[Project] Natural Language Processing with Disaster Tweets - Kaggle
Natural Language Processing
| 머리말 |
전공과목인 데이터마이닝 수업의 2달 여정의 프로젝트로 저는 LSTM을 이용한 재난관련 트윗 분류문제를 선정했습니다. 지난 학기에는 타이타닉 분류예측 문제를 했었는데 교수님께서 이번에는 LSTM을 이용한 문제를 다뤄보라고 하셔서 캐글에서 가져온 문제입니다. 타이타닉 같은 숫자값으로 이루어진 데이터가 아닌 자연어를 처리하는 이진분류를 해보려고 합니다.
문제 정의
주어진 트윗(tweet) 데이터를 분석하여 재난(disaster)에 관련된 트윗인지 아닌지의 여부를 분석하는 문제입니다.
목표
이번 과제를 통해 자연어를 전처리하는 방법을 연습하고 keras에서 LSTM을 사용한 모델을 만들어보려고 합니다. 또 keras layer를 구축할 때 Embedding도 함께 사용해보겠습니다. LSTM을 포함한 다양한 분류기법으로 만든 모델 중 정확도가 가장 높은 모델을 선정하고 정확도와 로스값을 시각화고자 합니다.
[ 목차 ]
- 라이브러리와 데이터 로드
- EDA
- 텍스트 전처리
- Mislabeled data
- removing Functions - Import GloVe Embedding
- TRAIN MODEL
- 평가
| 데이터 살펴보기 |
Columns
-
id– a unique identifier for each tweet -
text– the text of the tweet -
location– the location the tweet was sent from (may be blank) -
keyword- a particular keyword from the tweet (may be blank) -
target– in train.csv only, this denotes whether a tweet is about a real - disaster (1) or not (0)총 5개의 칼럼으로 이루어져 있는데요, id는 각각의 트위터 레코드의 식별자이고, text는 트윗 텍스트, location은 트위터를 보낸 장소, keyword는 트윗의 특정 키워드, target은 트위터가 실제로 재난인지(1) 아닌지(0) 를 표시한 것입니다.
1. 라이브러리 & 데이터 불러오기
#numpy, pandas, seaborn import numpy as np import pandas as pd import seaborn as sns #tesorflow import tensorflow as tf from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Embedding, LSTM, Dropout from tensorflow.keras import optimizers #nltk import re from nltk.corpus import stopwords from nltk.stem import SnowballStemmer #matplot import matplotlib.pyplot as plt
pd.set_option('display.max_colwidth', -1) # 값의 길이가 길어 ...으로 나오는 점을 한 행에 출력할 수 있는 개수를 지정하여 다 나오게 함
train_data = pd.read_csv('train.csv', dtype={'text': str, 'target': np.int64} ) len(train_data) #7613개의 train data
train_data['text'].head().values #head를 이용해 확인

test_data = pd.read_csv( 'test.csv', usecols=['text', 'id'], dtype={'text': str, 'id': str} ) #test data는 사용할 열을 지정해서 불러왔음
2. EDA
#결측치 확인 sns.set(rc={'figure.figsize':(11,8)}) sns.heatmap(train_data.isnull(),yticklabels=False,cbar=False,cmap="coolwarm")
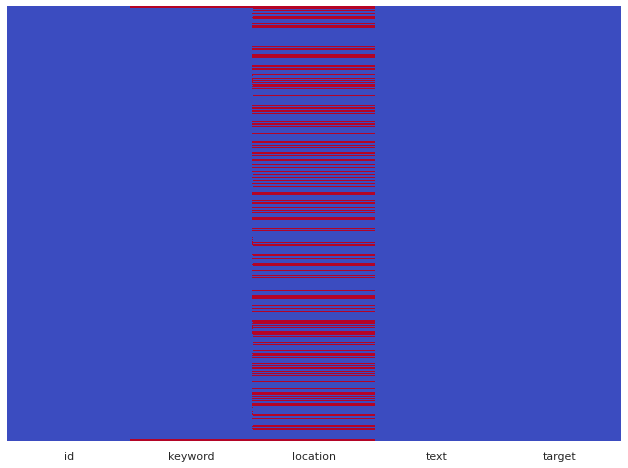
- 여기서 빨간색 선은 결측값이 있음을 나타내며 keyword와 location 열에 결측값이 있음을 나타냅니다. 모델 구축에는 텍스트와 타겟만 사용할 예정이기 때문에 location에 대한 결측값은 처리하지 않겠습니다.
#결측치 비율 missing_cols = ['keyword', 'location'] fig, axes = plt.subplots(ncols=2, figsize=(17, 4), dpi=100) sns.barplot(x=train_data[missing_cols].isnull().sum().index, y=train_data[missing_cols].isnull().sum().values, ax=axes[0]) sns.barplot(x=train_data[missing_cols].isnull().sum().index, y=train_data[missing_cols].isnull().sum().values, ax=axes[1]) axes[0].set_ylabel('Missing Value Count', size=15, labelpad=20) axes[0].tick_params(axis='x', labelsize=15) axes[0].tick_params(axis='y', labelsize=15) axes[1].tick_params(axis='x', labelsize=15) axes[1].tick_params(axis='y', labelsize=15) axes[0].set_title('Training Set', fontsize=13) axes[1].set_title('Test Set', fontsize=13) plt.show()
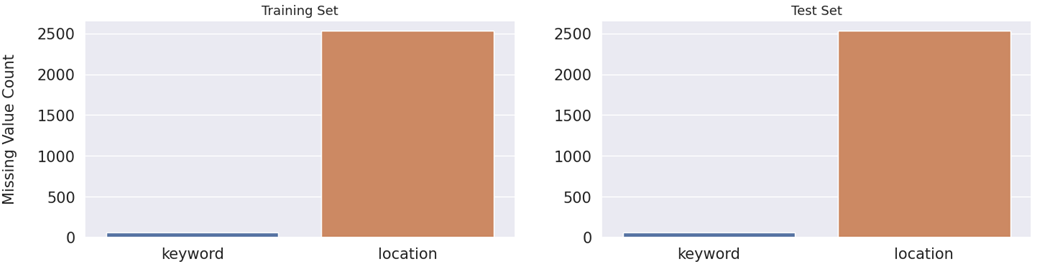
- train set과 test set 모두에서 keyword의 0.8%, location은 33%가 누락되었습니다.
훈련 세트와 테스트 세트 간의 결측값 비율이 너무 가깝기 때문에 동일한 샘플에서 가져온 것일 가능성이 큽니다.
location은 자동으로 생성되지 않고 사용자 입력이기 때문에 고유한 값이 너무 많아 feature로 사용하면 안됩니다.
다행히도 keyword는 그 자체로 feature로 사용되거나 텍스트에 추가되는 단어로 사용될 수 있습니다. 훈련 세트의 모든 단일 keyword는 테스트 셋에 존재하여 키워드에 대상 인코딩을 사용할 수도 있습니다.
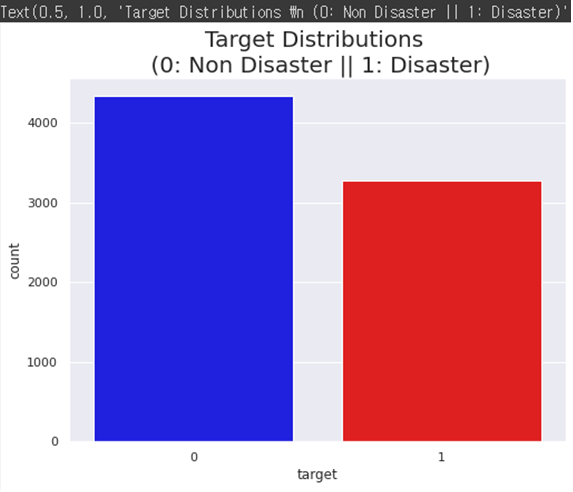
target의 비중
plt.figure(figsize=(8,6)) colors = ["blue", "red"] sns.countplot(x = 'target', data=train_data, palette=colors) plt.title('Target Distributions \n (0: Non Disaster || 1: Disaster)', fontsize=20)
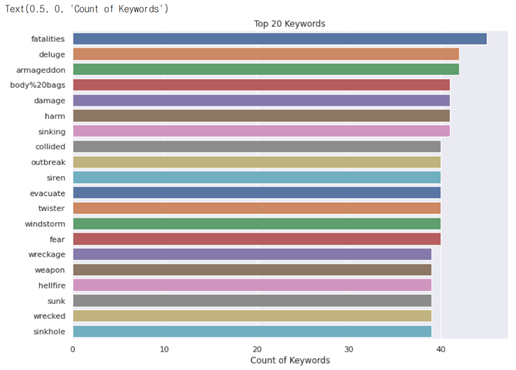
빈번하게 나온 키워드 상위 20
chains=train_data['keyword'].value_counts()[:20] sns.barplot(x=chains,y=chains.index,palette='deep') plt.title("Top 20 Keywords") plt.xlabel("Count of Keywords")
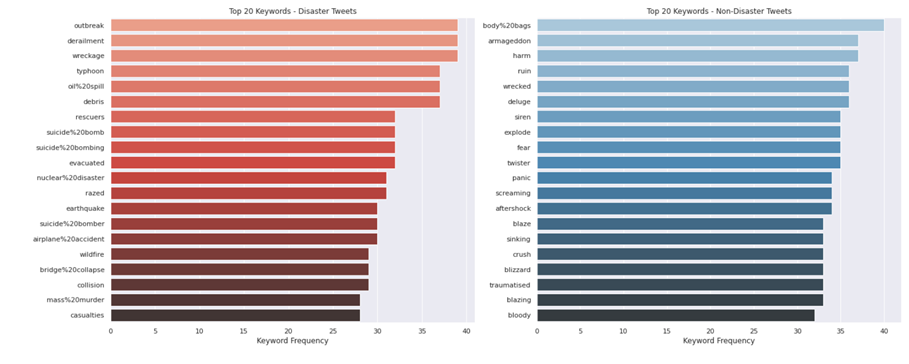
재난 트윗과 재난이 아닌 트윗에서 키워드 상위 20
disaster_keywords = train_data.loc[train_data["target"] == 1]["keyword"].value_counts() nondisaster_keywords = train_data.loc[train_data["target"] == 0]["keyword"].value_counts() fig, ax = plt.subplots(1,2, figsize=(20,8)) sns.barplot(y=disaster_keywords[0:20].index, x=disaster_keywords[0:20], orient='h', ax=ax[0], palette="Reds_d") ax[0].set_title("Top 20 Keywords - Disaster Tweets") ax[0].set_xlabel("Keyword Frequency") sns.barplot(y=nondisaster_keywords[0:20].index, x=nondisaster_keywords[0:20], orient='h', ax=ax[1], palette="Blues_d") ax[1].set_title("Top 20 Keywords - Non-Disaster Tweets") ax[1].set_xlabel("Keyword Frequency") plt.tight_layout() plt.show()
키워드에서 타겟의 분표
train_data['target_mean'] = train_data.groupby('keyword')['target'].transform('mean') fig = plt.figure(figsize=(8, 72), dpi=100) sns.countplot(y=train_data.sort_values(by='target_mean', ascending=False)['keyword'], hue=train_data.sort_values(by='target_mean', ascending=False)['target']) plt.tick_params(axis='x', labelsize=15) plt.tick_params(axis='y', labelsize=12) plt.legend(loc=1) plt.title('Target Distribution in Keywords') plt.show() train_data.drop(columns=['target_mean'], inplace=True)

- 중간에 분포한 키워드들은 재난인지 아닌지 분류하는데 영향을 거의 미치지 않을 것 같습니다.
재난 트윗에서 많이 사용한 키워드와 재난이 아닌 트윗에서 가장 적게 사용한 키워드 표시
top_disaster_keyword = train_data.groupby('keyword').mean()['target'].sort_values(ascending = False).head(20) top_nondisaster_keyword = train_data.groupby('keyword').mean()['target'].sort_values().head(20) fig, ax = plt.subplots(1,2, figsize=(20,8)) sns.barplot(y=top_disaster_keyword[0:20].index, x=disaster_keywords[0:20], orient='h', ax=ax[0], palette="Reds_d") ax[0].set_title("Top 20 Keywords - Highest used Disaster Keyword") ax[0].set_xlabel("Keyword Frequency") sns.barplot(y=top_nondisaster_keyword[0:20].index, x=top_nondisaster_keyword[0:20], orient='h', ax=ax[1], palette="Blues_d") ax[1].set_title("Top 20 Keywords - Least used Non-Disaster Tweets") ax[1].set_xlabel("Keyword Frequency") plt.tight_layout() plt.show()
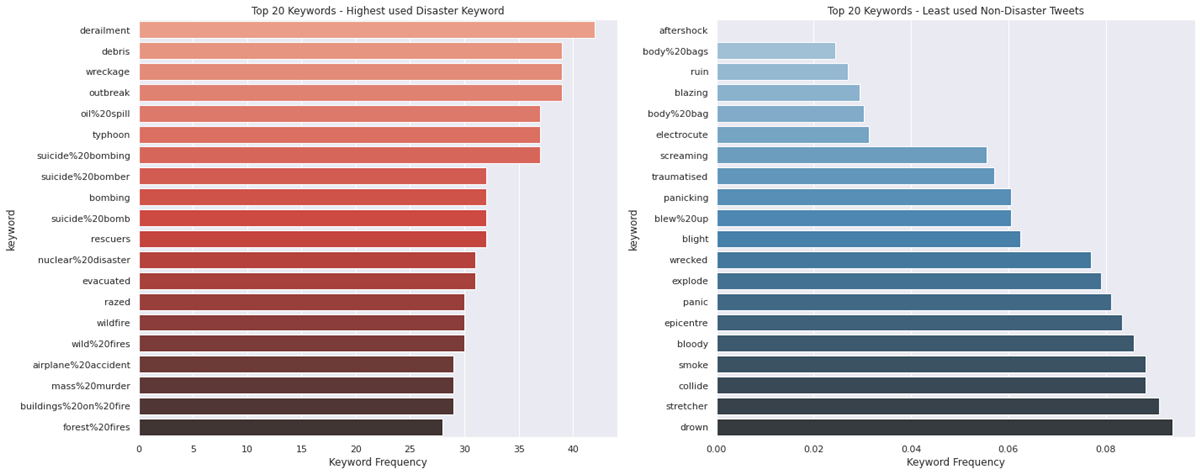
- 비슷한 키워드가 있을지 비교해볼 수 있습니다.
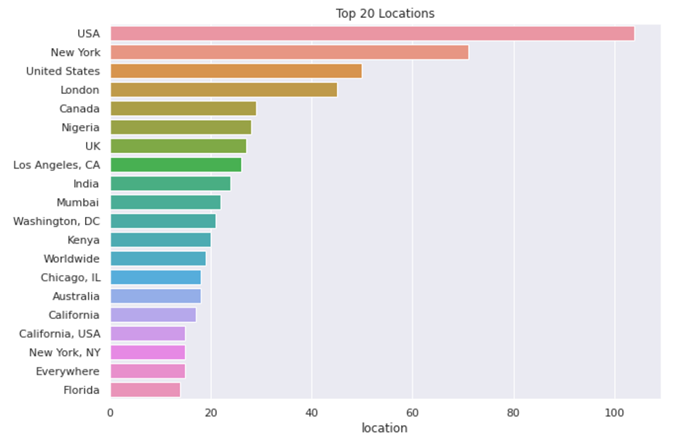
가장 많이 나타난 장소 상위 20
locations = train_data["location"].value_counts() plt.figure(figsize=(10,7)) sns.barplot(y=locations[0:20].index, x=locations[0:20], orient='h') plt.title("Top 20 Locations") plt.show()
3. 텍스트 전처리
train_data = pd.read_csv( 'train.csv', usecols=['text', 'target'], dtype={'text': str, 'target': np.int64} ) #사용할 열만 가져옴
Mislabeled data
train set에서 레이블이 잘못 지정된 행의 target 값을 전부 바꾸어 주는 과정을 거쳐주었습니다. (출력결과 생략)
indices = [4415, 4400, 4399,4403,4397,4396, 4394,4414, 4393,4392,4404,4407,4420,4412,4408,4391,4405] #행번호 배열을 만들어주고 train_data.loc[indices] #train data에서 그 행만train_data.loc[indices, 'target'] = 0 #target값을 올바른 값으로 고쳐줌indices = [6840,6834,6837,6841,6816,6828,6831] train_data.loc[indices]train_data.loc[indices, 'target'] = 0indices = [3913,3914,3936,3921,3941,3937,3938,3136,3133,3930,3933,3924,3917] train_data.loc[indices]train_data.loc[indices, 'target'] = 1indices = [246,270,266,259,253,251,250,271] train_data.loc[indices]train_data.loc[indices, 'target'] = 0indices = [6119,6122,6123,6131,6160,6166,6167,6172,6212,6221,6230,6091,6108] train_data.loc[indices]train_data.loc[indices, 'target'] = 0indices = [7435,7460,7464,7466,7469,7475,7489,7495,7500,7525,7552,7572,7591,7599] train_data.loc[indices]train_data.loc[indices, 'target'] = 0
removing Functions
텍스트를 처리하기 위해 정제함수를 사용했습니다.
def cleaned(text): text = re.sub(r"\n","",text) text = text.lower() text = re.sub(r"\d","",text) #Remove digits text = re.sub(r'[^\x00-\x7f]',r' ',text) # remove non-ascii text = re.sub(r'[^\w\s]','',text) #Remove punctuation text = re.sub(r'http\S+|www.\S+', '', text) #Remove http return texttrain_data['text'] = train_data['text'].apply(lambda x : cleaned(x))
#split train data val_data = train_data.tail(1500) train_data = train_data.head(6113)
- 훈련중에 모델이 데이터에 적합한지 확인하기 위해 훈련 데이터의 일부를 검증 data set으로 가져갑니다.
# 토큰화 def define_tokenizer(train_sentences, val_sentences, test_sentences): sentences = pd.concat([train_sentences, val_sentences, test_sentences]) # 토크나이저는 모든 고유 단어에 숫자 인덱스를 할당하여 모델이 범주 값처럼 취급할 수 있도록 합니다. tokenizer = tf.keras.preprocessing.text.Tokenizer() tokenizer.fit_on_texts(sentences)- return tokenizerdef encode(sentences, tokenizer): encoded_sentences = tokenizer.texts_to_sequences(sentences) encoded_sentences = tf.keras.preprocessing.sequence.pad_sequences(encoded_sentences, padding='post') return encoded_sentences첫 번째 함수 :
- 세 데이터 세트에서 모든 문장을 가져오고 문장에 있는 모든 단어에 색인 번호를 할당하여 토크나이저를 정의
- 세 가지 데이터 세트에 모두 토크나이저 어휘에 트윗에 있는 모든 단어가 포함되도록 함
두 번째 함수 :
- 토크나이저를 사용하여 모든 문장을 문장을 나타내는 인덱스 번호 배열로 인코딩
- 문장을 0으로 채워 훈련 데이터 세트에서 가장 긴 문장과 크기가 모두 같도록 함 (이를 위해 인덱스 0을 예약)
tokenizer = define_tokenizer(train_data['text'], val_data['text'], test_data['text']) encoded_sentences = encode(train_data['text'], tokenizer) val_encoded_sentences = encode(val_data['text'], tokenizer) encoded_test_sentences = encode(test_data['text'], tokenizer)
#토크나이저 구성을 파이썬 사전으로 반환하는지 확인 print('Lower: ', tokenizer.get_config()['lower']) print('Split: ', tokenizer.get_config()['split']) print('Filters: ', tokenizer.get_config()['filters'])
4. Import GloVe Embedding
GloVe(Global Vectors for Word Representation)은 미리 Training된 Embedding으로 수백만 개의 영어 Word에 대해서 미리 Training되어있습니다. 앞으로의 Embedding 계층은 GloVe를 통하여 구축하고 결과를 확인하도록 하겠습니다.
#다운로드한 glove 사용 위해 마운트 from google.colab import drive drive.mount('/gdrive', force_remount=True)
embedding_dict = {} with open('/gdrive/My Drive/Colab Notebooks/glove.6B.100d.txt','r') as f: for line in f: values = line.split() word = values[0] vectors = np.asarray(values[1:],'float32') embedding_dict[word] = vectors f.close()
#토큰라이저와 임베딩의 인코딩을 동기화하기 위해 임베딩의 인코딩된 단어를 토큰라이저의 인코딩으로 업데이트 num_words = len(tokenizer.word_index) + 1 embedding_matrix = np.zeros((num_words, 100)) for word, i in tokenizer.word_index.items(): if i > num_words: continue emb_vec = embedding_dict.get(word) if emb_vec is not None: embedding_matrix[i] = emb_vec
tf_data = tf.data.Dataset.from_tensor_slices((encoded_sentences, train_data['target'].values))
def pipeline(tf_data, buffer_size=100, batch_size=32): tf_data = tf_data.shuffle(buffer_size) tf_data = tf_data.prefetch(tf.data.experimental.AUTOTUNE) tf_data = tf_data.padded_batch(batch_size, padded_shapes=([None],[])) return tf_data tf_data = pipeline(tf_data, buffer_size=1000, batch_size=32) print(tf_data)
tf_val_data = tf.data.Dataset.from_tensor_slices((val_encoded_sentences, val_data['target'].values))
def val_pipeline(tf_data, batch_size=1): tf_data = tf_data.prefetch(tf.data.experimental.AUTOTUNE) tf_data = tf_data.padded_batch(batch_size, padded_shapes=([None],[])) return tf_data tf_val_data = val_pipeline(tf_val_data, batch_size=len(val_data)) print(tf_val_data)
5.TRAIN MODEL
케라스로 임베딩 설계하기
embedding = tf.keras.layers.Embedding( len(tokenizer.word_index) + 1, 100, embeddings_initializer = tf.keras.initializers.Constant(embedding_matrix), trainable = True )model = tf.keras.Sequential([ embedding, tf.keras.layers.SpatialDropout1D(0.2), tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(128, dropout=0.2, recurrent_dropout=0.2)), tf.keras.layers.Dense(1, activation='sigmoid') ])
- 그런 다음 training 함수(adam)와 손실 함수(log loss)를 정의하는 모델을 컴파일합니다. 모델 정확도가 에포크별로 출력되도록 메트릭 파라미터도 추가했습니다.
model.compile( loss=tf.keras.losses.BinaryCrossentropy(from_logits=True), optimizer=tf.keras.optimizers.Adam(0.0001), metrics=['accuracy', 'Precision', 'Recall'] )callbacks = [ tf.keras.callbacks.ReduceLROnPlateau(monitor='loss', patience=2, verbose=1), tf.keras.callbacks.EarlyStopping(monitor='loss', patience=5, verbose=1), ]
- 모델이 최적 상태를 넘어서는 것을 방지하기 위해 두 개 이상의 에포크 동안 손실 발생 시 학습 속도를 줄이도록 했습니다.
또 처리를 절약하기 위해 5번 동안 손실이 나지 않으면 정지합니다.
history = model.fit( tf_data, validation_data = tf_val_data, epochs = 30, callbacks = callbacks )

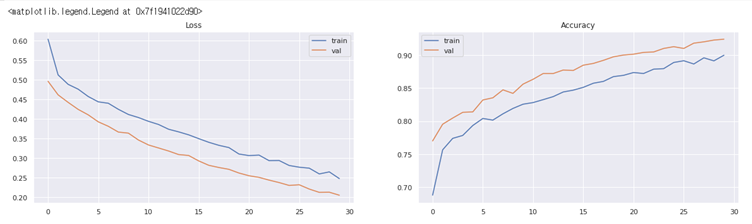
- epoch 30에 대한 결과
train set에 대한 정확도 90.94%
valid set에 대한 정확도 92.40%
6. 평가
F1 Score
metrics = model.evaluate(tf_val_data) precision = metrics[2] recall = metrics[3] f1 = 2 * (precision * recall) / (precision + recall) print('F1 score: ' + str(f1))

- f1 score 0.90
#모델이 훈련 중일 때 에포크당 생성된 로스값과 정확도 시각화 fig, axs = plt.subplots(1, 2, figsize=(20, 5)) axs[0].set_title('Loss') axs[0].plot(history.history['loss'], label='train') axs[0].plot(history.history['val_loss'], label='val') axs[0].legend() axs[1].set_title('Accuracy') axs[1].plot(history.history['accuracy'], label='train') axs[1].plot(history.history['val_accuracy'], label='val') axs[1].legend()
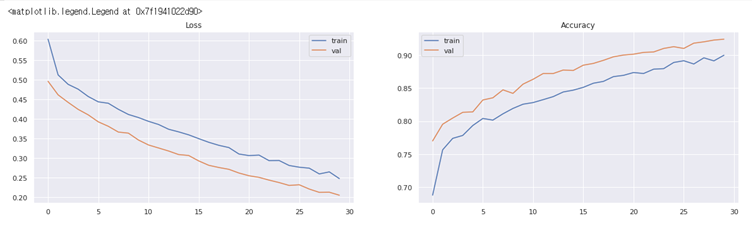
Google Colab을 사용하였는데 epoch 횟수를 50으로 설정해놓고 너무 오래걸려 코드를 한 번 수정할 때마다 keras를 다시 돌리는 점이 번거로웠다. 교수님께 돌아가는 시간이 너무 오래걸려 epoch를 줄이는 방법 밖에 없을까 했는데 교수님께서는 Google Colab은 Google Colab보다는 JupyterNotebook을 사용하거나 Colab 유료결제를 하는 것이 속도가 더 빠르다고 하셨다. 다음번 분석부터는 팀 프로젝트에서는 공유가 편리한 Colab, 개인으로 사용할 때는 Jupyter를 사용하는 것이 베스트일 것 같다.
