High-Resolution Image Synthesis with Latent Diffusion Models, 2022, CVPR
Stable Diffusion은 2022년 8월 Stability AI에서 발표한 text-to-image 생성 모델로, 오픈소스로 공개되어 인공지능 이미지 생성 분야에서 큰 주목을 받았는데요, 24년 12월 기준 1만 2천회가 넘는 인용수를 가지는 논문입니다. 최근 컴퓨터비전에서 주로 연구 및 발전되고 있는 생성모델 분류이고, 다양한 여러 태스크에서 stable diffusion의 아키텍처를 이용하여 SOTA를 달성한 모습을 많이 볼 수 있습니다.
Introduction
기존의 이미지 생성 모델인 Generative Adversarial Networks(GAN)와 Variational Autoencoders(VAE)는 훈련의 불안정성, mode collapse, 낮은 해상도 등의 문제를 겪었습니다. Diffusion 모델은 이러한 한계를 극복하며 고품질 이미지 생성을 가능하게 했지만, 픽셀 공간에서 동작하므로 높은 cost과 학습 시간이 요구됩니다.
Image generation model의 분류
- Autoregressive(AR) 모델:
- 픽셀 단위로 순차적으로 이미지를 생성하며, 밀도 추정에서 강력한 성능을 보임
- 그러나 낮은 해상도에만 적합하며, 높은 계산 비용으로 인해 고해상도 이미지를 생성하는 데 제약이 있음
- GAN(Generative Adversarial Networks):
- 높은 품질의 이미지를 생성할 수 있지만, 학습이 불안정하며, 데이터 분포의 다양한 모드를 모두 학습하지 못하는 mode collapse 문제를 겪음
- Diffusion 모델(DM):
- 노이즈를 추가하고 제거하는 과정을 통해 이미지를 생성하며, GAN의 mode collapse 문제를 해결
- 그러나 픽셀 공간에서 작동하기 때문에(pixel-level의 reconstruction) 계산 비용이 높고, train 및 test가 비효율적
diffusion model에서 상당한 리소스가 소요된다는 점을 해결하기 위해 저자들은 diffusion model의 학습 단계를 분석했을때, likelihood 기반의 모델들이 다음 그림과 같은 두가지 단계를 거친다는 것을 발견했습니다.
Likelihood based model의 Training Stages
- First, Perceptual compression
- Second, Semantic Compression
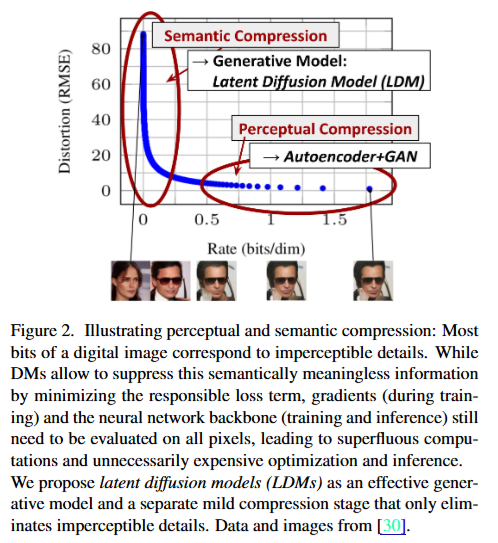
먼저 피규어를 설명하기에 앞서서 Rate(bits/dim)은 압축에 사용되는 비트수인데요, 0에 가까워질수록 압축에 사용되는 비트수가 적기 때문에 크게 압축된 상태라고 보시면 됩니다. 그래서 학습단계에서는 원본 상태(=압축률 낮음, 비트수 많음)에서 압축이 큰 단계로 가는 것이 latent space로 가는 과정이라고 할 수 있겠습니다.
그래서 첫 번째로 perceptual compression 단계에서는 high frequency 영역을 제거하면서 semantic 정보를 유지하는 단계입니다. 그림상에서 오른쪽 하단 부분인데요, 오른쪽 세장의 사진에서 선글라스 낀 남성의 모습이 유지되는 것을 알 수 있습니다.
그러고 나서 Semantic compression 단계를 거친다고 합니다. 이 단계에서는 semantic하고 coneptual한 구성을 파악하는 단계입니다. 그림상에서 왼쪽인데요, 왼쪽에서는 선글라스, 남성 등의 context가 사라지고 사람 얼굴만 유지되는 것을 알 수 있습니다.
그래서 perceptually equivalent하면서, 적합한 space를 찾아서 diffusion 모델을 학습시키겠다는 것이 논문의 요지입니다. perceptually equivalent하다는 것은 원본과 거의 차이가 없는, 즉 피규어 상에서 가장 오른쪽에 있는 사진으로부터 세번째 사진 지점의 latent space에서 high-resolution의 이미지를 위한 diffusion을 학습시키겠다는 것입니다.
Arcitecture
이를 위해 학습단계를 구별되도록 아키텍처를 설정하는데요, 첫번째 단계인 perceptual compression 단계는 Autoencoder, Semantic Compression 단계는 Diffusion Model로 구성을 합니다.
Distinct Training phases
- Perceptual compression → Autoencoder
- Semantic compression → Latent Diffusion Model(LDM)
autoencoder를 통해 효율적인 작은 차원으로 만들면서, perceptual하게 동등한 data space로 만드는 것입니다. 압축된 공간에서부터 diffusion model이 동작하기 때문에, 효율적인 이미지 생성을 할 수 있습니다.
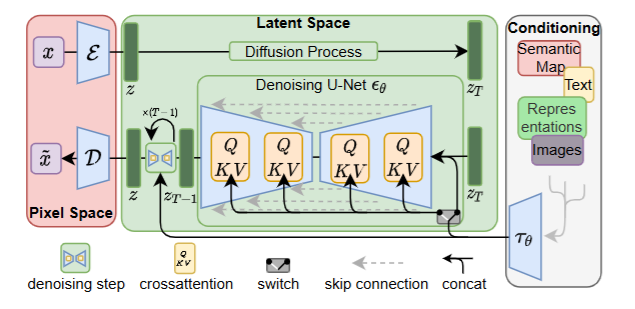
1. Autoencoder
빨간색 부분이 Autoencoder입니다. Autoencoder에서는 perceptual compression을 위해 두가지 loss를 활용하는데요,
- perceptual loss
- patch-based adversarial objective
perceptual loss는 VGG같은 pretrained model을 사용하여 high-level의 featuremap을 뽑아서 원본과 비교하는 형식의 loss입니다. 기존에 주로 사용하는 L1, L2 loss의 경우 pixel-level의 compression, reconstruction을 진행하면서 blurriness 문제가 발생하는데, perceptual loss를 사용하면 피할 수 있고 보다 이미지 매니폴드를 잘 따르게 할 수 있다고 합니다.
patch-based adversarial objective는 PatchGAN에서 사용하는 loss인데, 패치단위에서 패치의 real/fake 여부를 판별하게 만들면서 local realism을 학습할 수 있도록 하는 것입니다.
모델 코드 내에서는 autoencoder가 perceptual loss를 따르도록 하고, autoencoder가 생성한 이미지를 구별해내는 dicriminator가 patch-based loss를 따르도록 하여 adversarial하게 학습을 진행하고 있습니다.
이때 latent space가 높은 variance를 갖는 것을 피하기 위해 논문에서는 두가지 regularization을 언급하는데요,
Regularization for avoiding high-variance of latent space
- KL-reg
- VQ-reg
첫번째로는 latent space가 VAE처럼 정규분포를 따르도록 KL penalty를 주는 것, 두번째는 디코더의 레이어에 vector quantization을 주는 것입니다. 뒤에서 나오는 실험파트에서 VQ-reg가 더 좋았다고 언급합니다.
이렇게 만들어진 latent space는 x의 representation을 잘 보존하고, 적합한 압축률을 가진다고 합니다.
2. Latent Diffusion Model(LDM)
그림상에서 초록색 부분입니다.
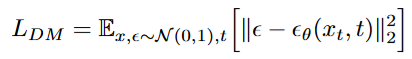
👉 기존의 diffusion model(DM)에서는 노이즈가 정규분포를 따른다고 가정하고, 타임스텝 t에 따른 노이즈를 예측(예측된 noise )하여 L2 loss를 줄이는 방식으로 학습했는데요,
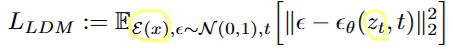
👉 LDM에서는 기존의 DM처럼 노이즈를 예측하는 것은 똑같지만 x대신 오토인코더의 latent space에 임베딩된 feature를 사용하여, 타임스탭 t가 주어졌을때 노이즈 스텝에서의 t시점 잠재공간 z의 noise를 예측하도록 학습합니다.
이렇게 학습하는 것이 pixel-level의 고차원과 비교했을때 likelihood 기반의 모델에 적합하다고 합니다. 즉 이 space가 semantinc bits에 더 잘 집중하고, 학습시 cost가 적다고 합니다.
3. Conditioning Mechanism
기존의 diffusion model의 경우 로 같은 condition y가 주어졌을때 x를 생성하는 작업이 가능했지만, 주로 condition은 클래스 라벨이나 블러리한 이미지로 다른 condition에 대한 탐구가 이루어지지 않았는데요, stable diffusion에서는 LDM에서 → 로 가는 기존의 UNet의 레이어를 어텐션 레이어를 사용함으로써 다양한 모달리티를 condition으로 사용할 수 있습니다.
domain specific한 encoder 로 y를 적합한 latent space로 변환하고, UNet 레이어마다 cross attention을 계산할 수 있습니다.
equation은 다음과 같습니다:
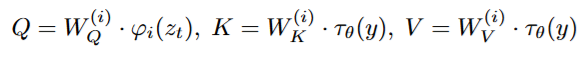
- 여기서 는 UNet의 중간 representation을 attention matrix 계산을 위해 flatten 시킨 노테이션입니다.
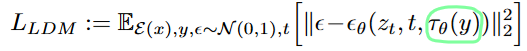
👉 그러면 수식은 기존의 LDM에서 임베딩된 y()가 주어졌을 때의 노이즈를 예측하는 것으로 변형되고, 이 때 두 인코더 과 는 동시에 학습됩니다. 이 메커니즘을 통해 encoder 는 domain에 적합한 expert가 되고, 예를 들어서 text가 condition으로 들어온다고 하면 트랜스포머모델을 사용할 수 있습니다.
Experiments
- Regularization에 대한 실험
AutoEncoder에 대한 regularization으로 vector quantization을 사용하는 것이 성능이 좋았다는 것을 언급하고 있습니다. f는 down sampling 계수인데, 기존 dimension에서 다운샘플링될때 한 비트에 대응되는 픽셀 수입니다.
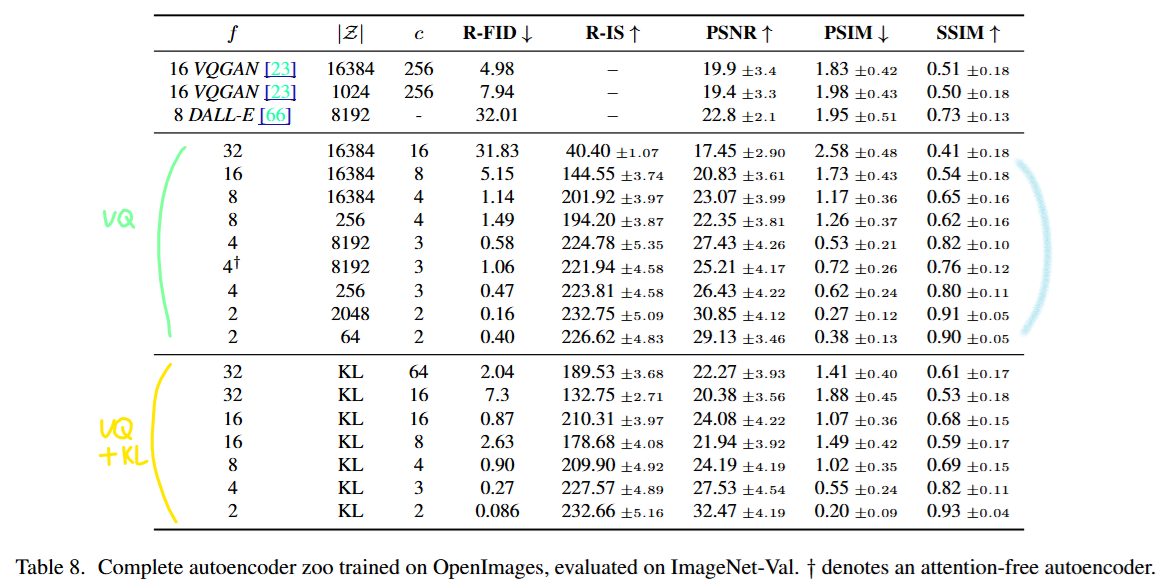
-
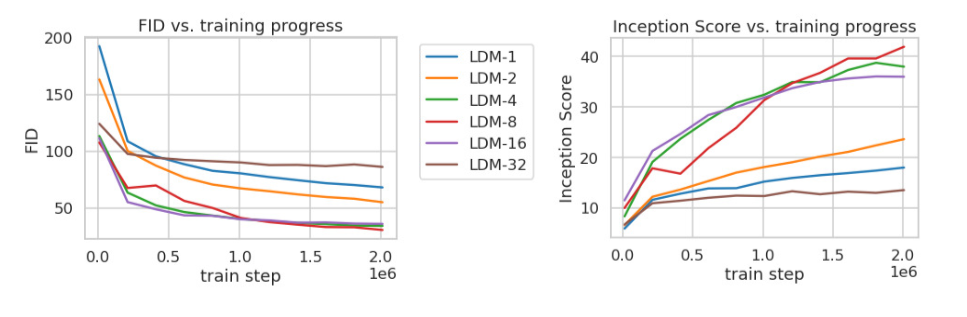
Compression에 따른 성능 비교
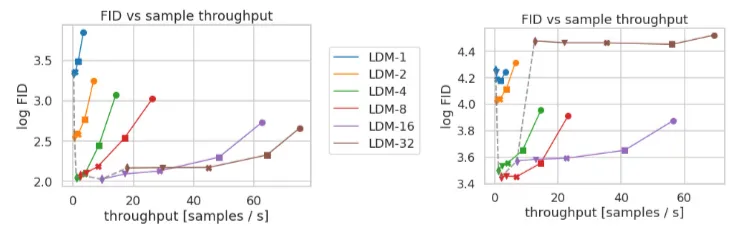
LDM-1은 기존 pixel space의 diffusion model입니다. 아래 figure를 보면 너무 많이 압축된 LDM-32의 경우에는 정보 손실로 인해 일정 train step 이후 충분한 학습이 어렵습니다. 반면 적당이 압축된 LDM-{4, 8, 16}의 경우에는 FID, Inception score모두 좋은 성능을 보이는 것을 확인할 수 있습니다.
CelebA-HQ (왼쪽), ImageNet (오른쪽) 두 데이터셋에서 압축률에 따른 FID score를 확인했을때는, 상대적으로 어려운 ImageNet같은 데이터셋에서는 압축률을 줄여야함을 알 수 있습니다.
-
기타 실험 결과 및 성과
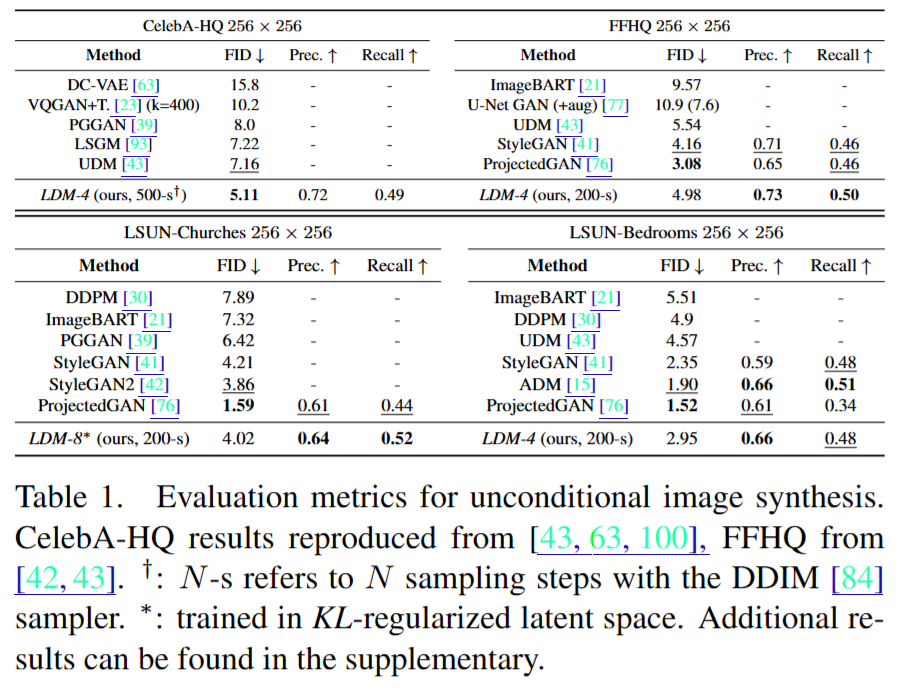
- 기존 모델들과의 성능 비교: 기존의 GAN, VAE 기반 모델들과 비교하여 더 나은 성능과 효율성을 입증하였습니다.
- Text-to-Image, Layout-to-Image, Super Resolution, Inpainting 등 다양한 응용 사례: 텍스트를 통한 이미지 생성, 레이아웃 기반 이미지 생성, 초해상도, 이미지 복원 등 다양한 응용 분야에서 우수한 성능을 보였습니다

- 기존 모델들과의 성능 비교: 기존의 GAN, VAE 기반 모델들과 비교하여 더 나은 성능과 효율성을 입증하였습니다.

