[Recommendation System in Practice] 콘텐츠 기반 필터링, 협업 필터링, Cold start problem
Machine Learning/Deep Learning
Recommendation System in Practice 정리
본 글은 Recommendation System in Practice 를 공부하고 정리한 글입니다.
< 세 가지의 주요 시스템과 실용적 관점(이슈)에 대해 >
[ 목차 ]
- Content-based recommendation
1.1. Content-based 추천 방법
1.2. Content-based 추천 특징- Collaborative Filtering
2.1. CF 접근 방식(1) - Nearest neighbor (최근접 이웃 기반 방법)
2.2. CF 접근 방식(2) - Latent-factor methods (잠재 요인 방법)
2.2.1. Matrix factorization (행렬 분해) - Simon Funk’s SVD
2.2.2. Deep learning embedding (Deep Learning 임베딩)
-Hybrid approaches- Cold start, Scalability, Interpretability, and Exploitation-Exploration
3.1. Cold start problem
3.2. Scalability (확장성)
3.2.1. Offline batch computing and online serving
3.2.2. Sampling (표본추출)
3.2.3. Leveraging sparsity (희소성 활용)
3.2.4. Multi-phase modeling (다단계 모델링)
3.2.5. Scale deep networks (뉴럴 네트워크 확장)
3.3. Interpretability (설명가능성)
3.4. Exploitation-Exploration (활용과 탐험) - 방지사례
마무리
회사에서 실제로 추천시스템을 어떻게 적용할까
아마존, 넷플릭스, 링크드인 그리고 판도라 등의 회사들은 유저가 새롭고 관련성높은 아이템을 쉽게 발견하게 하기 위해서 추천시스템을 이용한다. 이로 인해 유저들은 즐거운 경험을 하게 되며, 매출의 향상에도 기여하는 효과를 가져온다.
1. Content-based recommendation (콘텐츠 기반 추천)
: 유저 또는 항목에는 특성을 설명하는 프로필이 있으며 시스템은 두 프로필이 일치하는 경우 유저에게 항목을 추천
- Pandora
각각의 음악이 400개가 넘는 속성으로 라벨링됨
유저가 음악 스테이션을 선택하면, 음악 스테이션의 속성에 매치되는 음악이 유저의 플레이리스트에 저장(Music Genome Project)
👉🏻 문제점 : 음악팀이 수작업으로 음악 속성을 생성하는데 많은 노력과 비용이 소요됨
하지만 이러한 노력은 아래의 다양한 경우에서는 불필요해질 수 있다.
- Stitch Fix - 고객은 자신의 선호도를 제공
- Linkedin - 사용자는 자신의 작업 경험과 기술을 제공
- Amazon - 판매자는 제품 항목에 대한 정보를 제공
어떤 경우에는 자신의 선호를 직접 전달하기도 하고, 스스로의 경험과 스킬들을 제공해준다. 모두 콘텐츠 기반 추천에 자유롭게 사용할 수 있다.
1.1. Content-based 추천 방법
-
Keword matching
사용자와 항목을 일치시키는 간단한 방법으로는 키워드를 일치(matching)시키는 것이다.
예를 들어 직업 추천의 경우 직업 설명을 구직자의 이력서와 일치시킬 수 있다.
Term frequency-inverse document frequency(TF-IDF; 단어빈도-역문서빈도)이 항목이나 사용자에 대해 고유한 키워드에 더 많은 가중치를 부여하는 데 주로 사용됨
-
Building a supervised model
보다 체계적인 방법은 사용자가 좋아할만한 경향이 있는 아이템을 추정하는 지도학습 모델(supervised model)을 구축하는 것이다.
모델에서 사용하는 학습특성(features)은 아래와 같다.
(1) 사용자와 항목의 속성(표시변수, 예: 구직자와 직업이 같은 산업에 있는지)
(2) 사용자가 항목을 좋아하는지 여부(응답변수, 예: (구직자가 해당 직업에 지원하는지)
1.2. Content-based 추천 특징
장점
- contents 기반 방법은 계산적으로 빠르고 해석하기 용이하다.
👉🏻 새 항목이나 새 사용자에게 쉽게 적용할 수 있다.
단점
- 항목/사용자의 일부 특성은 명확하게 포착하거나 설명하기 쉽지 않을 수도 있다.
[단점 극복 사례] Stitch Fix는 머신러닝이 정형 데이터를 처리하고 사람이 비정형 데이터(예: 사용자의 Pinterest 보드)를 처리하도록 하여 일부 특성을 알기 어려운 문제를 해결하도록 하였다.
2. Collaborative Filtering (CF, 협업 필터링)
: 항목에 대한 이전 사용자의 선호도(클릭, 시청, 구매, 좋아요, 평가 등)를 기반으로 추천하는 방식
선호도는 사용자 항목 행렬로 표현
- 5개 항목에 대한 4명의 사용자 선호도를 설명하는 행렬의 예
여기서 p_{12}는 항목 2에 대한 사용자 1의 선호도이다.
영화 등급처럼 항목이 숫자인 경우도 있지만 대부분의 경우에는 이진수이며(예: 클릭, 시청, 구매),
실제 사용자 항목 행렬은 수백만*수백만(예: Amazon, Youtube) 이상일 수 있으며 대부분의 항목은 아래와 같이 누락된다.
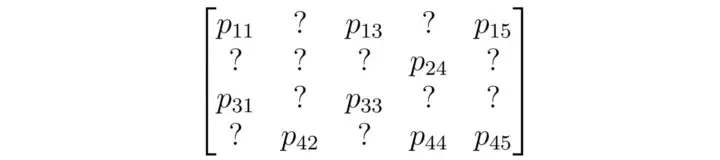
추천 시스템의 목표는 누락된 항목을 채우는 것이다.
협업 필터링 접근 방식에는 세 가지가 있다. Nearest neighbor 하나와, 행렬 분해/딥러닝 방식의 Latent Space 두 가지이다.
2.1. CF 접근 방식(1) - Nearest neighbor (최근접 이웃 기반 방법)
: 아이템 또는 사용자 쌍 간의 유사성을 기반으로 하는 방식
코사인 유사도는 여기에 자주 쓰이는 거리 계산방식이다.
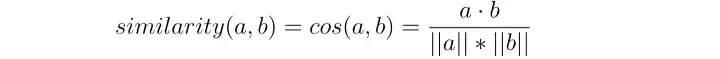
선호도 행렬은 항목 벡터로 나타낸다.
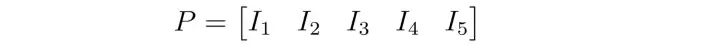
항목 I1 과 항목 I2 간의 유사성은 cos(I1,I2) 로 계산되고, 행렬은 사용자 벡터로도 나타낼 수 있다.
U1 과 U2 사이의 유사성은 cos(U1,U2) 로 계산된다. (기본 설정 매트릭스의 누락된 값은 일반적으로 0으로 채워진다.)
가장 유사한 사용자가 좋아하는 항목을 추천하거나(user-to-user)
사용자가 좋아한 항목 중 가장 유사한 항목을 추천할 수 있다.(item-to-item)
item-to-item(항목 대 항목) 접근 방식
: 각 아이템의 유사아이템이 미리 계산되어 데이터 저장소에 저장되어 있어 고객이 어떤 항목을 좋아하면 Item-to-item 시스템이 유사항목을 빠르게 표시
항목 간 추천은 사용자 간 추천보다 해석하기 더 용이하다. 시스템은 항목이 추천된 이유를 당신이 좋아요를 눌렀기 때문이라고 설명할 수도 있다.
Amazon(2003), Youtube(2010), Linkedin(2014) 등에서 실제로 일반적으로 적용되어 왔다.
- [사례] Youtube(2010)
유사 아이템 수가 너무 적을 때는 유사한 아이템의 유사 아이템을 포함하여 유사한 항목 목록을 확장
가장 유사한 항목을 가져온 후에는 후처리 단계로 아래의 세 가지 요소를 선형 모델과 결합하여 최종 순위를 제공- 동영상 품질(예: 평점으로 측정)
- 다양성(예: 한 채널의 추천 제한)
- 사용자 특이성(예: 사용자가 더 많이 본 동영상과 유사한 동영상은 사용자에 대해 더 높은 순위를 매김)
2.2. CF 접근 방식(2) - Latent-factor methods (잠재 요인 방법)
: 기존의 사용자/아이템 벡터의 특징 공간을 감소시키고 특징 공간을 새롭게 생성하는 방식, 실시간으로 노이즈를 줄이고 계산 속도를 높이는 효과
잠재 요인 방법 두 가지
- 행렬 분해(2.2.1)
- 딥러닝(2.2.2)
2.2.1. Matrix factorization (행렬 분해) - Simon Funk’s SVD
Matrix factorization은 Netflix 추천 챌린지에서 널리 사용되었던 방식으로, 특히 특이값 분해(SVD; Singular Value Decomposition)와 보다 실용적인 버전이 많이 사용되었다.
특이값 분해(SVD)는 선호도 행렬을 다음과 같이 분해(U 와 V 는 단일 행렬)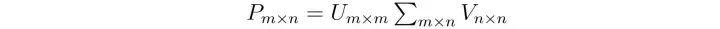
(i) 사용자 4명과 항목 5개의 경우 다음과 같다.
여기서 sigma_1 > sigma_2 > sigma_3 > sigma_4
(ii) 첫 번째 항목에 대한 첫 번째 사용자의 선호도는 다음과 같이 쓸 수 있다.
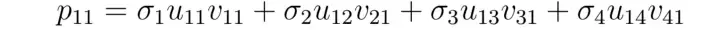
(iii) 이것은 벡터로 나타낼 수 있다.
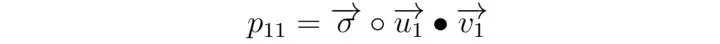
(iv) 시그마 벡터와 첫 번째 사용자 벡터 사이에 요소 곱(entrywise product - 아다마르 곱)이 적용된 다음 첫 번째 항목 벡터와의 내적이 적용된다. u와 v가 동일한 길이를 갖는 것을 볼 수 있습니다. 즉, 동일한 잠재 요인 공간에 있다. 시그마 벡터는 각 기능의 중요도를 나타낸다.
(v) 시그마를 기반으로 상위 두 요인을 선택한다.
이 두가지가 아이템과 유저벡터로서 표현되며 각각 2의 길이를 가진다.
Simon Funk’s SVD
선호도 행렬에 아주 많은 요소들이 있을때는 빈 값들이 많을 수 있다. 그리고 일반 SVD는 다음과 같은 문제가 있다.
- 전가된 빈 값들이 결과에 원치 않는 영향을 미칠수 있다.
- 모든 항목을 고려하면 훈련을 위한 계산 복잡성이 높을 수 있다.
Netflix 챌린지 동안 Simon Funk가 수식에서 누락되지 않은 항목만 고려하는 실용적인 솔루션을 제시했다(2006).
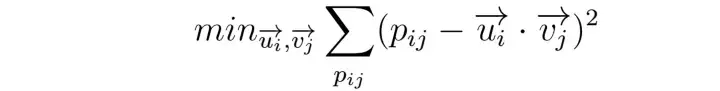
식에 따르면 i^{th} 사용자 의 j^{th} 항목 에 대한 예상 점수는 다음과 같다.
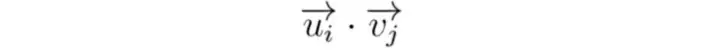
사용자 및 아이템 벡터에는 SVD에서와 같이 단위 길이가 없지만 오류에 대한 제곱합이 최소화되므로 문제가 되지 않는다.
2.2.2. Deep learning embedding (Deep Learning 임베딩)
딥러닝은 행렬 분해보다 더욱 유연하게 사용할 수 있다.
(예를 들어 딥 러닝은 원래 단어 유사도 계산에 사용하는 skip-gram 모델을 활용하여 순차적 정보를 모델링하는 데 사용되었다.)
예를 들어 유저 아이템 좋아요 순서가 item1 -> item2 -> item3 -> item4... 와 같이 이어졌다면, 직관적으로 시퀀스의 각 항목을 이용해 콘텐츠의 예측을 할 수 있을 것이고, 이를 위해 분류 문제로 보고 하나의 아이템을 하나의 클래스로 정의하는 식으로 문제를 해결
학습데이터는 item이 인접하는 K개의 item들을 가지는 형태로 학습된다.(왼쪽 K개와 오른쪽 K개를 가지는 식으로 계산)
K = 1인 경우 항목 쌍
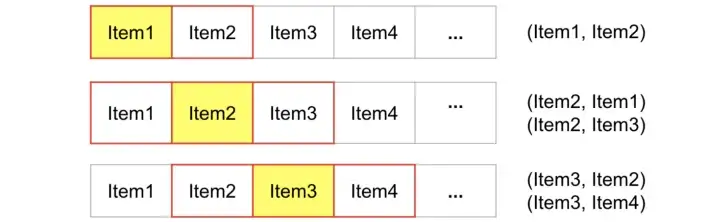
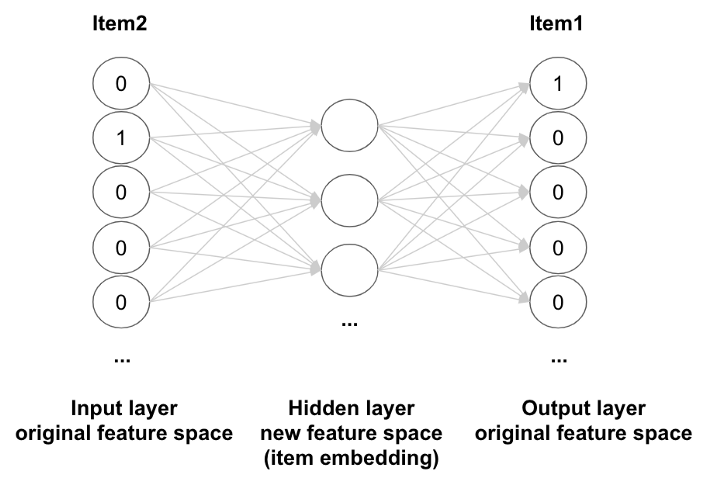
- 각각의 아이템은 하나의 one-hot vector로서 표현되고, 벡터의 크기는 아이템의 갯수와 같다.
- 인공 신경망은 하나의 아이템의 one-hot 벡터를 input으로 받게 되고 유사 아이템 중 하나를 output으로 받게 된다.
히든 레이어는 새로운 피쳐 공간(또는 잠재 공간)인데, 각각의 아이템이 새로운 피처 공간으로 인풋/아웃풋 사이의 가중치를 통해 전이된다.
item2와 item2를 이용해서 학습에 사용
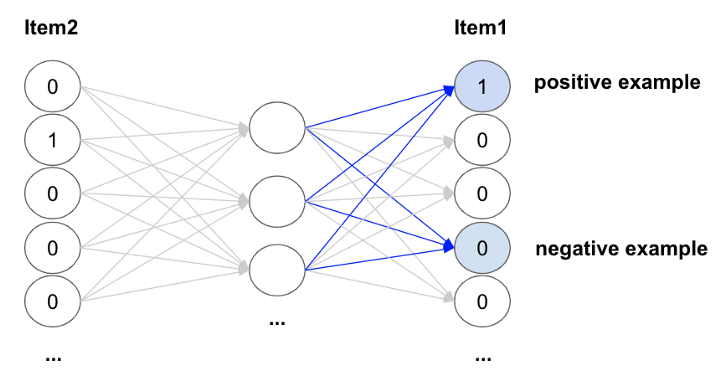
실제로는 수십억 개의 train이 네트워크를 훈련하는 데 사용되기 때문에 계산을 단순화하기 위해 negative sampling 방식을 적용
- negative sampling : output 아이템(아이템 1)의 가중치와 임의로 추출된 소수의 다른 아이템만 업데이트하는 것
👉🏻 계산이 훨씬 빨라진다.
positive item과 negative sample 몇 개에 해당하는 parameter을 업데이트
👉🏻 랜덤으로 샘플링 된 단어들을 부정(negative)으로 레이블링한다면 이진 분류 문제가 되어 연산량이 훨씬 적어짐
하나의 아이템이 새 피쳐 공간에 들어오면 아이템간의 유사도를 계산할 수 있으며 유사도 스코어에 따라 추천 아이템이 정해진다.
사용자가 아이템들을 방문하는 경우 구매한 아이템을 모든 아이템의 train 쌍으로 추가함으로써 전환율을 높일 수 있다.
[예시]
Amazon 사용자는 몇몇의 페이지를 본 후에 구매한다.
에어비앤비 사용자가 몇 개의 숙소를 본 후 숙소를 예약한다.
구매한 아이템을 아이템의 train 쌍으로 추가

Hybrid approaches
: 사용자와 항목 간의 상호 작용과 사용자/항목 특성 정보 모두를 사용하는 방식
특징
-
사용자/항목에 활동이 없거나 적을 때 콘텐츠 기반 추천 항목들에 의존할 수 있음
-
더 많은 데이터를 사용할 수 있을수록 더 높은 정확성
사례 1) Losistic regression classifier by Linkedin
Linkedin의 "팔로우하고 싶을지도 모르는 회사" 기능은 콘텐츠와 협업 필터링 정보를 모두 사용했다. 사용자가 어떤 팔로우할 회사를 결정하기 위해 특징셋을 기반으로 로지스틱 회귀 분류기가 구축된다.
분류모델에는 다음과 같은 정보가 포함된다.- 협업 필터링 정보 - 사용자가 이미 팔로우한 회사와 유사한 회사인지
- 콘텐츠 정보 - 사용자와 회사 간의 업종, 위치 등이 일치하는지
사례 2) Deep learning model by Youtube
딥러닝 모델은 협업 필터링과 콘텐츠 기반 정보를 결합하는 데 강력하다. YouTube 추천 시스템(2016)은 사용자의 이전 활동(검색 쿼리 및 시청한 동영상)과 정적 정보(성별, 위치 등)를 기반으로 사용자의 시청을 예측하기 위해 딥러닝 모델을 구축했다.- 시청한 동영상 및 검색어는 임베딩으로 표현
- 신경망은 사용자가 시청한 비디오 또는 쿼리 벡터의 평균을 구하고 다른 정적 특성과 연결
3. Cold start, Scalability, Interpretability, and Exploitation-Exploration
3.1. Cold start problem
: 사용자와 아이템간 상호작용에 의존하는 협업필터링 추천 시스템의 전형적인 문제점으로 정보가 없거나 적은 사용자/아이템에서 정확한 추천이 불가한 문제
👉🏻 해결방안으로 휴리스틱 방식들이 적용될 수 있다.
- 새로운 유저에게 그 유저 공간의 가장 유명한 아이템들 추천
- 새로운 아이템에는 어떤 규칙 기반의 유사 영역 정의
[사례] Airbnb
동일한 유형 및 가격 범위의 지리적으로 가장 가까운 3개 숙소의 리스트 평균을 사용하여 새 숙소를 추정
3.2. Scalability (확장성)
확장성은 사용할 추천 시스템 유형을 결정할 때 핵심 요소이다.
더 복잡한 시스템은 구축/유지 관리하기 위해 큰 비용과 함께 더 많은 사람이 필요할 수 있다. 또 오랜 기간의 노력이 필요하기 때문에, 기업은 비즈니스 이익 증가와 비용 증가를 이해해야 한다.
이를 위해 확장성 있는 시스템 구축하기 위한 몇 가지 핵심 요소는 다음과 같다.
- Offline batch computing and online serving
- Sampling
- Leveraging sparsity
- Multi-phase modeling
- Scale deep networks
3.2.1. Offline batch computing and online serving
: 유저와 아이템이 많으면, 하나는 꼭 배치 시스템으로 오프라인으로 쉽게 추천이 가능해야 함
예) Linkedin은 사용자 항목 이벤트 데이터를 일괄 처리하는 데 Hadoop을 사용한 다음 지연 시간이 짧은 쿼리를 위해 권장 사항을 키-값 저장소에 실시간으로 로드
3.2.2. Sampling (표본추출)
: 수백만 명의 사용자 및 항목을 처리할 때 아이템 또는 사용자를 무작위로 샘플링하거나 중요한 사용자 참여 없이 항목을 제거하는 샘플링을 고려
3.2.3. Leveraging sparsity (희소성 활용)
: 추천 시스템에서 사용자 항목 선호도 행렬은 대부분의 항목이 누락되는 경우가 많습니다. 이러한 희소성을 활용하면 계산 복잡성을 크게 줄일 수 있다.
3.2.4. Multi-phase modeling (다단계 모델링)
[사례] Youtube 추천 시스템 - 모델링 프로세스를 두 단계로 나눔
- 첫 번째 단계에서는 사용자 항목 활동 데이터만 사용하여 수백만 명의 후보 중에서 수백 명의 후보를 선택
- 두 번째 단계에서는 추가 선택 및 순위 지정을 위해 후보 비디오에 대한 더 많은 정보를 사용
3.2.5. Scale deep networks (뉴럴 네트워크 확장)
- training을 위해 output layer에서 softmax나 다른 함수를 사용하지만 실시간 서빙 시간 동안에는 확률을 계산할 필요가 없다.
- 마지막 hidden layer의 output에 대해 Nearest-neighbor 접근법을 사용할 수 있다.
- 네거티브 샘플링도 고려하여 각 교육 예제에 대해 소수의 클래스 가중치만 업데이트되도록 할 수 있다.
3.3. Interpretability (설명가능성)
> 고객 측에서
고객측면에서는 추천 이유를 설명하는 것이 도움이 될 수 있다.
예) Youtube는 사용자에게 동영상을 추천할 때 사용자가 본 동영상에 대한 링크와 함께 추천(2010)
> 모델링 측면에서
개발자가 시스템을 이해하고 디버그하는 데 도움이 된다.
콘텐츠 기반 접근 방식은 해석하기 쉬운 반면 협업 필터링 모델은 특히 잠재 공간에서 이해하기 어렵기 때문에, 원래 특성 공간 또는 잠재 공간(행렬 분해 및 딥 러닝)을 기반으로 항목 또는 사용자를 클러스터링하고 동일한 클러스터의 개체가 유사한 특성을 공유하는지 확인할 수 있다.
> t-SNE 알고리즘(Maaten, 2018)
또한 t-SNE 알고리즘을 사용하여 고차원 공간을 2차원 공간으로 시각화하거나 추천이 정상적으로 되고 있는지 sanity를 확인하는 툴로서 사용할 수 있다.
예) Airbnb는 추천을 검증하기 위한 내부 탐색 도구를 개발(2018)
3.4. Exploitation-Exploration (활용과 탐험)
추천 시스템은 local minimmum(지역최적점)에 갇히지 않도록 과거 사용자 항목 선호도 데이터에 과적합되지 않아야 함
3.4.1. 방지사례(1) - Youtube
-
학습을 위해서 다른 사이트에 게재되었던 비디오를 학습용으로 사용(2016)
YouTube 사이트 외부에서 시청한 동영상은 추천 시스템에서 나온 것이 아니므로 효과적으로 새로운 콘텐츠를 표시할 수 있다.
또한 추천시 임의성을 포함시키는데 사용하기도 한다.(예: 무작위 권장 사항 만들기) -
시스템에 간단한 규칙을 추가하여 추천의 다양성을 높임(2010)
예를 들어 너무 비슷한 동영상은 제거하고 같은 채널에서 나오는 동영상의 수를 제한한다.
3.4.2. 방지사례(2) - Multi-armed bandits by Uber eats(2018)
*Multi-armed bandit problem
: 한 쪽을 극대로 추구했을 때 최대의 이익을 추구할 수 없고, 그렇다고 이 둘을 동시에는 극대로 추구할 수 없는 trade-off 관계에서 이러한 trade-off를 효과적으로 분배하는 문제
- Uber eats는 추천 레스토랑/음식의 다양성을 높이기 위해 신뢰 상한을 적용
예상 성공률(예: 주문률, 클릭률, 시청률)의 상한선을 사용한다.- 아무 정보 없이 새 항목이 도착하면 신뢰 구간이 넓으므로 상한이 높음 👉🏻 새 항목이 추천될 가능성↑
- 항목이 더 많이 노출될수록 추정치가 더 정확해지고 상한값이 실제값에 더 가까워짐
마무리
이 글은 추천 시스템 구축을 위한 방법론과 주요 관점에 대해 설명한다. 실제로 기업은 리소스에 대한 현실적인 제약 조건(예: 엔지니어 및 소프트웨어/하드웨어 비용) 하에서 정확성, 복잡성 및 비즈니스 영향과 같은 여러 요인을 기반으로 선택해야 한다.
