transformer 기반의 모델을 이용하려고 할 때 downstream task를 적용하기 위한 작은 데이터를 위해 full fine tuning 하는 것이 비효율적이다.
따라서 transformer의 좋은 generalization 성능을 유지하면서 기존의 pretrained w를 이용하고 다른 태스크의 학습 및 추론 효율을 높이기 위한 목적으로 위 연구가 이루어졌다고 생각한다. (그러나 transformer 기반 모델에서만 특정짓지 않고 모든 모델의 레이어에 적용가능하다.)
아래 내용은 해당 논문과 AI Factory의 유튜브 세미나를 참고하여 작성하였다.
Background
Large-scale pretrained Model의 한계
- over-parametrized model
- 보통 pre-trained model을 fine-tuning해서 downstream task를 푸는데, 필요한 정보는 일부이다.
→ 즉 필요한 정보는 intrinsic dimension에 있을 것이다. - 이러한 intrinsic dimension을 찾기 위해 Low-Rank space로 변환하는 방식을 사용하면 더 적은 파라미터로도 같은 성능을 낼 수 있을 것이다.
- 보통 pre-trained model을 fine-tuning해서 downstream task를 푸는데, 필요한 정보는 일부이다.
Propose
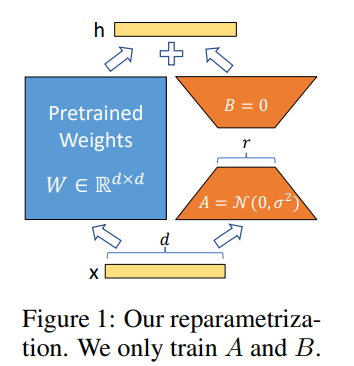
- a, b : dense layer
- r : low rank 핵심정보에 해당하는 개수 (오토인코더로 치면 latent variable z랑 똑같은 컨셉)
low rank를 찾아서 중요한 정보만 뽑아서 뭔가를 하고싶다는 컨셉(PCA랑 비슷)
a, b라는 두 매트릭스로 원본데이터를 충분히 옵티마이저할 수 있다.
GPT-3의 경우에는 12,888에 해당하는 원본(full-rank)정보를 r=1,2 정도의 low rank에서도 표현이 가능하더라
→ 즉 LoRA approach는 time & space complexity를 획기적으로 줄일 수 있다.
기존의 dxd matrix를 dxr (A), rxd (B)로 나누어 학습하기 때문에 파라미터가 굉장히 줄어든다.
method
W는 freeze
A, B가 W0를 가지고 weight update (마치 W 옆에 붙어가지고 옆에다가 정보를 간접적으로 제공해주게 된다. )
W= W0 + BA
- BA는 특정 downstream task를 위해 학습된 weight matrixs이다.
- 새로운 downstream task에 대해서 tuning을 한다면 B’A’만 새로 학습하면 된다.
- fine-tuning을 모두 다시해야 하는 다른 모델들 대비 훨씬 더 효율적인 학습이 가능하다.
Applying LoRA to Transformer
- 논문에서는 LoRA를 Transformer기반 LLM들에 적용시켰을 때, 아래와 같은 결과를 얻었다고 한다.
- Transformer Large의 경우 2/3 정도 VRAM 사용량을 줄였음
- GPT-3 175B의 경우, 1.2TB에서 350GB로 줄였음 (VRAM 사용량)
- r=4로 두면, 350GB를 35MB로 10,000배 정도 줄일 수 있었음
(r에 따라 성능과 파라미터 수가 달라짐 → r에 대해 hyper-param tuning 해야 함)

📩 qtly_u@naver.com