
CLIP은 OpenAI가 2021년 발표했으며, 이미지 인식 시 레이블이 알려지지 않은 데이터를 효과적으로 사전학습시키는데 사용된다.
CLIP 방법론의 핵심은 Image Encoder와 Text Encoder를 Contrastive Learning 방법으로 학습한다는 것이다. 여기서 주의할 점은 CLIP은 사전학습 모델이 아니고 사전학습 방식이라는 것이다.
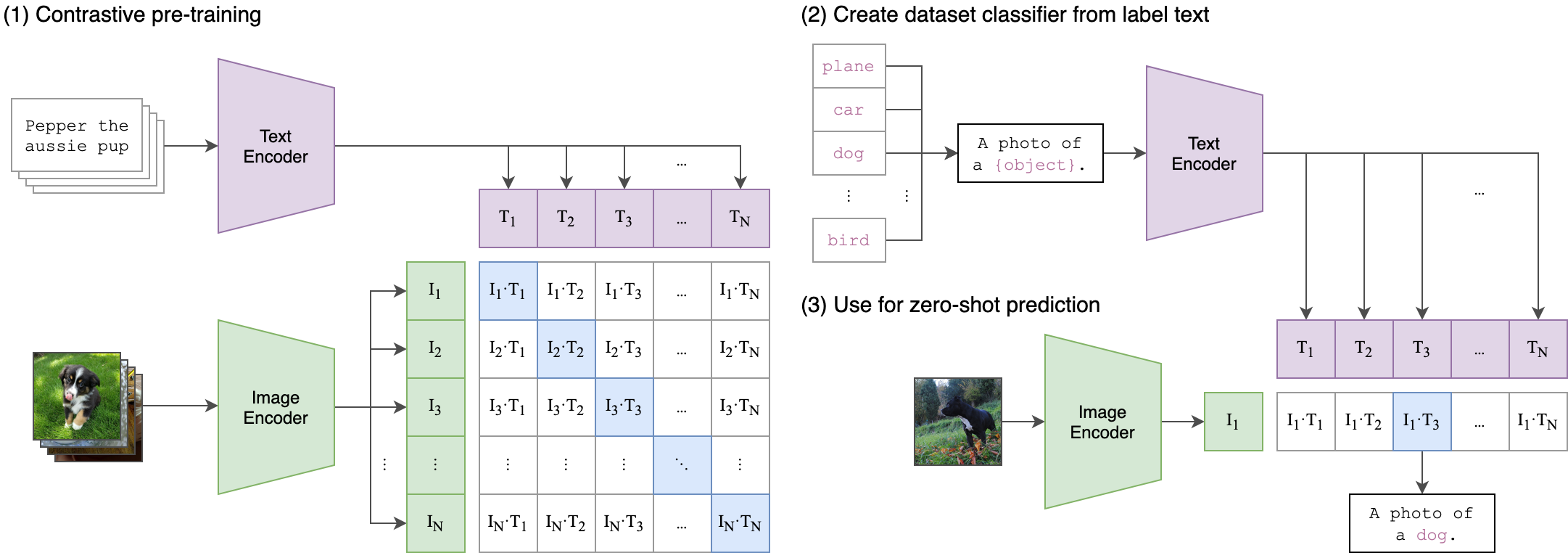
(1) Contrastive pre-training
이름에서 언급하고 있는 Contrastive Learning은 매칭되는 데이터 Feature들끼리는 가까워지도록, 나머지 Feature들 끼리는 멀어지도록 학습하는 방법이다. Encoder는 다양한 Vision Model들이 가능하고, CLIP 메커니즘을 통해 데이터를 벡터로 변환하고 코사인유사도 행렬을 계산한다. 이때 Encoder들은 본인 Image, Text Feature들끼리는 가까워지도록, 나머지 Feature들끼리는 멀어지도록 가중치를 업데이트한다.
(2) Create dataset classifier from label text
그런 다음 text에 대한 encoder를 거쳐 여러 label에 대한 text embedding을 각각 만들어낸다.
(3) Use for zero-shot prediction
CLIP의 가장 재미있는점 중 하나는 바로 Zero Shot Prediction이 가능하다는 것이다. Zero Shot Prediction은 한번도 학습하지 않은 문제를 맞추는 것으로, CLIP에서는 input으로 넣은 이미지를 embedding으로 만들어준 후, text embeddings과의 유사도 비교를 통해서 가장 유사도가 높은 항목을 text label로 선정한다. 이 경우, 학습에 이용되지 않는 image가 들어와도, label prediction이 이루어질 수 있기 때문에 zero-shot learning이 가능하다
특히 잘 알려지지 않은 데이터셋의 경우에서 ViT(CLIP ViT-L) 사전학습 모델의 zero shot transfer-learning 정확도는 ImageNet ResNet101에서의 결과보다 높았다고 한다.
Reference
CLIP paper
https://ffighting.net/deep-learning-paper-review/multimodal-model/clip/
https://kyujinpy.tistory.com/47
101가지 문제로 배우는 딥러닝 허깅페이스 트랜스포머 with 파이토치, 조슈아 K. 케이지 저자(글)
