이번 프로젝트는 NLP기반인 인공지능을 만드는 것으로
인간이 갖고 있던 고유한 언어적 특성을 인공지능이 얼마나 구현하고 수행하고 있는지에 대해서 알 수 있었다.
프로젝트 속 CS
1.시퀀스
-정의 : 순서가 있는 데이터 구조 입니다.
-종류 : 리스트, 튜플,기타 등등
i)리스트
:다양한 데이터를 담을 수 있고 데이터 변경도 가능
:대괄호([,])로 표현
:값을 변경할 수 있는 가변 데이터
ii)튜플
:다양한 데이터를 담을 순 있으나 데이터는 변경안됨.
:소괄호()로 표현
:불변 데이터
2.순환신경망(RNN)
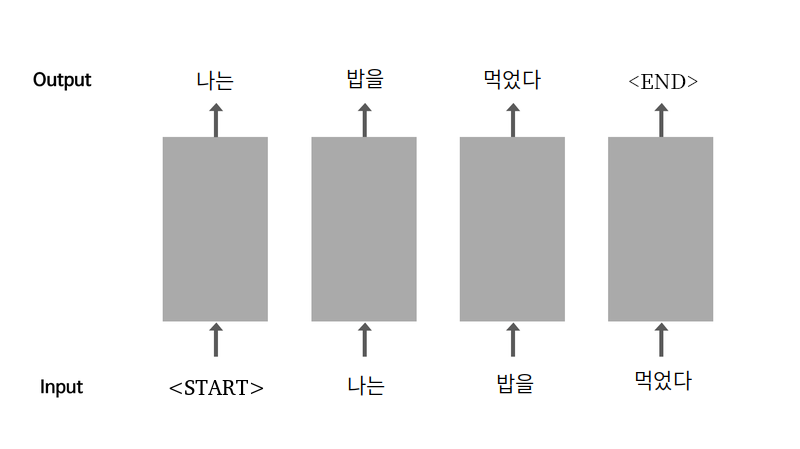
:특수 토큰(START)를 통해서 많은 데이터를 처리하고 생성한 단어를 다시 입력으로 사용한다.
3.언어 모델(Language Model)
: n-1개의 단어가 있을 때, 그 다음 순서인 n번째에 어떤 단어가 올지 예측을 하는 확률 모델입니다.
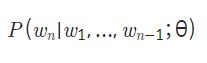
모델 학습
-n-1 번째까지의 단어 시퀀스 : x_train
-n번째 단어: y_train
데이터 전처리 과정
1.소스 문장(Source Sentence)
:모델의 입력이 되는 문장
2.타겟 문장(Target Sentence)
:모델의 출력 문장
3.벡터화(vectorize)
tf.keras.preprocessing.text.Tokenizer패키지 이용
-> 정제된 데이터 토큰화를 통해서 단어 사전을 만들어 주고 이로 인해 데이터를 숫자로 변환 시킴.
4.텐서(tensor)
:숫자로 변환된 데이터
5.정규표현식을 통해 corpus생성
6.tf.keras.preprocessing.text.Tokenizer
:corpus를 텐서로 변환
7.tf.data.Dataset.from_tensor_slices
:corpus텐서-> tf.data.Dataset객체로 변화
인공지능 모델

1.모델 만든 방식
:tf.keras.Model을 Subclassing하는 방식.
2.모델 구성 방식
Embedding -1개
:인덱스 값을 해당 인덱스 번째의 워드 벡터(추상적 표현으로 사용이 됨)
embedding_size: 워드 벡터의 차원 수
ex)
차갑다: [0.0, 1.0]
뜨겁다: [1.0, 0.0]
미지근하다: [0.5, 0.5]
LSTM - 2개
:모델에 얼마나 많은 일꾼을 넣을까에 대한 물음이다.
hidden_size.
Dense - 1개
