NOPE: Novel Object Pose Estimation from a Single Image은 arxiv 기준 23년 3월에 게재된 페이퍼입니다.
페이퍼 내용에 앞서 6D pose estimation task를 살펴보겠습니다.
먼저 최근 6D Pose estimation은 CAD model과 같은 3D 모델을 사용하여 instance level에서 estimation하거나, 카테고리의 general한 feature를 이용하는 경우(category-level이라고 함)로 크게 분류할 수 있습니다.
approach는 다음과 같이 분류할 수 있습니다.
- Feature-based Methods
이미지에서 특징점을 추출하고,이를 바탕으로 3D공간에서 객체의 위치와 방향을 추정- Neural Surface Reconstruction-based Methods
객체의 3D 구조를 학습하여 6D 포즈를 추정할 때 이 3D구조를 참고하는 방식
ex.NeuSurfEmb- Template Matching-based Methods
사전 생성된 템플릿 이미지와 입력 이미지 간의 유사성을 기반으로 객체의 6D 포즈를 추정하는 방식
ex. GigaPose- Pose Regression-based Methods
단일 RGB 이미지ㅣ로부터 직접적으로 6D 포즈를 regression하는 방식으로 특징점 추출이나 3D 구조 재구성을 하지 않으며, 신경망을 사용해 직접적으로 표즈를 예측하는 방식
최근에는 정확도가 낮은 pose regression 방식보다는 reconstruction-based method를 거친 후 키포인트를 조정하는 방식의 아키텍처로 많이 연구가 이뤄지고 있고, 오늘 소개할 NOPE은 reconstruction, template mathching methods와 가깝다고 볼 수 있습니다.
기존의 object pose estimation (OPE) 방법들은 3D 모델, 다수의 이미지(reference images, 비디오 시퀀스)를 필요로 하고 새로운 객체나 카테고리에 대해 재학습이 필요한 반면에,
NOPE은 single 이미지만으로 새로운 객체의 상대적인 3D pose(rotation)을 예측할 수 있다고 합니다. 또한 3D 모델이나 새로운 instance에 대한 재학습도 필요없다고 합니다.
Framework
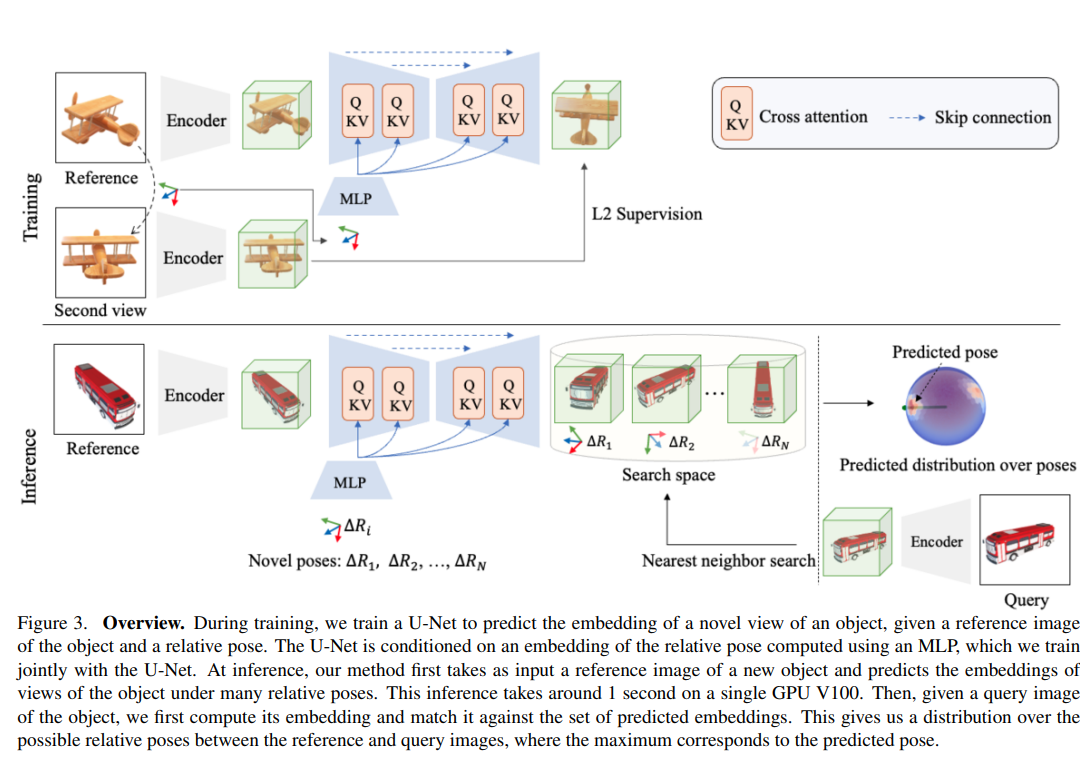
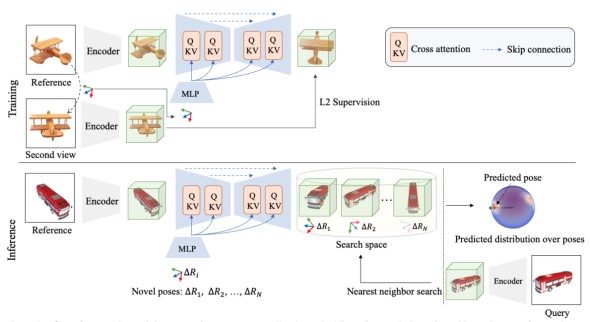
NOPE 모델의 아키텍처는 요약하면 아래와 같은 방식으로 동작합니다.
여기서 논문 제목 때문에 헷갈릴 수 있는 요소가 있는데, 정말 single 이미지에서의 pose estimation이 아니고, 포즈 정보를 가지고 있는 reference 이미지 한장이 필요합니다. 포즈 정보를 알고 있는 reference 이미지 한장만 있으면 category 정보, instance의 CAD 모델, 다수의 reference 이미지(또는 비디오 시퀀스)가 없어도 pose estimation을 할 수 있다,는 것이 이 모델의 contribution이라고 할 수 있습니다.
요약
reference image를 바탕으로 다양한 view에서의 객체의 예상모습(pose포함)을 생성하고,생성한 이미지의 representation을 템플릿으로 사용해 쿼리이미지의 representation과 매칭하여 상대적인 포즈추정
네트워크 구성
네트워크는 U-Net과 같은 모양으로 구성이 되어있고, 이 네트워크는 reference 이미지가 특정 상대적인 포즈에서 어떻게 보일지에 대한 임베딩을 생성합니다.
또 각 레이어에서는 포즈 임베딩을 condition으로 사용하는데, reference 이미지가 주어진 상대적 포즈에서 어떻게 보일지를 예측합니다.
과정
- 이미지 임베딩
reference 이미지와 query 이미지를 U-Net을 통해 임베딩 - 템플릿 생성
reference 이미지에서 객체의 다양한 view에서 보이는 모습을 예측하여 각 view에 해당하는 임베딩 생성
생성한 임베딩은 해당 view에서의 pose 정보를 가진 템플릿이 됨 - 템플릿 매칭
query 이미지와 reference 이미지의 템플릿을 매칭하여 쿼리 이미지에서의 객체의 상대적인 포즈를 추정
Pose prediction
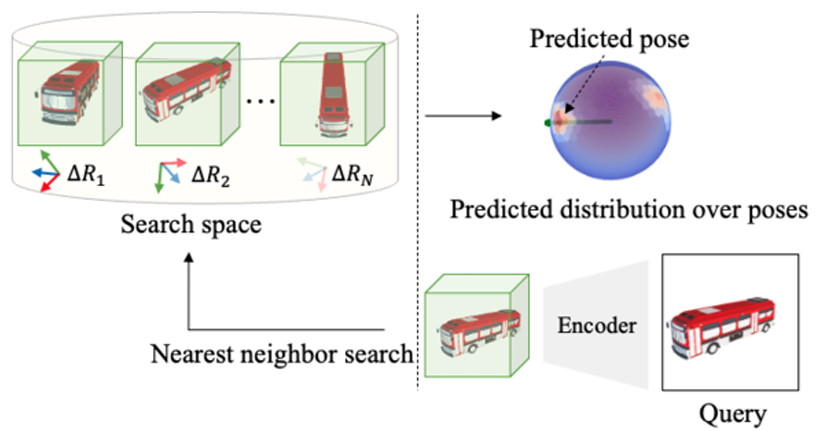
3번째 phase인 템플릿 매칭에 대해서 살펴보면, 아래와 같은 단계로 구성됩니다.
1) 주어진 reference image 와 N개의 상대적 view 에 대해, 각 view에 해당하는 예측된 임베딩을 획득
Templates for 3D Object Pose Estimation Revisited:Generalization to New Objects and Robustness to Occlusions
(link)
따라서 모든 view(342개)에서의 확률이 계산됩니다.
- : reference 이미지
- , : 쿼리/reference 이미지의 임베딩
- : 참조이미지에서 쿼리이미지로의 회전행렬
- : 참조이미지의 임베딩에서 회전 을 적용했을 때의 평균 임베딩
- : covariance, 회전 에서의 불확실성
여기서 는 회전 에서 객체가 보일 수 있는 모든 가능한 모습을 평균적으로 나타내는 임베딩으로, 객체의 다양한 3D 형태를 고려하여 임베딩이 계산됩니다.
- 는 객체의 3D 모델
그래서 평균임베딩이라는 것은 객체가 가질 수 있는 다양한 모습을 통합한 일반화된 표현이며, 저장된 임베딩은 객체의 구체적인 시각적 디테일보다는, 객체의 포즈와 형태를 구별하는 데 필요한 중요한 특징을 담고 있다고 할 수 있습니다.

2) Nearest neighbor search를 사용하여 쿼리 이미지의 임베딩과 가장 가까운 임베딩을 가진 reference point를 찾아서 query 이미지와 ref 이미지의 상대적 포즈 결정
- Nearest 상위 N개의 템플릿(3 또는 5개)를 사용하여 포즈 평가
→ 각 템플릿에서 얻은 포즈 결과들을 추가적으로 분석하여 오차가 가장 작은 포즈를 선택하는 방식으로 동작
Loss function
loss는 l2 norm으로 계산됩니다.
- F는 참조이미지의 임베딩()을 입력으로 받아 회전행렬을 적용한 후 결과를 예측하는 네트워크
- 는 truth embedding
Experiments
비교대상
- PIZZA: regression 기반 접근 방식으로, 상대적인 포즈를 직접 예측
- SSVE 및 ViewNet: 이 두 기법은 semi-supervised learning 및 self-supervised learning을 사용하여 view point 추정을 이미지 reconstruction 문제로 처리, 학습된 객체 카테고리만 사용할 수 있음
- 3DiM: 주로 view synthesis에 초점을 맞춘 기법으로, 3D 객체 포즈 추정을 위한 템플릿을 생성하고 가장 가까운 이웃 검색을 사용해 포즈를 추정
ShapeNet
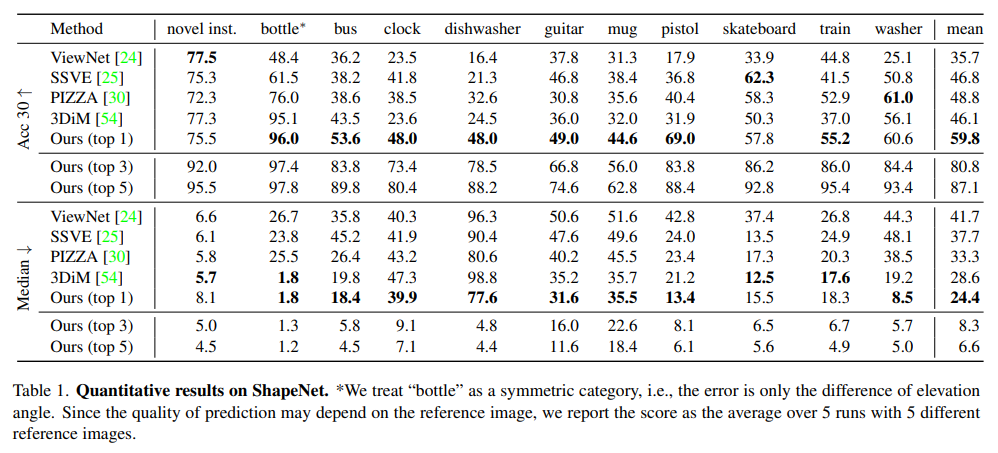
NOPE은 새로운 객체에서도 더나은 generalize 성능을 보여주었으며, 특히 회전 대칭성을 가진 객체에서도 탁월한 성능을 발휘했습니다.
기존의 방법들은 새로운 객체나 학습되지 않은 카테고리에서 성능이 저하되는 반면, NOPE은 학습되지 않은 객체 카테고리에서도 강력한 성능을 유지할 수 있음을 보입니다.
T-LESS
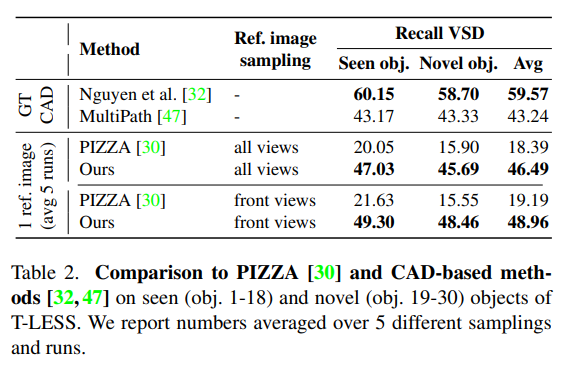
GT CAD 모델을 사용하는 모델 중 [32]의 성능에는 미치지 못했지만 [47]은 능가한 모습을 볼 수 있습니다.
Robustness to occlusions
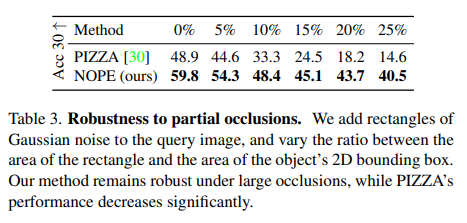
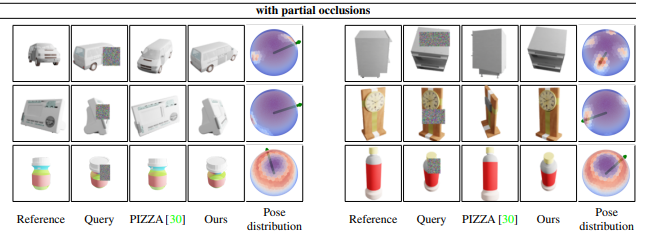
NOPE은 큰 가림이 있는 경우에도 여전히 robust한 성능을 보입니다.
Failure cases

- 모든 방법이 시계(clock), 식기세척기(dishwasher), 기타(guitar), 머그잔(mug) 카테고리에서는 정확한 결과를 내지 못했으며, 이는 높은 median의 오류로 확인되었다고 합니다.
- 기타를 제외한 이 카테고리들은 거의 대칭적이며, 작은 디테일만이 포즈의 모호성을 제거하기 때문에 pose estimation에 어려움을 겪었고, NOPE은 90도 또는 180도 대칭성을 가진 객체에서 상위 3개 또는 5개의 가장 가까운 이웃을 사용함으로써 중앙값 오류를 크게 개선했지만, 머그잔과 같이 원형 대칭을 가진 객체에서는 개선이 어려웠습니다.
- 또한 기타는 특정 시점에서 매우 얇게 보일 수 있기 때문에, 포즈 추정의 어려움이 있었습니다.
Summary
-
NOPE의 목표:
- NOPE은 단일 이미지만으로 새로운 객체의 상대적인 3D pose(rotation)를 예측하며, 3D 모델이나 추가적인 재학습 없이도 새로운 이미지에서 객체의 포즈를 estimation 가능
- 이 방법은 특히 새로운 객체에 대해 학습이 필요 없다는 점에서 기존 방법과 차별화
-
주요 기법:
- NOPE은 객체의 새로운 view(시점)를 예측하고 이를 template matching 방식으로 사용하여 새로운 이미지의 포즈를 예측
- 이러한 템플릿 매칭 방식은 occlusion이나 symmetry 문제에 대해서도 robust
-
방법론 차별점:
- 기존의 Novel View Synthesis(새로운 시점 생성) 방법들과 달리, NOPE은 색상 정보를 예측하는 것이 아닌, discriminative embeddings을 예측하여 더 빠르고 효율적으로 포즈를 추정
- 이를 통해 불필요한 세부 사항을 “발명(invent)”하지 않고도, 실제 객체의 외형에 가까운 임베딩을 생성가능 ⏩ 새로운 view 생성은 input 이미지에서 보이지 않는 부분을 만들어내야 하는데, 실제 이미지와 일치하지 않을 수 있기 때문에 이런 부분이 pose estimation에 부정적인 영향을 미칠 수 있음
- 대칭성 문제 처리:
- NOPE은 대칭적인 물체에서 발생할 수 있는 포즈의 모호성을 예측할 수 있으며, 이를 해결하기 위해 확률 분포를 사용한 템플릿 매칭 방식을 도입
- 이를 통해 여러 포즈 가능성을 분석하고, 그 중 최적의 포즈를 선택
NOPE은 학습 시에 템플릿(임베딩과 gt포즈)를 저장해서 이용하는 것이 아니라, 추론(inference) 시에 템플릿을 예측해서 생성하는 접근이 다른 템플릿 기반 모델들과 다른 방법이었습니다. 때문에 unseen 객체에 대해서도 estimation할 수 있고, 특정 카테고리나 인스턴스의 3D 모델 없이도 estimation할 수 있다는 장점을 가지고 있습니다.
