가장 큰 영향을 끼친다는 인사이트를 얻을 수 있습니다.
# 이를 통해 feature를 사용하는 것이 가장 좋다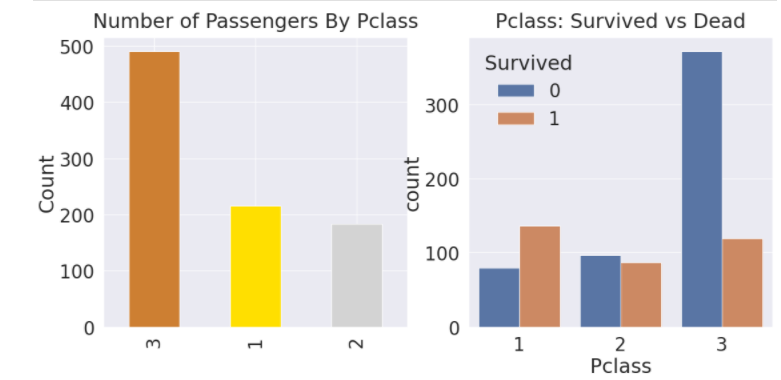
Sex
-
성별로 생존률이 어떻게 다른지 확인
-
pandas groupby와 seaborn countplot사용하여 시각화
f, ax = plt.subplots(1, 2, figsize=(18,8))
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=True).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex')
sns.countplot('Sex', hue = 'Survived', data = df_train, ax=ax[1])
ax[1].set_title('Sex: Survived vs Dead')
plt.show()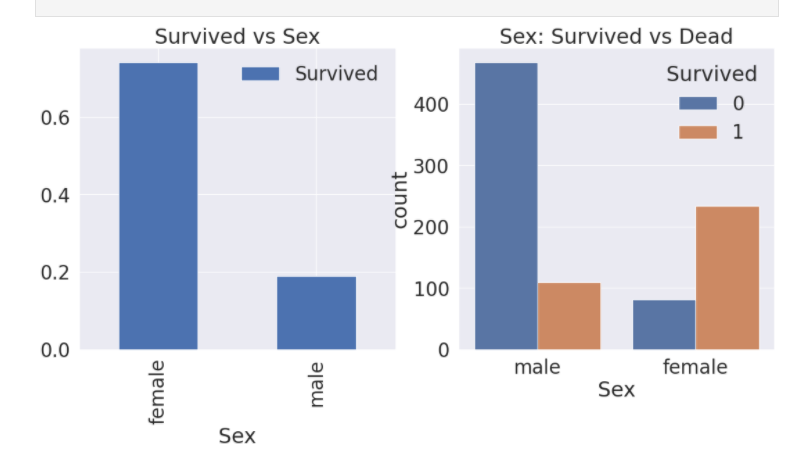
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)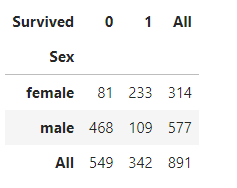
Both Sex and Pclass
-
Sex, Pclass 두 가지 관하여 생존이 어떻게 달라지는지 확인
-
seaborn의 factorplot사용하면 3차원 그래프 가능
-
여성이 남성보다 높다
-
성별 상관없이 클래스가 높을 수록 높다
sns.factorplot('Pclass', 'Survived', hue='Sex', data = df_train, size=6, aspect=1.5)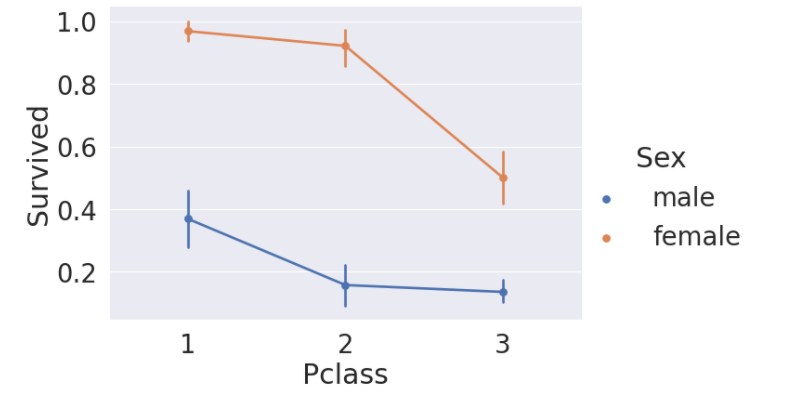
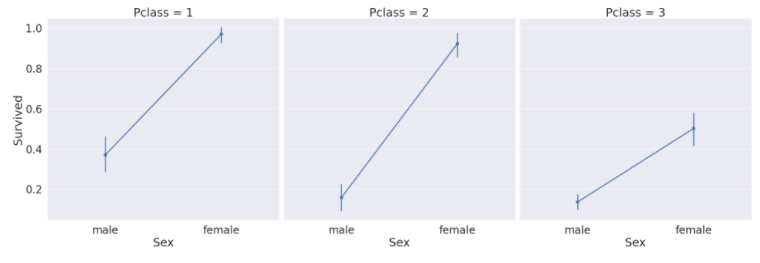
#hue 대신 column사용
sns.factorplot(x='Sex', y='Survived', col='Pclass',
data=df_train, satureation=.5,
size=9, aspect=1
)

성장을 도울 아카이빙 블로그