Pathlib
-
파일 위치 찾기
-
파일 입출력
-
사용법
*파일 열기
import pathlib
path = pathlib.Path('test.txt')
file = path.open('r')
*파일 읽고 쓰기
import pathlib
# 읽기
path = pathlib.Path(' test.txt')
file = path.read_text()
# 쓰기
path = pathlib.Path('test1.txt')
path.write_text('파일쓰기')*경로 분석
import pathlib
path = pathlib.Path('/user/path/to/file')
print(path)
print(path.parent)
print(list(path.parents))
print(path.parts)
*실행한 스크립트 폴더 경로 얻기
import pathlib
path = pathlib.Path.cwd()
*현재 위치한 파일/폴더 얻기
import pathlib
path = pathlib.Path('.')
files = path.glob('*')
print(list(files))
*현재 위치에서 존재하는 모든 파일/폴더 얻기
import pathlib
path = pathlib.Path('.')
files = path.glob('**/*')
print(list(files))
GRU4REC
Preview
-
RNN 계열 모델 적용
-
GRU 성능 > LSTM

-
Embedding Layer 사용 X > Embedding Layer 사용 O
-
One-hot Encoding
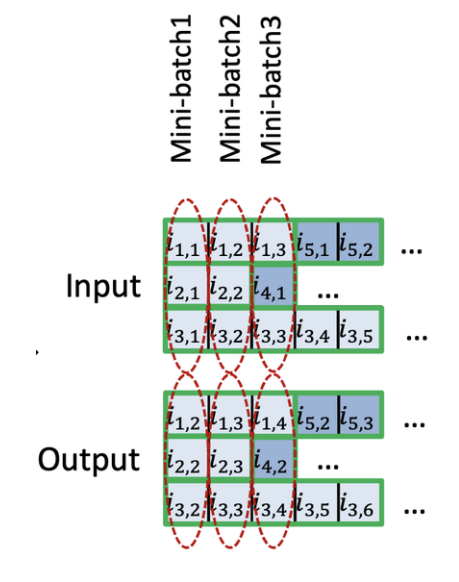
Session-Parallel Mini-Batches
-
Session의 길이는 매우 짧음
-
Session의 길이가 긴 경우, 세션들의 데이터 샘플 -> mini-batch -> input
--> 단점: 길이가 제일 긴 세션의 연산이 끝날 때까지 짧은 세션들이 기다림.

*기존 문제의 단점!!
- Session 1,2,3,을 하나의 mini-batch로 만들 시, Session 3의 연산이 끝나야 끝나는 식.
*문제 해결
-
Session-Parallel Mini-Batches제안
-
Session이 끝날 때까지 기다리지 않고 병렬적 계산
-
Session2 -> Session4로 시작
-> Mini-Batch의 shape (3,1,1) & RNN cell state가 1개.
-
stateful = True -> RNN 만들다 (by Tensorflow)
링크텍스트--> state = 0
-
code적 설명
Sampling on the output
-
Negative Sampling 개념
-
Item의 수 많아 loss계산 시 인기도 고려하여 Sampling.
Ranking Loss
- Session-Based Recommendation Task:
- 다음 아이템이 무엇인지 Classification Task
- 관련도 순으로 랭킹을 매겨서 높은 랭킹의 아이템 추천
- Ranking을 맞추는 objective function연구 있다.
- Classificationn Task ~ Cross-Entropy Loss 사용

성장을 도울 아카이빙 블로그