[paper] Attend, Infer, Repeat: Fast Scene Understanding with Generative Models
Computer Vision

이번 논문은 2016년 발표된 논문으로 VAE에 RNN구조를 추가하여 구조화된 이미지 해석이 가능한 프레임워크를 제안하였습니다.
Abstract
객체에 대해 명시적으로 추론하는 구조화된 이미지 모델에서 효율적인 추론을 위한 프레임워크 제시한다.
- 한 scene의 요소들에 주목하고 장면을 하나씩 처리하는 RNN을 사용해서 확률적 추론 수행
- 결정적으로, 모델 자체가 적절한 inference step 수를 학습
이러한 방법을 사용하여 partly- specified 2D 모델(variable-sized variational auto-encoders) 및 fully-specified 3D 모델(probabilistic renderers)에서 추론을 수행하는 방법을 배운다.
supervision 없이도 여러 객체를 식별하고, 장면의 요소를 계산하고, 위치를 찾고, 분류하는 방법을 학습가능 (예를 들어, 신경망의 single forward pass에서 3D 이미지를 다양한 개체 수로 분해하는 방법을 빠른 속도로 수행)
또한 supervised 대조군과 비교했을 때 정확한 inferences을 생성하며, 그들의 구조가 개선된 generalization을 이끌어 냄
1 Introduction
시각적 장면에 대한 인간의 인식은 매우 구조화되어 있음 - 한 장면에서 자연스럽게 공간에 배열된 객체로 분해, 객체들은 서로 기능적 관계를 가짐
때문에 이러한 방식으로 이미지를 해석하기 위해 구조화된 모델을 사용하는 개념은 오랜 역사가 있지만,
- natural scene의 복잡성을 포착할 만큼 표현력이 풍부하고 tractable inference이 가능한 모델을 정의하는 것이 어려움
- deep learning이 발전함에 따라 이미지로부터 해석가능한 구조 없이도 정교한 예측을 할 수 있었지만 이전의 심층 생성모델(ex.VAE)은 대부분 구조화되어 있지 않음 → 인상적인 샘플과 likelihood score를 생성하더라도 해석가능한 의미가 부족
- 구조화된 생성 모델들은 대부분 deep learning과 호환되지 않음 → 추론이 어렵고 느림(ex.MCMC를 통한 inference)
제안하는 프레임워크는 아래를 사용하여 장면을 해석하고 이해
- 학습된 분할 추론(amortized inference)
- 레이블 지도학습이 아닌 덜 정의된 생성모델(partly- or fully-specified)
즉, 좋은 reconstruction을 얻는 것이 아니라 좋은 representation을 생성하는 것(장면을 이해하는 것)이 목적이라고 말한다.
모델 구조는 변수 개수를 강제하는데 학습 과정에서는 장면 요소가 실제로 어떻게 보이며 어떤 이미지에 어디에 나타나는지를 식별한다.
핵심 아이디어 : inference를 반복 과정으로 취급하여, 하나의 객체를 한 번에 처리하고 각 이미지에 대해 적절한 수의 inference step을 학습하는 RNN으로 구현하는 것 => Attend-Infer-Repeat(AIR)
2 Approach
장면 해석에 bayesian 개념을 사용
- prior p(z|θ) : underlying scene에 대한 가정
- likelihood p(x|θ) : 어떻게 장면 설명이 이미지로 렌더링 되는지를 나타내는 모델
- z_i : 객체 하나의 특성을 설명
prior와 likelihood는 다양한 형태를 가질 수 있음
두 종류의 변수를 각각 z_i what 및 z_i where로 참조하여 위치와 크기 또는 위치와 방향으로 정의될 수 있음
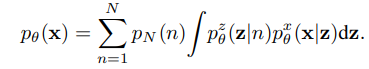
과정
(1) 적합한 prior에서 객체 수 n을 샘플링
(2) 장면을 설명하는 latent variable z = (z1 , z2 , ... , zn)는 scene model에서 z ∼ p(z|θ)(n)에 따라 샘플링
(3) 이미지를 렌더링하며, x ∼ p(x|θ)(z)에 따라 이미지를 생성
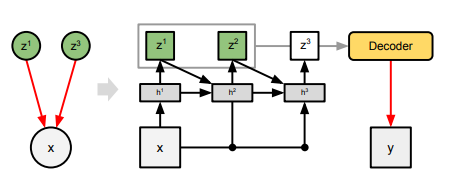 기존 VAE에 RNN을 더해 구조 확장
기존 VAE에 RNN을 더해 구조 확장
효과
- latent representation을 여러개로 만듦으로서 variable demension 커버
- supervision 없이 훈련된 빠르고 피드포워드(feed-forward), 해석 가능한 장면 이해가 얻어짐
2.1 Inference
amortized variational approximations
위에서 제시한 식의 형태로 추론이 어렵기 때문에 φ로 매개변수화된 분포 qφ(z, n|x)를 학습하여 true posterior distribution에 대한 미적분(KL) 발산을 최소화하는 것과 같은 근사 방법 사용(VAE의 reparameterization)
근사 방법을 통해 생긴 어려움
(1) 차원 이동(Trans-dimensionality): 잠재 공간 크기 n(즉, 객체의 수) 자체가 랜덤 변수이며, 이로 인해 모든 n = 1...N에 대한 pN(n|x) = ∫ p(z, n|x)dz를 평가해야 함
(2) 대칭성(Symmetry): 예를 들어, 이미지 x에 나타나는 객체를 잠재 변수 z_i에 대체할 수 있는 대체 할당에서 발생하는 강력한 대칭성이 있음
이러한 어려움을 해결하기 위해 RNN으로 구현된 반복적인 과정으로 inference,
객체의 수에 대한 순차적 추론을 단순화하기 위해 n을 가변 길이 잠재 벡터 zpres로 매개변수화
posterior
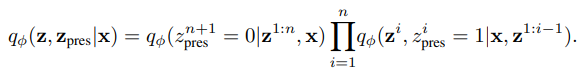
qφ : 신경망으로 구현되며 각 단계에서 잠재 변수에 대한 샘플링 분포의 매개 변수를 출력
z_pres : interruption variable
z_i = {z_what, z_where}
2.2 Learning
marginal likelihood의 lower bound를 최대화하는 방식으로 모델의 매개변수 θ와 추론 네트워크의 매개변수 φ를 동시에 최적화
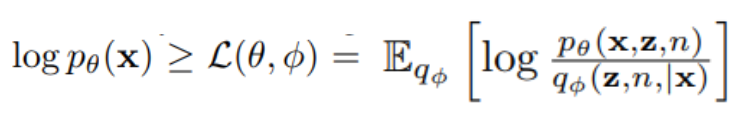
encoder : qφ(z,n,|x)
decoder : pθ(z,n |x)
3 Models and Experiments
 iter가 커질수록 한 객체를 중복하거나 하지 않고 잘 포착
iter가 커질수록 한 객체를 중복하거나 하지 않고 잘 포착
정리하자면
기존 VAE와의 차이점
- 아키텍처 : RNN 구조를 사용
- 수식 : n(객체 수)이 추가됨
- 목적 : 장면을 잘 이해하는 것(z를 잘 구성)이 목표
