SlowFast Networks for Video Recognition 논문 리뷰
이 모델은 facebook에서 2018년에 발표했으며, 발표 당시 video recognition task에서 SOTA를 달성하며 논문으로 나온 모델입니다.
먼저 이름부터 특이한데요, Slow와 fast가 동시에 존재합니다. 이는 모델에서 제안한 특이한 아키텍처로부터 붙여진 이름입니다.
Introduction
이미지 및 비디오 인식의 맥락에서 공간 및 시간 차원
-
공간 영역과 시간 차원의 차이:
이미지에서는 x와 y라는 공간 차원을 대칭적으로 취급하는 것이 일반적입니다. 그러나 비디오에서는 이미지와 달리 시간(t)이라는 차원이 추가됩니다. 이러한 차원이 추가되면서 비디오에서는 공간과 시간의 대칭성이 더 이상 성립하지 않습니다. -
움직임의 속성: 일상에서는 물체나 인물의 움직임이 크게 빨라지는 경우보다는 느린 움직임이 더 자주 나타날 수 있습니다.
말이 어려운데, 예를 들어 손을 흔드는 동작은 "손"의 정체성은 흔들기 동작 동안에도 변경되지 않고, 사람은 걷는 동작에서 뛰기로 전환하더라도 항상 "사람" 범주에 속한다는 것입니다. 따라서 범주적 의미론(색상, 질감, 조명 등)의 인식은 비교적 천천히 새롭게 갱신될 수 있습니다. 그러나 수행 중인 동작은 주체의 정체성보다 훨씬 빠르게 진화할 수 있습니다. 예를 들어 박수치기, 손 흔들기, 흔들림, 걷기, 뛰기 등이 해당됩니다. 이러한 빠르게 변하는 동작을 효과적으로 모델링하기 위해 빠른 갱신 속도(높은 시간적 해상도)의 프레임을 사용하는 것이 바람직할 수 있습니다.
2-path Networks
이에 따라 SlowFast 모델은 두 가지 경로를 제시합니다.
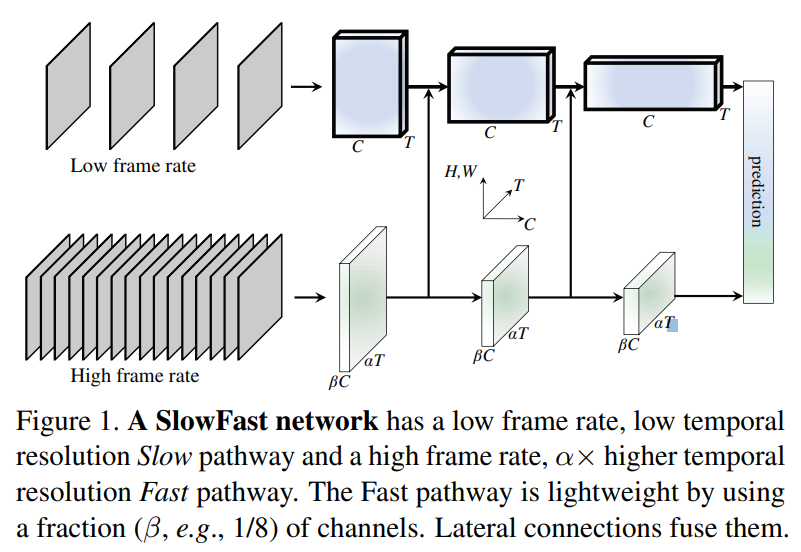
첫 번째 경로는 이미지 또는 몇 개의 희소한 프레임에서 얻을 수 있는 의미 정보를 캡처하도록 설계되어 낮은 프레임 속도와 느린 갱신 속도를 가집니다.
반면, 두 번째 경로는 빠르게 변하는 동작을 캡처하도록 하며 높은 갱신 속도와 높은 시간적 해상도에서 작동합니다. 이 경로는 매우 가볍게 설계되었고 전체 계산의 약 20% 정도를 차지합니다.
첫 번째 경로를 "느린(Slow) 패스웨이"라 하고, 두 번째 경로를 "빠른(Fast) 패스웨이"라고 부르며, 이는 각각 다른 시간 속도에 기반합니다.
정리하자면 다음과 같습니다.
느린(Slow) 패스웨이:
- 이미지나 희소한 프레임에서 얻을 수 있는 의미 정보를 캡처
- 낮은 프레임 속도와 느린 갱신 속도에서 작동
- 공간 영역과 의미론에 집중
- 약 80%의 계산 차지
빠른(Fast) 패스웨이:
- 빠르게 변하는 동작을 캡처
- 높은 프레임 속도와 높은 시간적 해상도에서 작동
- 가벼운 구조, 약 20% 정도의 계산 차지
이렇게 정리해놓고 단순히 생각하면 slow path가 80%의 계산을 차지하고 fast path가 20%의 계산을 차지하는 것이 의아한데요, Fast path는 모션 정보만 얻어내면 되기 때문에, 디테일한 정보가 필요 없어서 채널 수가 적어도 됩니다. Slow path에 비해서 “베타"만큼 채널을 줄일 수 있게끔 됩니다.
이 비율의 기준도 궁금한데요, 사실 이 모델이 실제 사람의 시신경에서 모티브를 얻은 것이기 때문입니다. 실제 동물의 시각 세포들은 물체의 공간적 도메인을 분석하는 파트와 시간적 도메인을 분석하는 파트가 따로 나뉘어있다고 합니다. 시각 세포 중 20%는 물체의 움직임과 위치를 보고, 남은 대부분의 80% 세포는 색깔과 디테일을 본다고 합니다. 생물학적으로 비율이 정해져 있어서 slowfast에도 이 비율을 그대로 적용이 된 것입니다.
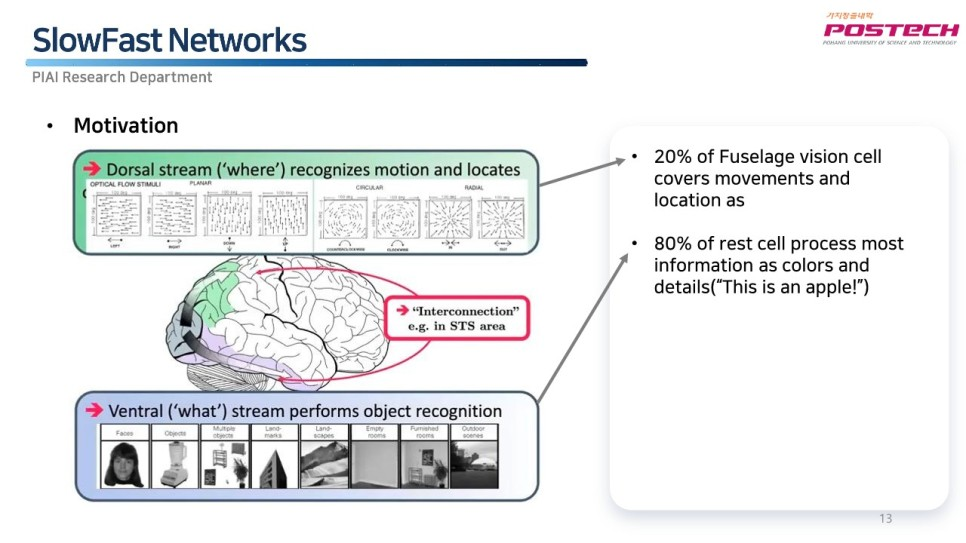
(출처) https://blog.naver.com/112fkdldjs/223033497222
Lateral connections
두 경로는 측면 연결을 통해 통합됩니다. fast pathway는 가벼움으로 인해 모든 중간 레이어에서 높은 프레임 속도에서 작동하고 시간적 충실도*를 유지할 필요가 없습니다. 반면에 낮은 프레임 속도 덕분에 slow pathway는 공간 영역과 의미론에 더 집중할 수 있습니다. 이 방법은 비디오를 다르게 갱신 속도로 처리함으로써 두 경로가 각각의 역할을 수행하도록 하는 것입니다.
(*시간적 충실도 : 빠르게 변화하는 시간적인 특징을 잘 포착하면서도 그 변화를 정확하게 나타낼 수 있는 능력을 갖추고 있다는 것을 의미)
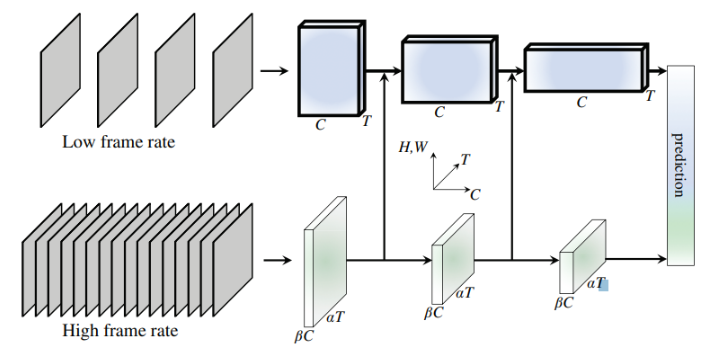
다시한번 사진을 보시면 fast path에서 slow path로 유니 디렉션을 통해 연결을 해주는 것을 볼 수 있습니다. 논문에서는 단방향으로 해도 양방향과 유사한 결과를 얻었다고 언급합니다.
이러한 연결 과정에서 특징의 크기를 일치시키는 것이 필요한데요, Slow 경로의 특징 형태를 {T, S2, C}로 표기하면, Fast 경로의 특징 형태는 {αT, S2, βC}입니다. 다음과 같은 변환을 통해 Lateral connections에서 실험을 진행합니다:
Time-to-channel:
{αT, S2, βC}를 {T, S2, αβC}로 reshape하고 transpose합니다. 이는 모든 α 프레임을 하나의 프레임의 채널로 묶는 것을 의미합니다.
Time-strided sampling:
간단히 말해 α 중에서 하나씩 샘플링하여 {αT, S2, βC}를 {T, S2, βC}로 만듭니다.
Time-strided convolution:
5×1×2 커널을 사용하는 3D convolution을 수행하고 2βC의 출력 채널과 α의 stride를 갖습니다.
측면 연결의 출력은 Slow path에 더하거나 concat하여 통합됩니다.
Results
SlowFast 모델이 가장 높은 성능을 자랑하는 스펙은 Non Local Blocks까지 사용한 모델이라, 소개를 하고 넘어가겠습니다.
Non Local block
Non Local block은 CNN 구조나 Transformer와 같은 모델에서 특정 레이어 또는 블록에 통합할 수 있는 유용한 블록입니다. spatial domain 즉 공간적 도메인 혹은 temperal 도메인 어느 쪽 으로라도 현재 출발하는 지점의 픽셀의 정보가 어떤 frame의 어느 지점과 연관성이 있는지 계산하는 일종의 self attention 네트워크입니다. 이 블록은 시간적으로 긴 범위에서도 정보를 캡처할 수 있어 Action Recognition과 같은 작업에서 성능 향상에 기여합니다.

다시 돌아와서, 실험에서 SlowFast 네트워크는 Kinetics-400, Kinetics-600, Charades 및 AVA 데이터셋에서 평가되었습니다. Kinetics action classification에 대한 실험에서 SlowFast의 기여도가 입증되었으며, 당시 SlowFast 네트워크는 이전 모델에 비해 상당한 성능 향상을 보여주는 새로운 최고 기록을 세웠습니다.
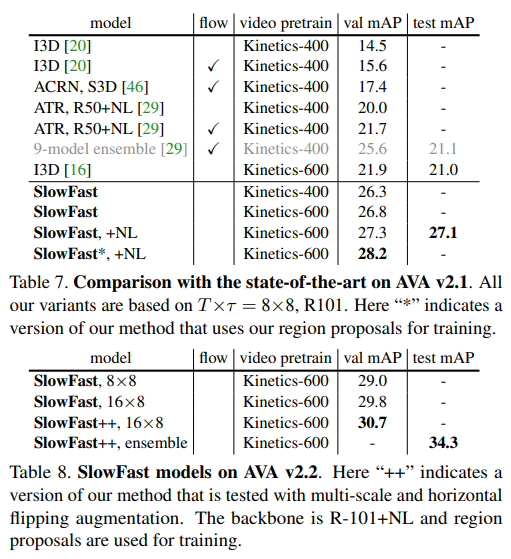
연구원님 블로그를 보다가 알게된 모델인데 이런 공간적인 문맥을 따로 학습하는 네트워크가 있으면 비슷한 이미지가 연속되는 비디오에서도 객체의 직접적인 형태의 변형이 없어도 객체의 이동, 위치를 고려한 상황 학습을 시킬 수 있을까 생각이 들어서 정리했다. 나중에 좀더 조사해보고 태스크에 적용해보려고 하는데, 내가 하고 싶은 태스크는 단순 분류나 인식 태스크가 아니라 조금 더 조사해 봐야 할듯하다.
Reference
https://blog.naver.com/112fkdldjs/223033497222
https://arxiv.org/pdf/1812.03982.pdf
https://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Non-Local_Neural_Networks_CVPR_2018_paper.pdf
