Towards Total Recall in Industrial Anomaly Detection (CVPR, 2022)
arxiv.org
Preliminaries
Anomaly Detection의 Cold Start
- 제한된 label 데이터 : anomaly detection은 보통 normal sample로 모델을 학습시키는 상황에서 이루어지는데, 이때 이상 데이터에 대한 정보가 거의 없거나 전혀 없기 때문에 anomaly를 잘 탐지할 수 있을지 확신하기 어려움
- 불충분한 데이터 : 처음에 사용할 수 있는 데이터가 제한적일 때, 충분한 양의 정상 데이터조차도 확보하기 어려운 경우
- 일반화 문제 : 특정 상황에서나 환경에서만 수집된 정상 데이터는 다른 상황에 잘 인반화되지 않을 수 있음
Anomaly Detection의 주 Approach
1) Recontruction-Based
주로 정상데이터의 분포를 학습하고 inference 시에 input과 비교하는 out-of-distribution 문제로 접근된다.
- Autoencoder(자동 인코더): input 데이터를 압축한 후 재구성하여 입력 데이터와 재구성된 데이터 간의 차이를 통해 이상을 탐지, 정상 데이터는 잘 재구성되지만, 이상 데이터는 제대로 재구성되지 않음
- Generative Adversarial Networks(GANs): 정상 데이터 분포를 학습하는 생성 모델을 사용하여 비정상 데이터를 탐지, GAN을 사용하면 정상 데이터와의 차이를 모델이 학습하게 할 수 있음
- k-NN, Mahalanobis 거리 기반 방법: feature space에서 normal 데이터의 분포를 기반으로, 새로운 데이터가 이 분포에서 얼마나 벗어나는지를 계산하여 이상 여부를 판단
2) Memory bank-Based
- Memory bank: normal 데이터를 기반으로 한 feature을 저장해놓고 테스트할 때 새로운 데이터와 비교하여 이상을 탐지
- 메모리 뱅크는 대규모 데이터에서 처리 및 저장 비용이 많이 들 수 있으며, pretrained 모델의 feature들이 natural 이미지에 편향될 수 있음
Domain Shift
- 모델이 학습한 데이터와 실제 산업 환경에서 사용하는 데이터 간의 차이
- ImageNet에서 학습된 모델의 특징은 natural 이미지에 최적화되어 있어, 산업적 데이터에서 발생하는 결함을 탐지하는 데 적합하지 않을 수 있음
- 이를 해결하기 위해 학습된 feature을 재사용하더라도, 해당 데이터에 맞는 특화된 방식을 사용해야 함
Introduction
Industrial Anomaly Detection에서 "PatchCore"라는 새로운 접근 방식을 제안한 논문이다.
- 특히 결함이 없는 정상적인 데이터만을 사용하여 모델을 학습시키는 "cold start" 문제를 해결하려고 했다.
- 테스트 시 사용할 수 있는 정상 정보를 최대한 활용하고, ImageNet 클래스에 대한 편향을 줄이며, 높은 추론 속도를 유지하는 방법을 제안하였다.
- 그 방법의 간략한 내용은 다음과 같다.
- mid-level의 patch feature를 활용하여 최소한의 bias로 높은 high-resolution을 다룸
- local 이웃의 feature aggregation을 통해 충분한 공간적 context 유지
- memory bank에서 중복성을 줄이고 메모리 및 inference time을 줄이기 위해 greedy coreset subsampling 도입
결과적으로 MVTec AD에서 거의 완벽한 이미지 레벨 탐지 AUROC(최대 99.6%)를 달성하며, 이전 방법의 오류를 절반 이상 줄였다고 한다. 이와 동시에 빠른 추론 시간을 유지하고, 소수의 샘플로도 기존 방법과 비슷한 성능을 보였다고 한다.
Related Works
related works에서는 PatchCore 이전의 SPADE, PaDiM을 언급하였는데, SPADE와 PaDiM은 industrial anomaly detection에서 자주 사용되는 대표적인 기법들이다. 두 방법은 ImageNe pretrained 모델을 사용해 abnormal 데이터를 탐지하며, 각각의 강점과 제한점을 가지고 있다.
SPADE (Sub-image Anomaly Detection with Deep Pyramid Correspondences)
이미지 전체에서 여러 계층의 피처를 추출한 후, 이를 메모리 뱅크에 저장하고, 새로운 이미지의 패치와 비교하여 이상 여부를 판단
| 장점 | • 다중 스케일에서 이상 탐지 가능 (세밀한 결함부터 전체 구조까지) • 정상 데이터의 메모리 뱅크를 활용하여 새로운 이미지와 비교 |
| 단점 | • 이상 여부를 판단할 때 각각의 패치는 개별적으로 처리되어 패치 간의 지역적 맥락(neighboring context)를 고려하지 않음 |
PaDiM (Patch Distribution Modeling for Anomaly Detection and Localization)
- 이미지를 패치 단위로 나누고, 각 패치의 특징 분포를 모델링
- Mahalanobis 거리를 사용해 정상 패치와의 차이를 측정하여 이상 탐지
| 장점 | • 패치 기반 탐지로 세밀한 결함까지 탐지 가능 • 다양한 크기의 이미지에서도 유연하게 작동 |
| 단점 | • Mahalanobis 거리 계산으로 인해 계산 비용이 큼 • 동일한 위치에 있는 패치들만 비교하기 때문에 이미지의 정렬에 의존적이며 유연성이 부족 - 즉 동일한 결함이 이미지의 다른 위치에 발생했을 때 탐지하기 어려울 수 있음 |
정리하자면 Method에서 소개할 내용은 다음과 같다.
- SPADE와 같이 다중 계층의 특징을 활용하는 대신, PatchCore는 중간 수준의 계층에서만 패치 특징을 추출함으로써 메모리와 계산 비용을 절감하면서도 성능을 유지
- PatchCore는 모든 패치 간 비교를 통해 이미지 정렬에 덜 의존적이고 더 유연한 탐지가 가능
- 그리디 서브샘플링(coreset subsampling) 기법을 도입해 메모리 뱅크 크기를 줄여, 두 방법이 직면한 메모리 및 추론 시간 문제도 효율적으로 해결
결과적으로, PatchCore는 SPADE의 비용 문제와 PaDiM의 위치 의존성 문제를 해결하며, 패치 간의 지역적 맥락을 고려한 효율적인 anomaly detection 모델이다.
Method
1. Locally Aware Patch Features
- Mid-level Feature 사용: PatchCore는 pretrained 모델에서 mid-level의 patch feature를 추출하여 이상 탐지를 수행한다. 중간 수준의 피처를 사용하면 너무 추상적이거나(low-level) ImageNet의 클래스에 너무 편향되지(high-level) 않으면서도 충분히 높은 해상도로 동작할 수 있다.

- Patch Aggregation: 이미지를 작은 패치로 나누고, 각 패치의 특징을 주변 패치와 함께 aggregation하여 지역적 맥락을 고려한다. aggregation 방법은 adaptive average pooling을 사용하여 패치 특징을 집계한다.
- memory bank에서 모든 패치 비교: 정상 데이터에서 추출한 패치 특징들을 메모리 뱅크에 저장하는데, 테스트 패치는 메모리 뱅크의 모든 패치와 비교되어, 동일한 위치에 있지 않더라도 비슷한 정상 패치들과 비교할 수 있다.
2. Coreset-reduced patch-feature memory bank
- 정상 데이터에서 추출한 모든 패치 특징을 메모리 뱅크에 저장하면, 메모리 크기가 너무 커지고, 테스트 시 계산 비용이 크게 증가하기 때문에, PatchCore는 이러한 문제를 해결하기 위해, 코어셋 서브샘플링(coreset subsampling) 기법을 사용
- coreset은 주어진 데이터의 특징을 대표하는 작은 부분집합을 선택하는 기법, 즉 원래 데이터에서 중요한 정보를 유지하면서도, 전체 데이터의 구조를 가장 잘 표현하는 서브셋을 찾는 과정
Coreset Selection 방법 - Subsampling
- minimax facility location 문제에서 사용하는 그리디 알고리즘을 적용하여 subsampling 수행
- 과정:

- 원래 메모리 뱅크 M에서 데이터를 하나씩 선택해, 각 패치가 얼마나 "대표적인지" 측정
- 이를 통해 각 패치가 얼마나 다른 패치들을 잘 대변할 수 있는지 계산하여 가장 중요한 패치를 선택
- 이 과정을 반복해 전체 데이터에서 중요한 패치들을 추출하여 서브셋 MC를 이룸
- 차원 축소: 추가로 패치 특징의 차원을 Johnson-Lindenstrauss 변환을 통해 축소
3. Anomaly Detection with PatchCore
-
PatchCore는 메모리 뱅크에서 정상 패치 특징들을 저장하고, 새로운 테스트 이미지가 들어오면 해당 이미지의 패치 특징을 메모리 뱅크와 비교하여 이상 여부를 판별하는 방식으로 동작
-
이 과정에서, PatchCore는 테스트 이미지의 가장 이상한 패치와 메모리 뱅크에 저장된 정상 패치들 간의 거리를 계산하여 anomaly score를 부여하는데, 이 이상 점수는 image-level anomaly detection과 pixel-level segmentation에 모두 사용
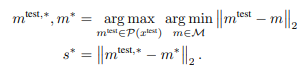
-
과정
- 패치 간 거리 계산: 메모리 뱅크 중 가장 가까운 패치(가장 유사한 정상 패치)를 찾음
- 최대 거리(anomaly score) 계산: 테스트 이미지의 모든 패치 중에서 가장 이상한 (가장 거리가 먼) 패치를 기준으로 이미지의 최대거리를 저장하여 anomaly score로 사용
- anomaly score 조정: 근접 패치들의 거리를 추가적으로 참조하여, 정상 패치들 사이에서 드문 패치일수록 anomaly score를 높게 부여
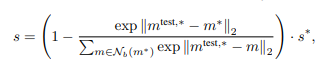
여기서 $N_b(m^*)$는 메모리 뱅크에서 가장 가까운 정상 패치 주변의 패치들이며, 이들의 거리를 사용해 점수를 재조정
-
이미지 전체의 anomaly score를 계산하는 과정에서 각 패치의 공간적 위치도 함께 고려됨
-
결과적으로 각 패치의 anomaly score는 픽셀 단위로 이상이 어디서 발생했는지를 나타내는 anomaly segmentation map을 생성
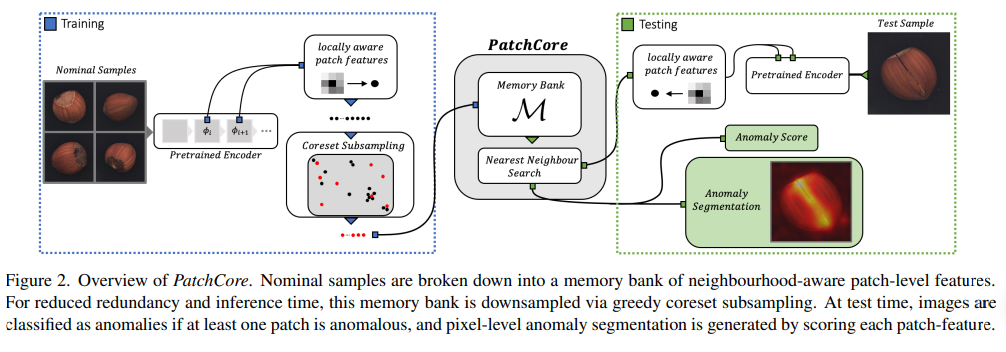
전체적인 아키텍처는 다음과 같다.
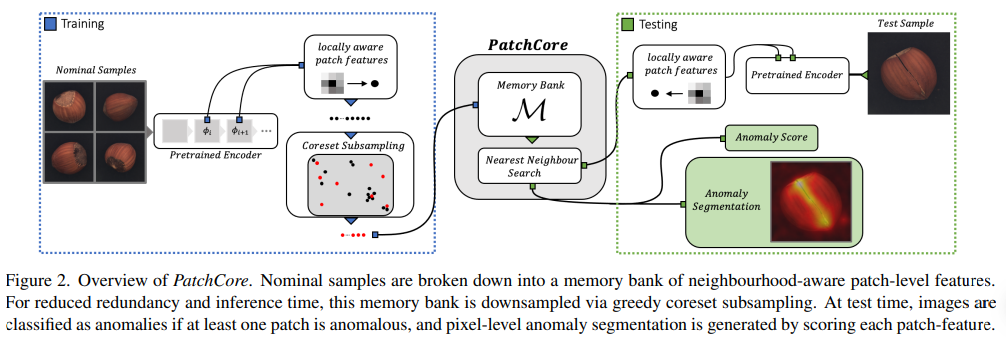
Experiments

PatchCore가 MVTec AD에서 99.6%의 AUROC를 기록하며 이전 방법들보다 좋은 성능을 보여주었고,
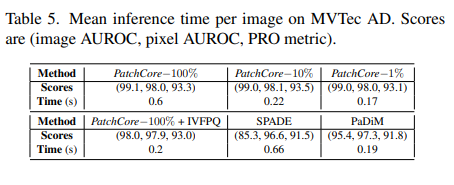
inference time에서도 눈에띄는 감소효과를 보였다.
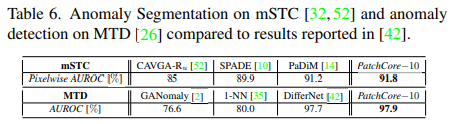
이미지 레벨의 anomaly detection 뿐만 아니라, segmentation 성능도 좋은 결과를 보였다.
