기간:2022.04. 26 ~ 2022.05.03
Q6. 공분산과 상관계수는 무엇일까요? 수식과 함께 표현해주세요.
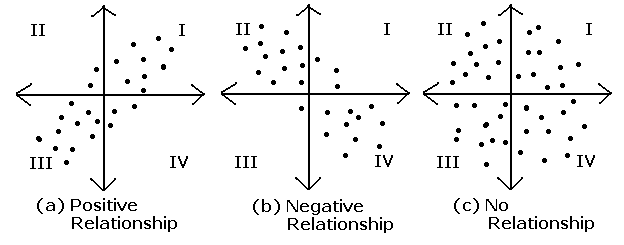
공분산은 X와 Y의 선형관계를 이룬다고 했을 때, X의 증감이 Y의 증감 경향을 측정하는 것으로 쉽게 말하면, 확률변수의 흩어진 정도를 말할 수 있습니다. 즉, 두 변수간의 양의 상관관계가 있는지 음의 상관관계가 있는지에 대한 정도를 아래의 그림처럼 알려주지만 그림처럼 둘 사이의 상관관계가 얼마나 큰 지는 알 수 없습니다.
공식 설명

개인적인 질문) 왜? 공분산이 상관관계의 크기를 알 수 없던 이유!
공분산은 확률변수의 단위가 클수록 잡지 못하는 경향성을 보였기에 큰 단위의 경우 상관관계를 보지 못했습니다. 그래서, 그것을 극복하기 위한 개념인 상관계수가 등장하게 되었습니다.
상관계수(p)는 양/음의 상관관계가 있을 때 얼마나 그 상관성이 큰지도 알려줍니다.
상관계수의 값별 의미: 범위는 -1<= p <=1이고, -1 또는 1에 가까울수록 상관성이 크고, 0에 가까울수록 상관성이 작습니다.
그러면, 공분산 공식에서 편차를 나눠준 것이 왜 경향성 파악이 가능하고 스케일도 줄인 것일까요?
편차는 한 확률변수가 얼마나 평균으로 부터 떨어져있나의 측도로 편차를 나누게 되면 마치 데이터 정규화처럼 경향성은 그대로이고, 수치가 줄어들게 되면서 스케일이 조정이 되는 효과가 있기 때문입니다.
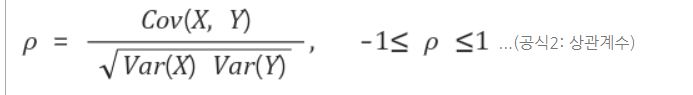
상관계수의 종류로는 피어슨 상관계수, 스피어만 상관계수, 켄달 상관계수 등이 있고 이는 나중에 자세히 알려드리겠습니다.
간단한 정의로만 설명하면, 피어슨 상관계수는 선형관계의 정도를 파악하고 스피어만과 켄달은 단조관계의 정도를 파악합니다.
Q7. 신뢰 구간의 정의는 무엇인가요?
신뢰 구간을 들어가기 전 모수라는 개념이 중요해서 모수를 먼저 설명하겠습니다.
모수는 모집단의 전수조사를 통해서 모집단의 특성을 보여주는 값으로 평균,분산 같은 것으로 이 수를 조사하면 모집단의 특성을 알 수 있습니다.
그렇기에 모수를 알게 되면, 집단의 특성을 알게 되므로 굉장히 중요하고 필요한 값입니다.
그렇다면, 이 값을 어떻게 찾아야할까요? 그것이 바로 신뢰구간이 나오게된 이유입니다.
신뢰구간은 모집단의 모수가 위치해 있을 것 같은 범위를 추정하고 그 확률을 구하는 것입니다.
모수를 신뢰할 수 있어야 그 모집단에 대한 정확한 해석이 가능하기 때문에 신뢰구간이 중요합니다.
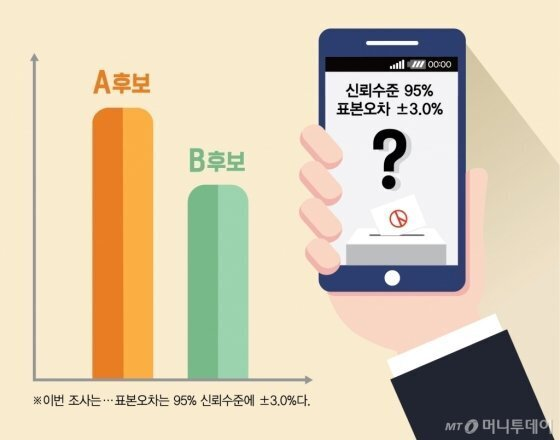
개인적인 질문) 신뢰구간 95%면 무조건 모수 값이 95%확률로 있나요?
추가적인 이야기를 하자면, 신뢰구간의 확륭이 95%라는 말은 모평균(m)이 포함될 확률이 95%가 되는 구간이 아니라 같은 방법으로 100번 시행 시 95개 정도가 그 구간에 있을거다라는 말입니다. 왜냐하면, m은 이미 정해진 값으로 가변성이 아니기 때문입니다.
그러므로, 신뢰수준은 방법의 정확도, 참 값을 구하기 위해 반복 시행 시 참값이 특정 범위에 있을 비율입니다.
필사로 이해하기

이러한 개념을 바탕으로, 최근에 있었던 출구조사에서 대통령 당선인예측 값을 구한 것입니다.
Q8. p-value를 모르는 사람에게 설명한다면 어떻게 설명하실 건가요?
개인적인 질문) p-value를 알기 위한 사전 지식이 뭘까요?
p-value를 알기 전 사전 지식이 필요합니다. 그것은 바로 1&2종 오류, 귀무가설, 대립가설, 유의수준입니다.
귀무가설(null hypothesis): 가설을 세우고 입증을 할 때 처음 가설을 귀무가설이라고 합니다.
대립가설(alternative hypothesis): 귀무가설의 반대되는 가설을 대립가설입니다.
예시)
귀무가설: 20대 남자들과 30대 남자들의 키가 같을 것이다.
대립가설: 20대 남자들과 30대 남자들의 키가 다를 것이다.
1종 오류: 귀무가설이 참인데 기각
2종 오류: 귀무가설이 거짓인데 기각하지 않는 경우
유의 수준(significant level) : 1종 오류를 범할 수 있는 최대 허용 한계
예시)
유의수준 = 0.05라면 100번 중 최대 5번까지 실수해도 허용한다
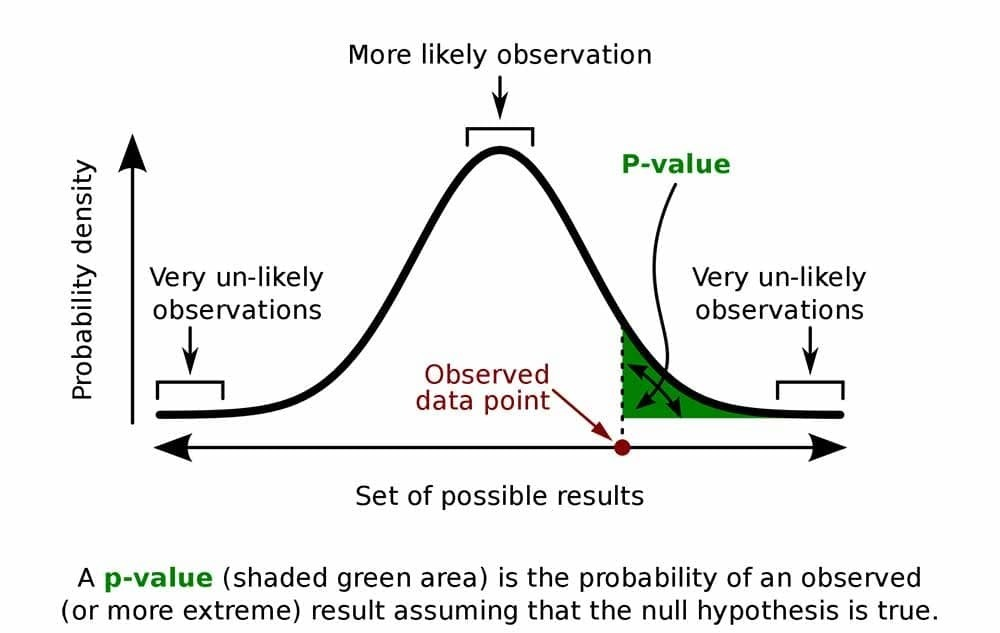
이제부터 p-value로 들어가보겠습니다.
p-value는 1종 오류를 범할 확률입니다.
*그래프로 보는 p-value
*공식으로 보는 p-value

Q9. R square의 의미는 무엇인가요?[회귀분석에서 중요]
독립변수: 다른 변수의 변화와 관계없이 독립적으로 변하기에 다른 변수의 값을 결정하는 변수입니다.
종속변수: 독립변수에 의해 결정되는 변수를 종속변수입니다.
결정계수(R-squared)의 정의는 독립변수가 종속변수를 얼마나 설명을 해주는 지표로 설명력이라고 불립니다.
결정계수가 높다면 독립변수가 종속변수를 많이 설명하는 것이기에 독립변수의 증가하면 결정계수가 높아집니다.
즉, 총 변동 사항 중에 설명 가능한 수치의 비율 입니다.
ex)결정계수 = 0.3 이라면, 독립변수가 종속변수의 30%정도를 설명한다고 이야기를 합니다. 그렇다면, 몇 퍼센트 이상이면 실용적인가요? 라는 질문에는 연구 분야와 연구자 판단에 따라 차이가 있으나 보통 결정계수=0.2를 넘어야한다고는 합니다.
*공식
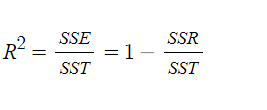
*그림으로 보기
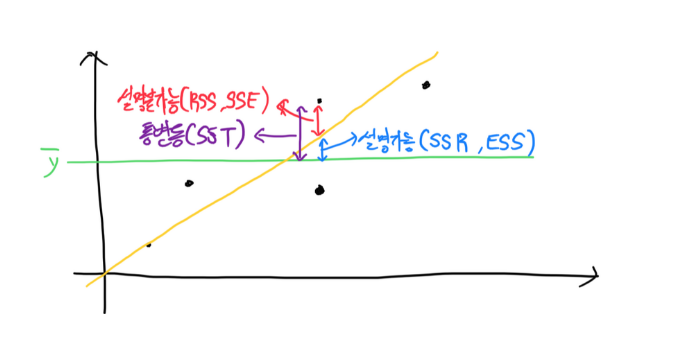
선형 직선은 회귀선입니다.
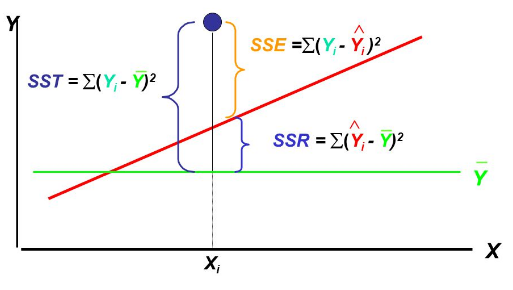
SST: 총 변동사항의 합(SSE+SST)로 y값들의 평균값과 실제 y값의 차이를 말합니다.
SSR: 분석을 통해서 설명이 가능해진 수치입니다.
SSE: 분석을 통해서 설명이 불가능한 수치입니다.
R을 통한 예시
회귀분석을 위해 lm함수, 종속변수는 wage, 독립변수는 educ, exper, tenure
model<-lm(wage ~ educ + exper + tenure, data=data)
summary(model)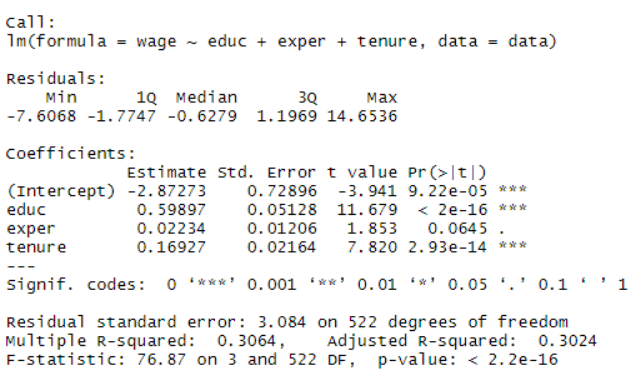
SST<-sum((data$wage-mean(data$wage))^2) #7160.41429098188
SSE<-sum((model$fitted.values-mean(data$wage))^2) #2194.11159614297
SSR<-sum((model$residuals)^2) #4966.30269483891
SST = SSE + SSR # 7160.414
#결정계수
SSE/SST #[1] 0.3064224
1-SSR/SST #[1] 0.3064224개인적인 질문) 잘못된 독립변수로 인해 바뀌 종속변수를 집어 넣었을 때 어떠한가?
실제로 이러한 경우로 인해서 회귀 모델의 유용성을 판단한다면 문제가 생깁니다. 그러한 이유로 조정된 결정계수(Adjusted R-Squared)를 계산하면 됩니다.
방식: 독립변수의 개수가 증가하면 일방적으로 증가하는 결정계수와 다르게 증가 시 분자를 감소시키는 연산을 통해서 일방적인 증가 방지합니다.
*공식
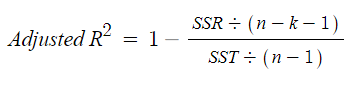
R로 보는 예시
#위의 데이터를 기반으로 하겠습니다.
lm(formula = wage - educ + exper + tenure, data = data)
1-(SSR/(526-3-1))/ SST(526-1)) #[1] 0.3024364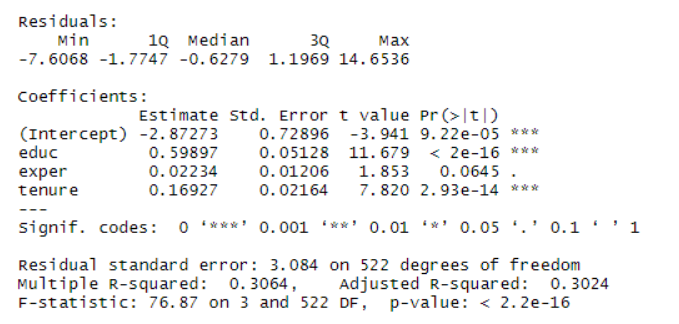
Q10. 평균(mean)과 중앙값(median)중에 어떤 케이스에서 뭐를 써야할까요?
사실 이 내용은 데이터의 describe를 본 이후에 EDA를 하거나 데이터의 분포도 및 경향성을 판단할 때 필요한 개념입니다.
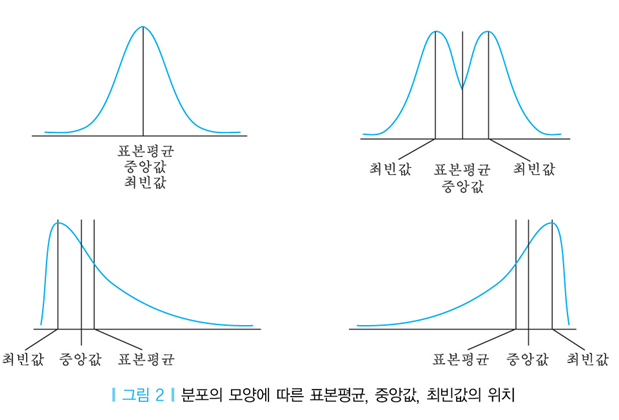
평균(mean) : 모든 관측값의 합을 자료의 개수로 나눈 것입니다. 그렇기에 전체 관측값이 골고루 반영이 되기에 데이터의 대표적인 가치를 갖습니다. 그러므로, 평균 근처에 표본이 있다면 정말 경향성을 파악하기 좋습니다.
허나 한 가지 큰 단점이 있는데 그것은 바로 극단적인 값에 영향을 많이 받기에 아주 작은 값이나 큰 값(outlier,이상치)에 큰 영향을 받습니다. 그래서, 이 개념없이 데이터를 EDA하고 분석할 때 잘못된 결과를 부럴 일으킬 수 있습니다.
그렇다면, 그것에 대한 대응은 바로 중앙값입니다.
중앙값(median): 전체 관측값을 크기 순서로 배열했을 때 중앙에 위치한 값으로 가운데 위치하는 값 이외에 다른 값들의 영향을 받지 않기에 이상치에 민감하지 않습니다. 그래서, 왜곡이 심한 데이터의 경우 일 때 유용합니다.
*자료의 개수(N)이 홀수 일 때: (N+1)/2 번째 관측값
*자료의 개수(N)이 짝수 일 때: (N)/2번째 관측값과 (N+1)/2번째 관측값의 평균
*그림으로 보는 평균과 중앙값
R로보는 평균과 중앙값
mean(c(89,74,91,88,72,84)) #83
median(c(89,74,91,88,72,84)) #86
median(c(90,213,43,5,56,6,76,123)) #5