Hyper parameter
: model에서 사용자가 직접 설정해 주는 값
Callbacks
: 모델이 학습을 시작하면 학습이 완료될 때까지 사람이 할 수 있는게 없기 때문에, 학습되는 과정 사이에 학습률을 변화시키거나 val_loss가 개선되지 않으면 학습을 멈추게 하는 등의 작업을 지정하는 함수들
Early Stopping
: 학습중 Over Fitting 판단시, 중간에 학습을 종료하는 기법
ANN의 역전파 방법을 사용해 파라미터 값을 최적화할 때 Epoch를 시행하면서 일정 Cost값 보다 낮아지면(임의의 Cost값 threshold(임계치)를 설정) 또는 이전보다 Cost값이 갑자기 증가하는 순간 Epoch 시행을 멈추는 콜백함수이다.
아래와 같이 지정
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping()
model.fit(X_train, Y_train, epoch = 1000, callbacks = [early_stopping])EarlyStopping 조건 설정을 위한 파라미터
EarlyStopping(monitor = 'val_loss', min_delta = 0, patience = 0, mode = 'auto')
-
monitor
조기종료를 위해 관찰하는 항목으로 val_loss나 val_accuracy를 주로 사용, defalut값은 val_loss -
min_delta
개선되고 있다는 것을 판단하기 위한 최소 변화량, default : 0 -
patience
Validation Loss에 개선이 없으면 몇 번 기다렸다 학습을 중지할 지, default : 0 -
mode
개선이 없다고 판단하기 위한 기준, auto, min, max가 있고 min/max는 관찰값이 감소/증가하는 것을 멈출 때 학습을 종료
다중 분류 손실 함수인 categorical_crossentropy와 sparse_categorical_crossentropy 차이점
-
categorical_crossentropy
: 다중 분류 손실함수로 one-hot encoding 클래스로 되어있는 데이터에 사용
출력값이 one-hot encoding 된 결과로 나오고 실측 결과와의 비교시에도 실측 결과는 one-hot encoding 형태로 구성된다.
예를 들면 출력 실측값이 아래와 같은 형태(one-hot encoding)로 만들어 줘야 하는 과정을 거쳐야 한다.[[0 0 1]
[0 1 0]
[1 0 0]] (배치 사이즈 3개인 경우) -
sparse_categorical_crossentropy
: 위와 동일하게 다중 분류 손실함수이지만 integer type 클래스라는 것이 다르다.
예를 들면 출력 실측값이 아래와 같은 형태로 one-hot encoding 과정을 하지 않아도 된다.[0, 1, 2] (배치 사이즈 3개로 했을 때)
with torch.no_grad()
: valid/test 경우 역전파 학습을 하지 않도록 설정
- 사용 이유
검증(혹은 테스트) 과정에서는 역전파가 필요하지 않기 때문에 with torch.no_grad()를 사용하여 기울기 값을 저장하지 않도록 하여 메모리와 연산 시간을 줄이는 역할을 한다.
하지만 model.eval() 함수처럼 dropout을 비활성화시키진 않는다.
modelcheckpoint
: 학습 도중 모델 저장을 저장하는 keras의 콜백함수로 모델이 학습하면서 정의한 조건을 만족했을 때 Model의 weight 값을 중간 저장한다.
아래와 같이 사용
tf.keras.callbacks.ModelCheckpoint(
filepath, monitor='val_loss', verbose=0, save_best_only=False,
save_weights_only=False, mode='auto', save_freq='epoch', options=None, **kwargs
)- monitor(metric)/save_best_only : 모니터할 metric 설정 및 이에 따른 높은 성능의 모델을 저장
- mode - 'auto', 'min', 'max' : val_acc 인 경우, 정확도이기 때문에 클수록 좋으므로 이때는 max를 입력
val_loss 인 경우, loss 값이기 때문에 값이 작을수록 좋기 때문에 min을 입력
auto로 할 경우, 모델이 알아서 min, max를 판단하여 모델을 저장
terminateOnNaN
: loss가 NaN이 발생했을 때 학습을 종료
tf.keras.callbacks.TerminateOnNaN()LearningRateScheduler
: epoch에 따라 학습률을 조정하는 callback
Keras에서 아래와 같이 사용
def scheduler(epoch, lr):
if epoch < 10:
return lr
else:
return lr * tf.math.exp(-0.1)
model = tf.keras.models.Sequential([tf.keras.layers.Dense(10)])
model.compile(tf.keras.optimizers.SGD(), loss='mse')
callback = tf.keras.callbacks.LearningRateScheduler(scheduler)- 인자로 받는 schedule은 epoch index를 조정할 수 있는 function
LearningRateScheduler와 Learning rate decay의 차이점이 궁금해서 알아보았는데 https://neptune.ai/blog/how-to-choose-a-learning-rate-scheduler 를 참고하였습니다.
Learning Rate Scheduling에 대한 가장 일반적인 두 가지 기술은 다음과 같다.
Constant learning rate: 학습 속도를 초기화하고 훈련 중에 변경하지 않음
Learning rate decay: 초기 학습률을 선택한 다음 스케줄러에 따라 점진적으로 감소
따라서 학습률을 스케줄하는 방식으로 learning rate decay 개념이 나왔다고 볼 수 있다. 아래는 decay에 대한 설명이다.
Learning rate decay
: Learning Rate가 높은 경우 loss 값을 빠르게 내릴 수는 있지만 minimum을 지나칠 수 있고 낮은 경우 최적의 학습 단계까지 너무 오랜 시간이 걸린다.
따라서, 처음 시작시 Learning rate(학습률)을 처음에는 높게 잡다가 점차 학습이 진행될수록 학습률을 낮게 설정하는 방법이다.
- Learning rate decay의 종류로 step, cosine, linear, inverse sqrt, constant가 있다.
Batch Normalization
: 배치 정규화는 gradient vanishing과 exploding 문제를 해결하기 위해 training 하는 과정 자체를 전체적으로 안정화하여 학습 속도를 가속시킬 수 있는 근본적인 방법으로서 제안되었다.
레이어마다 정규화하는 레이어를 두어, 변형된 분포가 나오지 않도록 조절하고, Local Minimum에 빠짐을 방지한다.
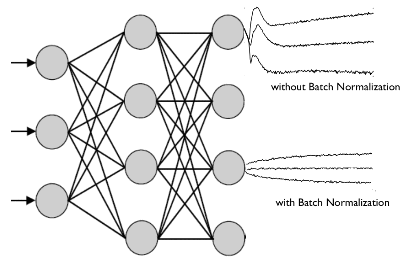
다음과 같은 현상을 방지한다.
- Covariate Shift
: 이전 레이어의 파라미터 변화로 인하여 현재 레이어의 입력의 분포가 바뀌는 현상- Internal Covariate Shift
: 레이어를 통과할 때 마다 Covariate Shift 가 일어나면서 입력의 분포가 약간씩 변하는 현상
