ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation [NeurIPS'22]
github link : https://github.com/ViTAE
Intro
이 논문에서는 ViTPose라는 간단한 베이스라인 모델을 통해서 다양한 측면(모델 구조의 단순함, 모델 크기의 확장성, 훈련 패러다임의 유연성, 모델 간 지식 전달 가능성)에서 자세 추정을 위한 plain vision transformer의 놀랍도록 우수한 능력을 보여준다. 특히 ViTPose는 사람 인스턴스의 특성을 추출하기 위해 일반적이고 비계층적인 Vision Transformers를 backbone으로 사용하고, 자세추정을 위해 가벼운 디코더를 사용한다. 또한, ViTPose는 attention 유형, input의 해상도, 사전 학습과 finetuning 전략, 다양한 포즈 task들에 매우 유연하다. 간단한 지식 토큰을 통해 large ViTPose 모델의 지식을 작은 모델에 쉽게 지식을 전이할 수 있음을 실험적으로 입증하였다. 실험 결과는 basic ViTPose 모델이 MS COCO Keypoint Detection 벤치마크의 대표적인 방법들을 능가하는 것을 보여주며, 가장 큰 모델은 80.9AP로 새로운 sota를 달성하였다.
다른 vision transformer 구조들 대부분은 CNN을 백본으로 적용하였고, 추출된 feature를 개선하고 인체 키포인트 간의 관계를 모델링하기 위해 정교한 구조의 transformer를 사용하였다.
💡 예시
- PRTR- 추정된 키포인트들의 위치를 점진적으로 개선하기 위해 트랜스포머의 인코더와 디코더들 모두 결합
- TokenPose, TransPose - CNN으로부터 추출된 특성을 처리하기 위해 인코더만 포함하는 트랜스포머 구조 채택
- HRFormer - 트랜스포머를 사용하여 특징 직접 추출, 다중해상도 병렬 트랜스포머 모듈을 통해 높은 해상도 표현을 도입
▷ 이러한 방법들은 추가적인 CNN이 필요하거나 task 적용시 트랜스포머 구조를 세심하게 설계해야 함
제안하는 ViTPose baseline
- 사람 인스턴스에 대한 피처맵을 추출하기 위해 평범하고 비계층적인 vision transforemer를 백본으로 사용 - 백본은 마스킹된 이미지를 재구성하는 task(MAE)에 사전훈련되어 있음
- 그리고 나서, 뒤따르는 가벼운 디코더는 추출된 특성들을 피처맵들을 upsampling하고 키포인트에 대한 히트맵을 regressing - 2개의 deconv 레이어와 하나의 prediction 레이어로 구성
특징
ViTPose는 우수한 성능뿐 아니라, 간결함, 확장성, 유연성, 이식성의 다양한 측면에서 놀라운 능력을 보여줌
1. simplicity(간결함)
- ViTPose는 백본 인코더를 설계할 때 어떤 특정 도메인 지식도 필요하지 않음
- 몇 개의 transformer 레이어를 쌓는 것으로 평범하고 비계층적인 인코더 구조를 가질 수 있음
- 디코더는 더 단순화하여 하나의 업샘플링 레이어와 성능 저하가 거의 없는 컨볼루션 예측 레이어로 구성
이러한 구조적 간단함으로 ViTPose가 더 나은 parallelism을 가짐 → 추론 속도와 성능 측면에서 새로운 pareto front에 도달
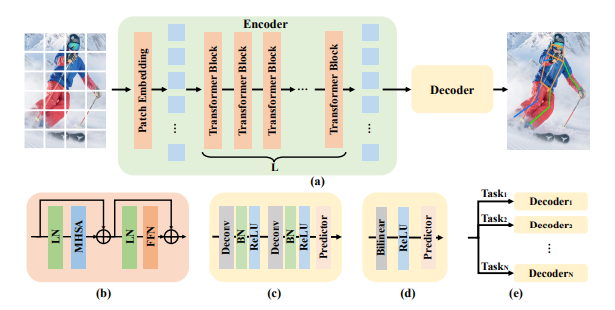
The framework of ViTPose
어떻게?
→ input image X를 patch embedding layer를 통해 토큰으로 변환
- d: patch embedding layer의 downsampling ratio
- c: channel dimension 수
그 다음 임베디드 토큰을 여러 트랜스포머 레이어에서 처리
각 레이어는 Multi-head self-attention(MHSA) 레이어와 feed forward network(FFN)으로 구성
- i : i번째 transformer layer의 output
- 초기 특성 F0 : 패치 임베딩 레이어 이후의 특성
backbone network의 output feature :
백본 네트워크에서 추출된 특성을 처리하는 두 가지 종류의 가벼운 디코더
- classic decoder : 두 deconv 블록으로 구성, 각각은 하나의 deconv레이어와 배치 정규화, ReLU로 구성, feature map을 2배로 업샘플링, 1x1 커널 크기를 갖는 컨볼루션 레이어를 사용하여 key point의 localization heatmap(K)을 얻음
- 더 간단한 디코더 : 피처맵을 bilinear 보간을 사용하여 4배로 업샘플링한 다음, ReLU 3x3 커널을 가진 컨볼루션 레이어를 사용하여 히트맵을 얻음
단순한 디코더의 비선형 용량이 적을지라도, 클래식 디코더와 신중하게 설계된 트랜스포머 기반 디코더와 비교했을 때 경쟁력 있음 → 구조적 간결성 입증
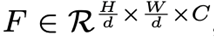
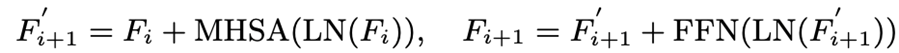
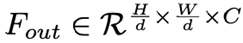
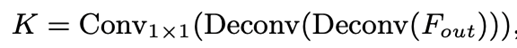
2. scalability(확장성)
- 간단한 구조로 인한 확장성 → 확장가능한 사전훈련된 vision transformer들에서 빠른 개발이 이루어질 수 있는 이점
- 특히, 다양하게 transformer 레이어를 쌓거나 feature 차원을 증가/축소시킴으로써 모델 크기를 쉽게 조절할 수 있으며, ViT-B, ViT-L, ViT-H를 사용하여 추론 속도와 성능 요구사항을 맞출 수 있음
3. 학습, 해상도, attention 종류, task에 대한 flexibility(유연성)
- ViTPose는 작은 수정만으로 입력 이미지의 다양한 해상도와 특성 해상도에 잘 적응
- 더 높은 해상도 이미지에는 더 정확한 결과를 항상 제공
- 일반적인 단일 포즈 데이터셋에서 학습시키는 것 외에도, ViTPose는 추가적인 디코더를 유연하게 추가시킴으로써 다중 자세 추정 데이터셋에도 적용시킬 수 있음
→ joint training pipeline을 생성하고 상당한 성능 향상, 상당히 가벼운 디코더로 인해 아주 적은 추가 연산비용 발생
- (attention type에 대한 flexibility) shift window를 사용하여 인접한 윈도우 사이에 정보를 전달할 수 있도록 함, pooling window를 사용하여 윈도우 안에서 전역적인 문맥 특성을 가져올 수 있도록 각 윈도우의 토큰을 가져오고, 가져온 특성들은 각 윈도우에 공급되어 윈도우 간 특성 전달을 가능하게 함
4. transferability(전이성)
큰 ViTPose모델에서 학습한 지식을 전이시킴으로서 작은 ViTPose모델의 성능을 쉽게 향상시킬 수 있음
knowledge distillation과 토큰 기반 distillation 방법을 보완적으로 사용
1) knowledge distillation2) 토큰 기반 distillation 방법
추가로 학습가능한 지식 토큰 t를 무작위로 초기화하고 teacher모델의 패치 임베딩 레이어 이후의 시각적 토큰에 추가, 학습된 teacher 모델 고정하고 여러 에폭에 걸쳐 지식 토큰만 tuning
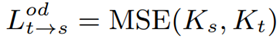
contribution
-
pose estimation에 간단하지만 효과적인 basemodel을 제안, 심지어 정교한 구조적인 설계나 복잡한 프레임워크를 사용하지 않고도 MS COCO Keypoint 데이터셋에 SOTA를 달성
-
구조적인 간단함, 모델 크기의 확장성, 훈련 과정의 유연성, 지식 전이성을 포함한 놀라운 능력
-
인기있는 벤치마크에서의 종합적인 실험을 통해 ViTPose의 능력을 연구하고 분석 - 매우 큰 비전 트랜스포머 모델인 ViTAE-G 를 백본으로 사용할 때, 단일 ViTPose 모델은 MS COCO Keypoint test-dev 셋에서 최고 80.9 AP 달성
comparision with SOTA methods
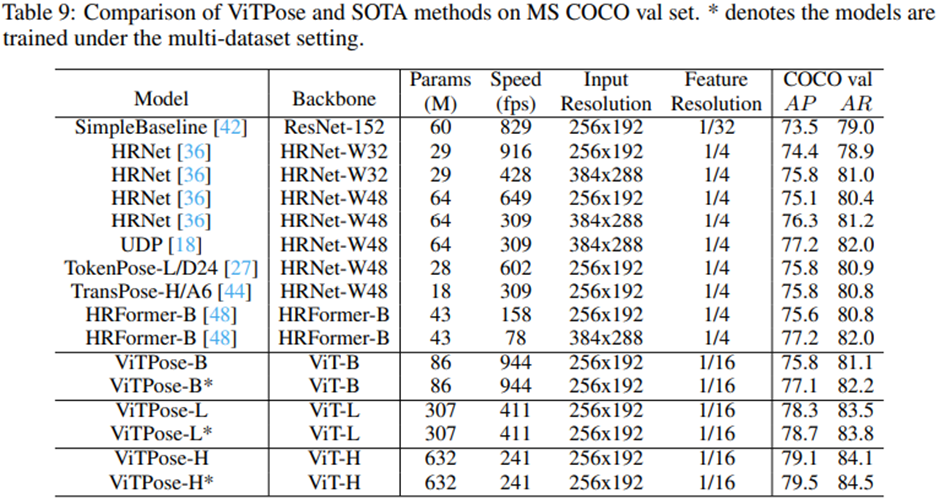
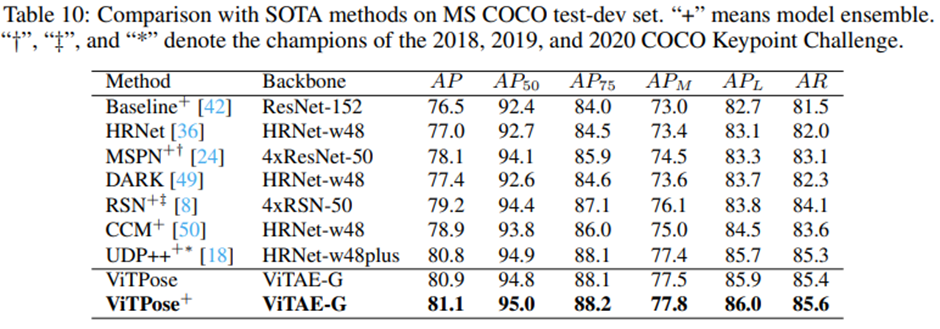
ViTAE-G를 갖춘 단일 ViTPose 모델은 MS COCO 테스트 개발 세트에서 80.9 AP로 최고 performance 달성
