Prologue
제가 컴퓨터를 통해서 저의 얼굴과 유사한 이미지를 찾으려면 컴퓨터에게 어떤 벡터공간에서 표현하고자 싶은 정보를 사용할 수 밖에 없습니다.
그 정보는 연예인의 얼굴과 제 얼굴이 닮은지 파악하는 방법은 두 얼굴 벡터 사이의 거리가 얼마나 되나로 귀결됩니다.
그리고 사진은 고차원 정보이기에 컴퓨터가 인식하고 알아듣기에 힘들 수도 있습니다. 그래서 중요한 것이 컴퓨터가
알 수 있게 고차원 정보를 저차원으로 변환하고 변환했음에도 불구하고 필수 정보들은 보존하는 임베딩기술이 중요합니다.
필수정보들은 상대적입니다.
임베딩
-정의: 고차원에서 저차원으로 공간변환 통해서 컴퓨터가 제대로 수행할 수 있게 도와줌.
-종류
+)텍스트 임베딩 :각 셀이 별 개의 단어를 나타내는 고차원적이고 희박한 벡터 방법 사용
-작지만 밀도가 높은 벡터 방식을 통해서 각 요소는 단어의 특성을 0~1사이의 값으로 판단하여 의미적으로 인코딩을 합니다.
+)이미지 임베딩: 개별적인 원시 픽셀 강도를 지닌
이미지를 나타내는 고차원적인 데이터셋 작동
대규모 이미지 데이터 셋은 Image Net이나 NASNet를
통해서 이미지 분류 모델을 학습시킨 후 softmax를 가지고 분류기준이 없는 모델을 사용하여 추출
얼굴임베딩 - 얼굴인식
0)Face Recognition라이브러리 사용하기!
:Face Detection~ Recognition그리고 비교까지 쉽게 사용.
1)얼굴인식
: 얼굴 영역만 정확히 인식하는 것을
i)Input image(이미지 넣기)
ii)Detection(얼굴 위치 찾기)
iii)Transform(변형)
iv)Crop(이미지 영역 자르기)
v)Clustering(군집화))
vi)Similarity(유사도)
vii)Classification(분류)
얼굴임베딩 - FaceNet

특징: 얼굴 특징을 추출해서 저차원 벡터로 만든 후 얼굴의 특징을 잘 비교하는 모델이 되도록 학습시켜줌.
- FaceNet 속 특징 -L2 Normalization
:L2 distance구한 후 결과를 Normalization.
:임베딩 벡터는 벡터의 크기가 1
:이런 제약조건으로 인해 두 점 사이의 거리 계산 시
벡터의 절대적 크기에 무관하고 사이 각도에만 영향. -Triplet Loss
:세 개의 데이터 쌍을 이용하여 계산함.(손실함수)
-> 네트워크 학습 가능
:같은 사람은 임베딩벡터 A-C거리 가깝게
:다른 사람은 임베딩벡터 B-C거리 멀게
얼굴임베딩 - 얼굴 사이의 거리 측정하기
:Triplet Loss를 통해서 학습된 모델이 측정을 해줄 수 있습니다. 두 사진 사이의 임베딩 거리가 멀면 다른 사람이고 거리가 가까우면 같은 사람입니다.
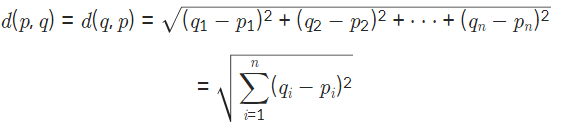
:numpy.linalg.norm을 통해서 L2 Norm Distance를 계산
얼굴임베딩 - 공간의 시각화
-PCA: 주성분 분석으로 축에 따른 값의 변화도인 분산 확인 후 가장 큰 것만 남긴다
-T-SNE: 고차원 상에서 먼 거리를 저차원 상에서도 멀리 배치디도록 자원 축소
먼저 random하게 데이터 배치 후 위치 변경을 통해서 변경
가장 닮은꼴 얼굴 찾아보기
- def get_cropped_face(image_file) : 이미지 파일에서 얼굴 영역을 가져오는 함수
- def get_face_embedding(face) : 얼굴영역으로부터 얼굴 임베딩 벡터를 구하는 함수
- def get_face_embedding_dict(dir_path) : 디렉토리 안에 있는 모든 이미지의 임베딩 딕셔너리를 구하는 함수
- def get_distance(name1, name2) : 두 이미지(사람 이름) 사이의 임베딩 벡터 거리를 구하는 함수
