Survived
- 생존자의 현황 다시 파악
한 열씩 검토해 보겠습니다.
Survived - Key: (0 - Not Survived, 1- Survived)
Survived는 숫자로 값을 주지만 Categorical Variable인 셈입니다.
죽던지 살던지 둘 중 하나의 값을 줍니다.
countplot을 그려 봅니다.
사이즈는 가로 10인치 세로 2인치
생존 여부 0과 1의 숫자를 세어 본 후 그림을 그리도록 명령을 하는 것입니다.
pyplot(plt)의 figure라는 메소드를 써서 그림판의 크기를 정하고, seaborn의 카운트플롯을 그리라는 것입니다.
fig = plt.figure(figsize=(10,2))
sns.countplot(y='Survived', data=train)
print(train.Survived.value_counts())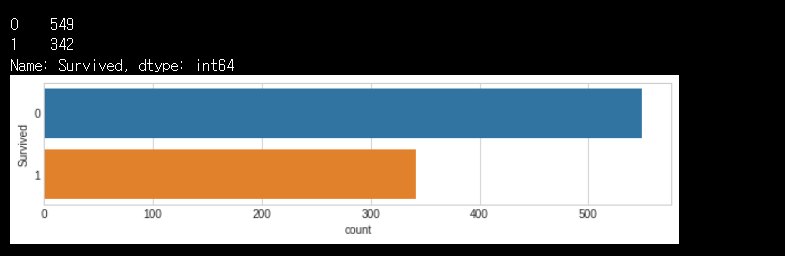
-
불행히도 사망자가 훨씬 많아 보입니다.
-
전체 사망자 비율을 좀 보겠습니다.
-
파이그래프랑 카운트 플롯을 서브플롯으로 그립니다.
-
행은 하나 열은 2개의 서브 플롯입니다. 사이즈는 가로 15인치 세로 6인치
-
'Survived'의 값을 카운트해서 파이플롯을 만듭니다.
-
explode는 폭발하는 것이니까 1이면 튀어 나가는 것인데 0을 주면 분리만 되고 돌출은 되지 않습니다. 이어서 0, 1인 것은 첫 번째 것은 아니고 두번 째 것은 분리된다는 의미로 생각하시면 됩니다.
-
autopercent는 1.1이 표현하는 부분은 소수점 한 자리까지 보여 주라는 의미입니다. 뒤에 점 이하가 4면 둘 다 소수점 4자리수 까지 보여 줍니다.
-
ax[0]은 첫번째 칸입니다.
-
set_title 메소드는 서브 플롯의 제목을 보여 줍니다.
f,ax=plt.subplots(1, 2, figsize=(15, 6))
train['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot('Survived',data=train, ax=ax[1])
ax[1].set_title('Survived')
plt.show()
Pclass EDA
- 선상 등급의 현황 파악
"Pclass" 분석
Pclass는 값이 숫자이나 서열이 정해진 Ordinal Feature이다.
Key:1 = 1st, 2= 2nd, 3 = 3rd
각 클래스 당 생존자를 보겠습니다.
-
groupby 메소드
- train.groupby 그룹을 지어서 통계를 내라
- train.groupby(['Pclass','Survived'])선실등급과 생존율을 묶어라
- train.groupby(['Pclass','Survived'])['Survived'].count() 트레인 셋에서 선실 별 0 과 1의 숫자 세어보라
train.groupby(['Pclass','Survived'])['Survived'].count()
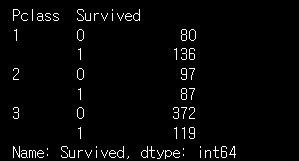
- train.groupby(['Survivied','Pclass'])['Pclass'].count()
<br>
- crosstab 메소드
pd.crosstab(train.Pclass, train.Survived, margins=True).style.background_gradient(cmap='summer_r')
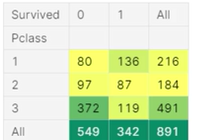
<br>
- 총 정리
f, ax = plt.subplots(1, 2, figsize=(12, 6))
train[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived per Pcalss')
sns.countplot('Pclass', hue='Survived', data=train, ax=ax[1])
ax[1].set_title('Pcalss Survived vs Not Survived')
plt.show()
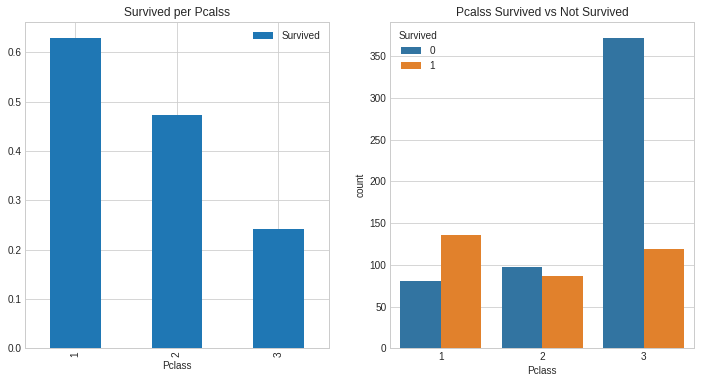
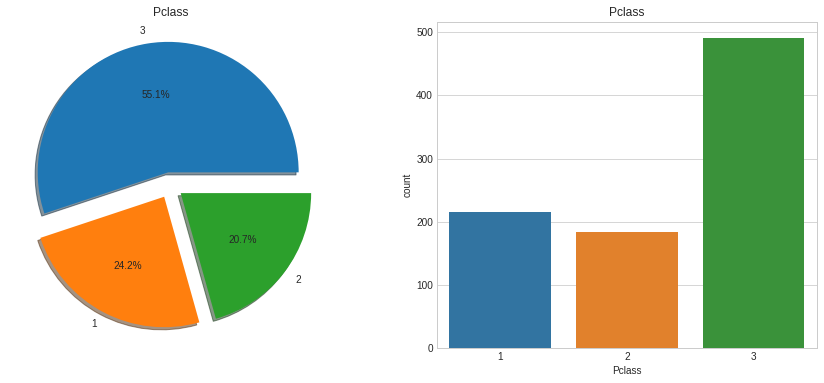
<br>
#### Name EDA + Feature Engineering
- EDA뿐만아니라 약간의 피쳐엔지니어링까지 경험
<br>
#### SEX EDA + Feature Engineering
- Sex에 대해 EDA에 살짝의 변형을 가진 작은 피쳐 엔지니어링 시도