Multi-Modal
1.CLIP (Contrastive Language Image Pretraining)

CLIP은 OpenAI가 2021년 발표했으며, 이미지 인식 시 레이블이 알려지지 않은 데이터를 효과적으로 사전학습시키는데 사용된다. CLIP 방법론의 핵심은 Image Encoder와 Text Encoder를 Contrastive Learning 방법으로 학습한다는
2024년 1월 4일
2.[paper] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
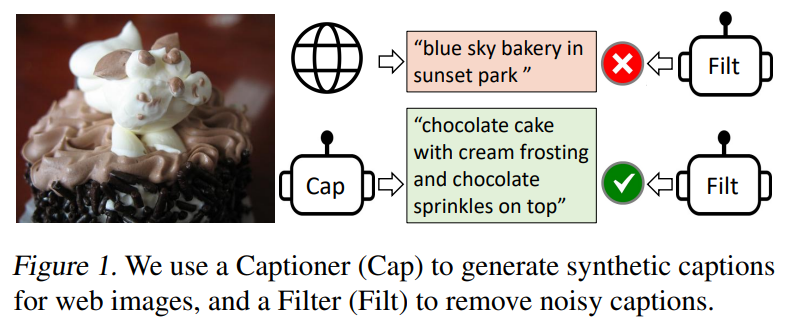
오늘 소개하는 BLIP(paper)는, 2022년 발표된 논문으로 vision-language understanding tasks와 generation-based tasks 모두 유연하게 사용할 수 있도록 아키텍처를 설계하였고, 합성된 캡션을 생성하고 기존
2024년 1월 30일