표와 그래프
질적 자료
도수분포표
먼저 질적 자료의 경우에 가장 많이 사용하는 것이 도수분포표 입니다.
예를 들어서 A, B, C 세 사람에 대해서 2800명이 투표를 한 결과 A가 1520표 B가 770표 C가 510표다.
이때 후보자 A, B, C를 이렇게 한쪽 column에 쓰고 이에 대한 도수를 옆에 쓴 다음 총합을 맨 밑에 쓰는 것을 도수분포표라고 부릅니다.
도수라는 것 frequency라고 하기에 이 frequency table을 질적인 자료인 경우에 도수분포표로 사용하고 있습니다.
a <- rep("A", 1520) ; a #A를 1520개 만들어서 a에 저장한다
b <- rep(“B”,770) ; b #B를 770개를 만들어서 b에 저장하라.
c <- rep(“C”,510) ; c # C를 510개 만들고 c를 한번 보겠습니다.
x <- c(a,b,c) ;x #a, b, c를 묶어서 하나의 벡터로 x에 저장하라
table(x) #A, B, C로 구성되어 있는 x라는 벡터를 도수분포표를 table(x)를 실행 하면 A가 1520개 B가 770개 C가 510개
y <- as.matrix(table(x)) ;y # row형태로 즉 행 형태로 주어져 있는데 이것을 column 벡터형식으로 table(x)를 as.matrix()를 이용해서 행렬로 바꾸어줍니다.
as.matrix() 에서 as. 이라는 것은 ‘어떠한 형태로 바꾸어라’
freq <- y[,1] ; freq #y의 첫 번째 column에 있는 1520, 770, 510이라는 숫자를 freq에 저장
relative_freq <- freq/sum(y) #상대 도수
z <- cbind(freq, relative_freq) ;z #상대 도수를 column끼리 묶기
#z에 두개의 column벡터를 묶어서 저장하게 되면 z의 첫 번째 column은 freq, 두 번째 column은 relative_freq로 저장파이 차트
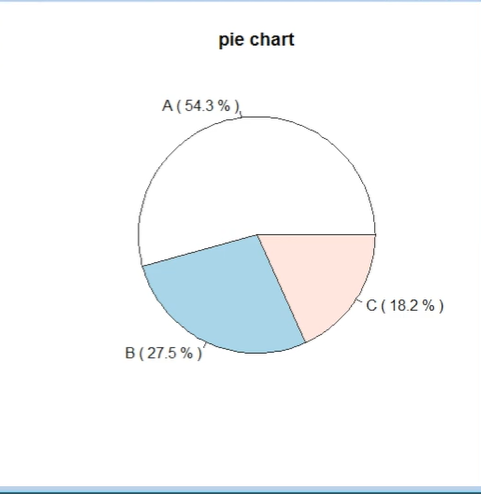
x <- c(1520, 770, 510) ;x #x는 1520라는 숫자와 770이라는 숫자, 510이라는 숫자가 A, B, C 각각의 도수로 구성
lab <- c(“A”, “B”, “C”) ; lab
y <- round(x/sum(x)*100, digits=1) ; y #상대도수에 100을 곱해서 소수점 한자리가 되게 반올림해서 y에 저장
w <- paste(lab, “(”, y, “%”, “)”) ;w #lab(y%) 와 같은 식으로 먼저 괄호를 열고 y값 비율과 %기호를 붙이고 괄호를 닫은 것을 w에 저장
pie(x, labels=w, main=“pie chart”) #파이 차트 그리기, 입력값, 라벨, 제목
*예제 : 30페이지로 이루어진 보고서에서 각 페이지당 오자의 개수
A, B, C (누적도수%) 이것이 조금 전 우리가 했던 w에 저장
x <- c(1,1,1,3,0,0,1,1,1,0,2,2,0,0,0,1,2,1,2,0,0,1,6,4,3,3,1,2,4,0) ;x
y <- as.matrix(table(x)) ;y #30개의 숫자를 table로 만들어서 이를 행렬 형태로 바꾼 것을 y에 저장
freq <- y[,1]; freq # 첫 번째 값을 freq에 저장
rel_freq <- freq/sum(freq); rel_freq #상대도수를 구하기 위해서 freq에 sum(freq)를 나누어준 것을 rel_freq에 저장
csum <- cumsum(freq); csum #cumsum은 cumulative sum 즉 누적 합으로 freq 도수를 누적을 시켜서 csum에 입력하라는 의미
c_rel_freq <- csum/sum(freq) # csum을 전체 합으로 나누면 누적 상대도수
z <- cbind(freq, rel_freq, csum, c_rel_freq) ;z #도수, 상대도수, 누적 도수, 누적 상대도수를 열 벡터로 묶어서 z에 저장
양적 자료
data() 명령어를 입력하여 내장되어 있는 자료를 불러올 것이고 이번에는 faithful geyser데이터를 이용할 것입니다.
히스토그램
faithful 데이터 중에서 waiting 두 번째 변수에 대해서 히스토그램
faithful은 자료명
waiting는 변수명
hist는 히스토그램을 그려라
data()
hist(faithful$waiting)
크기를 계급구간 interval이라고 합니다.
이 계급의 개수는 통상 정해져 있는 것은 없지만 10개에서 20개 정도를 사용하는 것이 적절한 것으로 알려져 있습니다. 왜냐하면, 계급의 수가 너무 많거나 작으면 자료를 제대로 설명 할 수 없습니다.
지금 이것은 40부터 100까지 5씩 즉 계급구간의 크기가 5로 돼있습니다.
총 12개의 구간으로 구성이 되어있습니다.
이 히스토그램으로부터 알 수 있는 것이 이런 형태의 그래프에 가까운 모양
을 띄고 있다. 저희들은 이를 통해 전체 자료의 분포에 관한 정보를 얻을 수가 있습니다.
줄기- 잎 그림(stem and leaf plot)
줄기-잎 그림도 조금 전 faithful 데이터의 waiting이라는 변수를 이용
줄기-잎그림 을 그리기 위해서는 stem이라는 명령어
stem(faithful$waiting)
그러면 이렇게 나타나는데 왼쪽을 보시면 4가 두개가 있고 5가 두개 이 부분은 10단위라고 생각 하시면 됩니다.
그리고 오른쪽에 있는 숫자는 1단위 숫자입니다.
그러면 여기 있는 4 3 이라는 것은 43을 의미합니다.
다음으로 45가 3개가 있고 46이 5개가 있고 또 47이 4개가 있고 이런 식으로 그려져 있습니다.
원래 이렇게 10단위 수가 두개 나타날 필요가 없고 하나만 이용해서 뒤로 쭉 3 5 6 7 8 9 이런 식으로 쓰는데 히스토그램이나 상대도수는 자료 각각의 값을 알 수가 없고 그 구간 안에 몇 개의 값이 있는지만 알 수 있습니다.
반면에 줄기-잎 그림은 모든 값을 다 알 수 있습니다.
또한 최소값, 최대값 전부 알 수 있습니다.
또 다른 특징은 히스토그램의 역할도 합니다.
즉 분포의 형태를 짐작할 수 있습니다.
예를 들면 여기서 이런 형태의 모양을 알 수 있습니다.
그러면 이것을 90도로 회전을 시키면 이것이 분포의 형태가 됩니다.
그 다음 이름이 왜 줄기-잎 그림이냐 하면 왼쪽에 있는 값들이 때로는 10단위의 숫자 때로는 100단위의 숫자가 변할 수 있지만 이 왼쪽을 줄기라고 합니다.
그리고 여기 붙어있는 1단위 숫자를 잎이라고 합니다.
그래서 마치 나무의 줄기에 잎이 달려 있는데 달린 모양이 전체적으로 분포의 형태를 짐작하게끔 하고 자료의 모든 값을 나타내기 때문에 줄기-잎 그림은 굉장히 유용한 그래프입니다.
