숫자로 된 측도
중심측도
- 중심이 어디있는지 나타냄
*표본평균(sample mean)

가장 많이 사용되는 것으로, n개의 자료가 있을 때 x1, x2, xn을 전부 합쳐서 자료의 개수만큼 나누어 준 값을 xbar라는 기호를 써서 표현하고 읽기를 x-bar라고 읽습니다
즉, n개 자료의 값들을 전부 합쳐서 자료의 개수만큼 나누어 준 값을 표본평균이라고 하고 기하학적으로 보면 n개 값의 무게중심입니다.
자료의 점도표를 통해 좀 더 구체적으로 보겠습니다.
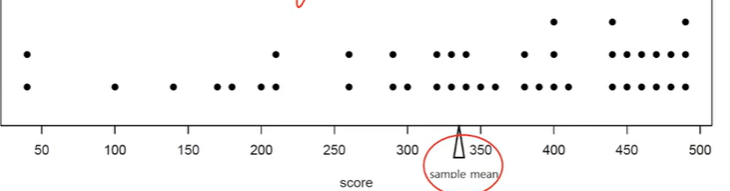
이 자료들의 평균이 330정도 되는데 이것이 xbar가 되고 이 값은 주어진 자료들의 무게중심이 됩니다.
마치 저희들이 시소에서 양쪽의 사람들이 앉을 때 무게 중심을 잘 맞추면 평형을 이루는 원리와 같습니다.
*표본 중간값(sample median)
n개의 자료를 작은 것부터 크기 순으로 나열하여 가운데에 있는 값으로 표본의 크기(자료의 개수)에 따라서 달라질 수 있습니다.
왜냐하면 자료의 개수가 홀수인 경우에는 가운데 있는 값이 유일하게 존재를 하지만 짝수인 경우에는 두개가 존재 할 수 있습니다.

이상치에 영향의 거의 받지 않기에 자료의 이상치가 있을 경우 표본 중간값이 더 좋을 수도 있습니다.
*표본 분위수(sample quantile)
수학적 정의로 표본100p% 백분율 이것은 sample 100 percentile을 번역한 것인데 여기서 p는 0과 1사이로 100p% 개의 자료는 그 값보다 작거나 같고 100*(1-p)%의 자료는 그 값보다 크거나 같은 것을 의미합니다.

*분포의 형태(줄기-잎 그림)
- 90도 돌리면 히스토그램이 됩니다.
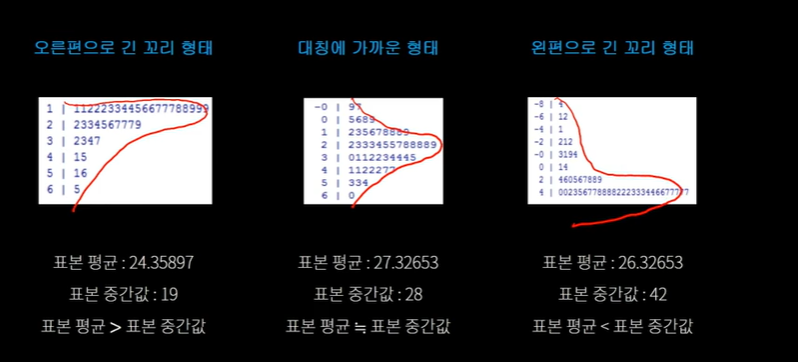
그래서 흔히 이 세 가지 형태 오른쪽으로 치우쳐져 있느냐, 왼쪽으로 치우쳐져 있느냐, 아니면 대칭이냐에 따라서 표본평균과 표본 중간값의 대소 관계가 세 가지 형태로 나온다는 것을 말씀 드리겠습니다.
퍼짐측도
- 자료들이 중심으로부터 얼마나 많이 퍼져있느냐를 나타냄
*표본 분산(sample variance)

주어진 자료 x에서 평균값을 빼고 제곱을 한 다음에 전부 합합니다.
그리고 이를 나누어 주는 것을 표본의 개수에서 1을 뺀 것 을 나누어 줍니다.
*표본 범위(sample range)

이것은 자료의 최대값에서 최소값을 뺀 값이고 흔히 range의 첫글자를 따서 R이라고 표현합니다.
또 다른 퍼짐의 측도로 제 3사분위수에서 제1 사분위수를 뺀 값, 즉 Q3-Q1을 표본 사분위수 범위 sample interquartile range라고 합니다. 그래서 이것을 IQR이라는 말로 흔히 줄여서 사용하고 있습니다.
*상자 그림(box plot)
먼저 상자 그림에는 두 가지 형태가 있는데
흔히 말하는 box plot이 있고 또 다른 하나는 box-whisker plot이란 것이 있습니다.
상자그림에서 각각의 line이나 점들이 무엇을 의미하는지를 설명을 드리겠습니다.
box plot
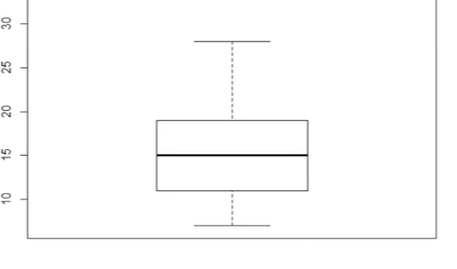
위의 점들이 없이 주어집니다.
전부 최대값과 최소값 만을 이용해서 표현 한 것을 우리가 흔히 box plot
box-whisker plot
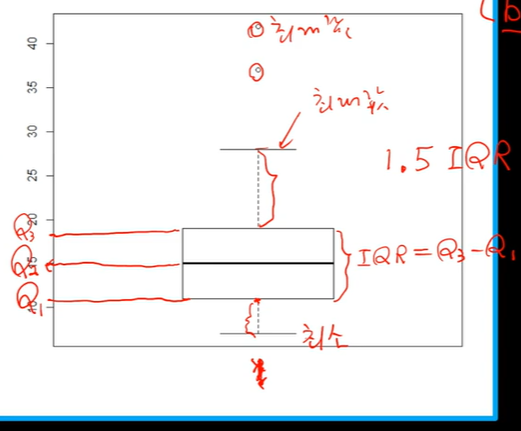
때로는 위의 점들이 나타날 수 있습니다.
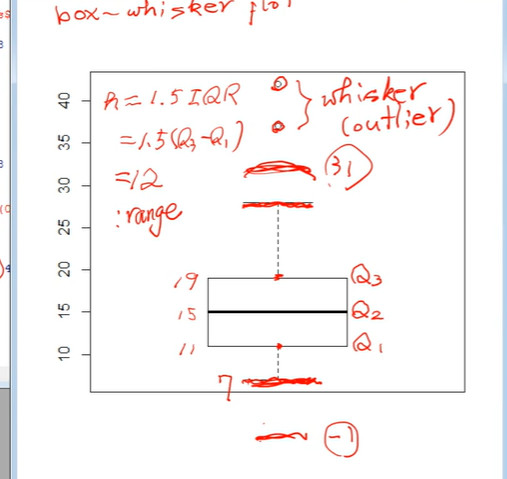
이렇게 이상치가 있으면 즉 1.5IQR을 Q1또는 Q3에서 벗어나는 작은 값이나 큰 값이 있을 경우에
이런 식으로 표현해 주는 것을 box-whisker plot이라고 합니다.
공통점
box의 아랫 부분에 해당되는 값 Q1, 가운데 선이 Q2, 윗 부분이 Q3입니다.
따라서, IQR이 바로 이것입니다.
그 다음에 최대값이나 최소값이 1.5*IQR의 range에 들어오는지 여부를 확인합니다.
예를 들어서 Q3에서 1.5IQR만큼 올라간 이 값을 벗어나는 값이 있으면 이렇게 점을 찍습니다.
하지만 벗어나는 값이 없으면 이 값은 최대값이 됩니다.
반면에 이것은 최소값인데 이 경우는 밑에 점이 없습니다.
왜냐하면 최소값이 Q1-1.5IQR 범위 안에 있기 때문에 밑에 다른 점들이 나타나지 않습니다.
여기에 나타나는 경우는 이 값이 최대값이고 이 값이 최대값 직전의 값인데 이 값이 Q3보다1.5IQR 의 범위 안에 있으면 이런 값들이 나타나지 않습니다.
R Code
> data()
> x <- stackloss$stack.loss ;x
# R에 내장되어 있는 stackloss 데이터 중에서 4번째 변수인 stack.loss를 x에 저장
[1] 42 37 37 28 18 18 19 20 15 14 14 13 11 12 8 7 8 8 9 15 15
> mean(x) #평균
[1] 17.52381
> var(x) # 분산
[1] 103.4619
> sd(x) #표준편차
[1] 10.17162
> s<-sort(x);s #오름차순으로 정렬한 거 저장
[1] 7 8 8 8 9 11 12 13 14 14 15 15 15 18 18 19 20 28 37 37 42
> length(x) # 몇 개 있나
[1] 21
#quantile는 백분위 수 계산
> quantile(x, c(0.1,0.25,0.5,0.95)) #이것은 p가 0.1일 때, p가 0.25일 때 즉 Q1 제1사분위수, 그리고 0.5는 sample median에 해당되고, 마지막으로 p가 0.95일 때를 계산
10% 25% 50% 95%
8 11 15 37
>
> fivenum(x)
[1] 7 11 15 19 42 #최솟값, 제1사분위수, 제 2사붅위수, 제3사 분위수, 최댓값
> summary(x) #fivenum에다가 평균값이 하나 더 들어있는 명령어
Min. 1st Qu. Median Mean 3rd Qu. Max.
7.00 11.00 15.00 17.52 19.00 42.00
boxplot(x)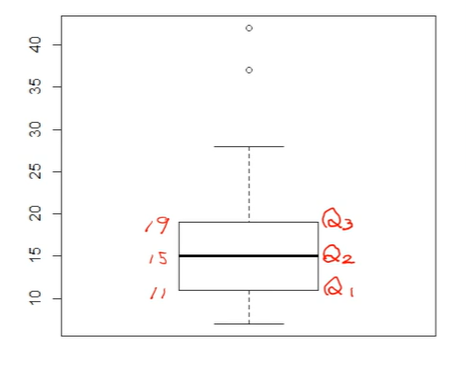
코드로 짠 그림 설명
그렇다면 자료들 중에 이 구간을 벗어나있는 값들은 이렇게 동그라미를 칩니다.
이것을 수염 whisker이라고 부릅니다. 즉 이 수염은 전체 자료중에서 이상치를 의미합니다.
이상치를 표현하기 위해서 Q3 + h보다 더 큰 값 또는 Q1 - h보다 더 작은 값이 있으면 이렇게 표현해 줍니다.
이런 이상치가 없으면 이 구간 안에서 제일 큰 값과 제일 작은 값을 그려 준 것이 box-whisker plot 입니다.
참고로 R 명령어에서 이 h값을 조절할 수 있기에 h값을 range라고 합니다.
그러므로 range를 조절함으로 써 boxplot이 다르게 그려질 수 있습니다.
range로 boxplot 조정
boxplot(x, range=0)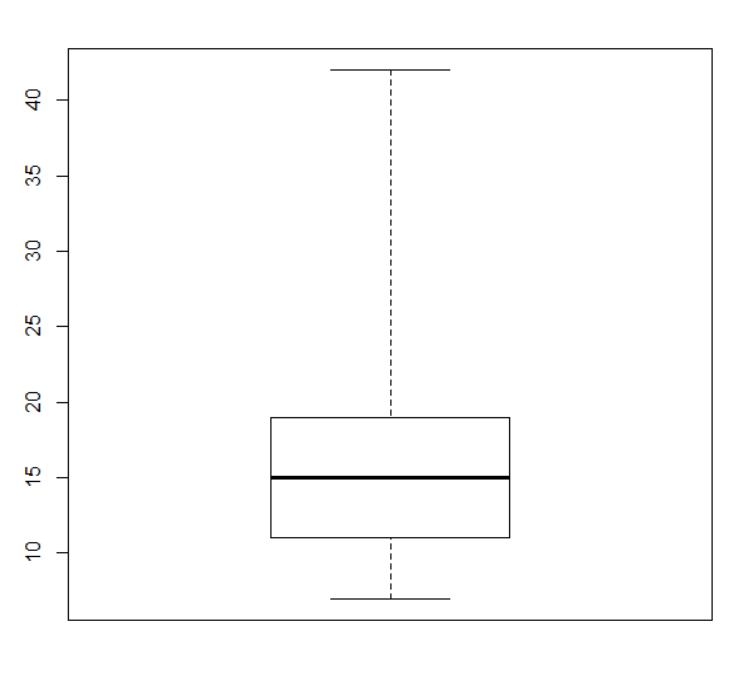
자 그렇다면 지금 이 그림을 닫고 다시 boxplot을 그리는데 range를 조절해 보겠습니다.
x에 대해서 boxplot을 그리는데 방금했던 range를 고려하지 않고 그림을 그려보면 이 그림은 whisker을 다 없앤 boxplot이 됩니다.
이것은 원래의 그냥 boxplot이 됩니다.
Q1 Q2 Q3 min max 이것은 좀 전에 h값을 전혀 고려하지 않고 five number만을 근거해 그려진 그림입니다.
그런데 이제 box-whisker plot에 비해서 box plot은 이상치를 나타내는 측면에서 부족하기 때문에
이상치를 나타내기 위해 range 바꾸기
boxplot(x, range=1.5)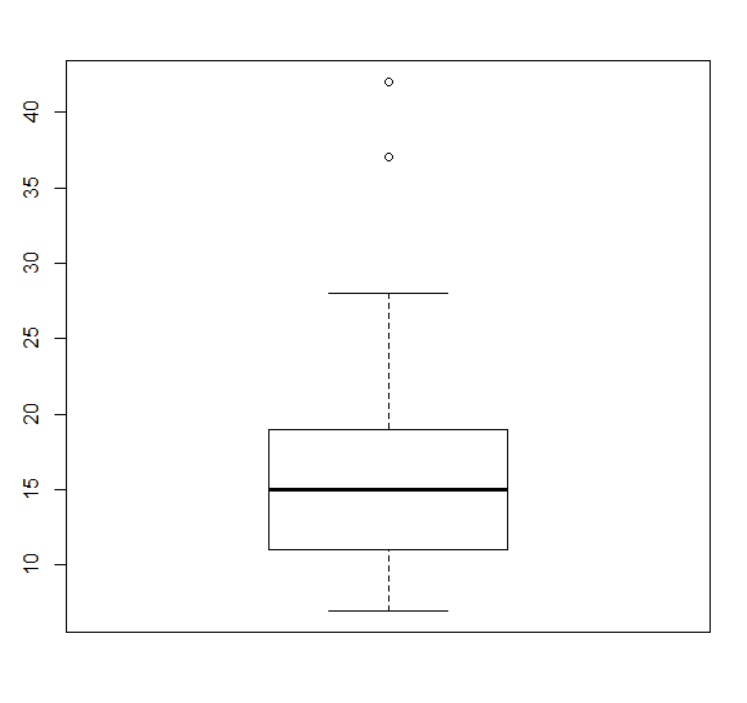
그래서 boxplot을 이용할 때는 어떤 목적이고 어떤 표현이고 또 만들어진 boxplot을 어떻게 해석할지에 유의하셔야 합니다.
자료를 정리하는 여러 가지 방법중에 표와 그래프가 굉장히 유용하게 사용
