[paper] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Multi-Modal
"BLIP"
오늘 소개하는 BLIP(paper)는, 2022년 발표된 논문으로 vision-language understanding tasks와 generation-based tasks 모두 유연하게 사용할 수 있도록 아키텍처를 설계하였고, 합성된 캡션을 생성하고 기존 text중에서는 noise가 있는 caption을 제거하는 방식을 통해 웹에서 수집한 데이터의 noise를 효과적으로 활용할 수 있도록 했다고 한다.
작성시점 기준 후속연구인 BLIP2가 nocaps dataset에서 SOTA를 달성하고 있다.
Introduction
기존 Vision-Language Pre-training (VLP)의 한계
Vision-Language Pre-training (VLP) 기술이 시각과 언어를 결합한 tasks에서 좋은 성과를 보이고 있으나 아래와 같은 한계가 존재한다.
-
모델 관점에서의 한계
- 대부분의 방법이 encoder 기반 모델이나 encoder-decoder 모델 중 하나를 채택하고 있음
👉 그러나 encoder 기반 모델은 text generation task(ex. image caption generation)에는 적합하지 않고, encoder-decoder 모델은 text 생성에만 집중하다보니 image-text 상호 modality간의 understanding이 필요한 task의 성능이 그리 좋지 않았음
- 대부분의 방법이 encoder 기반 모델이나 encoder-decoder 모델 중 하나를 채택하고 있음
-
데이터 관점에서의 한계
- 대부분의 최신 방법은 주로 웹에서 수집하여 noise가 있는 image-text 데이터셋의 확장을 통해 성능을 향상시키고자 함
👉 데이터셋을 확장하여 성능향상을 이룰 순 있지만 논문에서는 web text의 noise가 vision-language 학습에는 부적절하다고 한다.
- 대부분의 최신 방법은 주로 웹에서 수집하여 noise가 있는 image-text 데이터셋의 확장을 통해 성능을 향상시키고자 함
BLIP에서는 이러한 한계를 극복하기 위한 아키텍처를 제안하였다.
BLIP 프레임워크의 두 가지 Contribution
-
모델 관점
Multimodal mixture of Encoder-Decoder (MED)
: 효과적인 multimodal pre-training과 유연한 transfer learning을 위한 새로운 모델 구조로, 아래 세가지 기능으로 동작할 수 있어 위와 같은 이름이 붙여졌다.
- unimodal encoder
- image-text encoder
- image-text decoder위에서 살펴봤던 한계처럼 encoder, decoder에 적합한 task가 나뉘면서 서로다른 modality 간의 상호작용을 고려하기 어려웠던 문제점을 다양한 작동 모드에서 동작할 수 있는 MED 블록으로 학습시키면서 vision과 language에 대한 이해를 꾀한다.
-
데이터 관점
Captioning and Filtering (CapFilt)
: noise가 있는 image-text pairs에서 학습하기 위한 새로운 데이터 bootstrapping 방법-
pre-trained된 MED를 captioner 및 노이즈 제거 필터 두 모듈로 세밀 조정
-
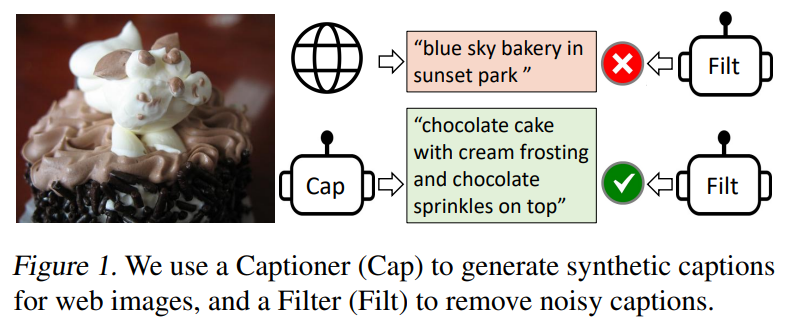
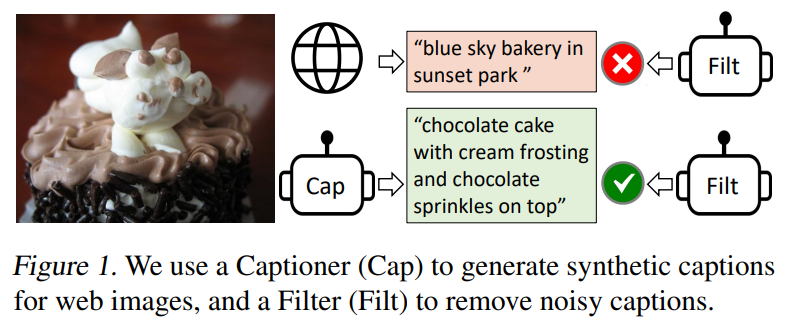
이미지에서 합성된 캡션을 생성하는 captioner와, 원본 web text 및 합성된 text에서 noise가 많은 caption을 제거하는 filter가 함께 작동하여 다양한 downstream tasks에서 상당한 성능 향상을 달성
example) 아래 그림처럼 케이크 사진에 잘못된 caption을 filter를 통해 제거!
-
Method
Model Architecture
image encoder로는 Vision transformer를 사용하였고, 위에서 설명한 MED가 unimodal encoder, image-text encoder, image-text decoder로 작동한다.
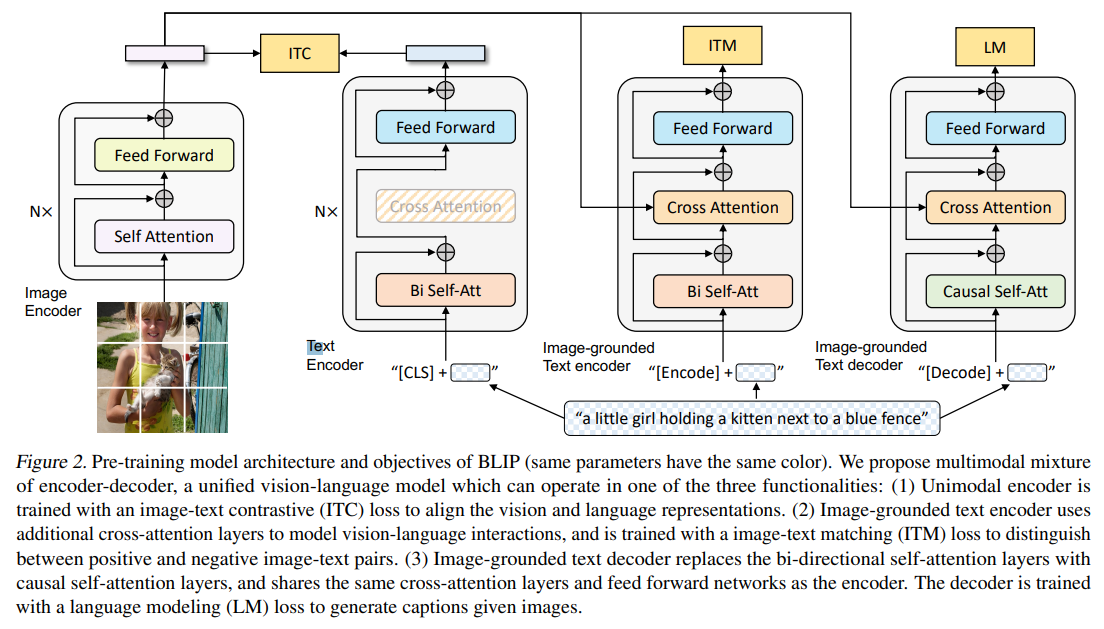
때문에 모델은 image-text contrastive learning, image-text matching, imageconditioned language modeling의 세 가지 vision-language 목적으로 동시에 pretrained 된다. 이를 위한 loss는 아래 내용으로 이어진다.
Pre-training Objectives
pre-training 동안 두 개의 understanding-based objective와 한 개의 generation-based objective, 이렇게 세 개의 목적을 달성하기 위해 아래의 loss function을 가진다.
1. Image-Text Contrastive Loss (ITC)
: vision transformer와 text transformer 사이에서 negative pairs와 대조적으로 positive image-text pairs끼리 유사한 표현을 갖도록 하는 loss
2. Image-Text Matching Loss (ITM)
: image-based text encoder에서 작용하는 loss
vision과 language 간의 미세한 alignment를 캡처하는 representation을 학습하도록 하는 objective function이다.
3. Language Modeling Loss (LM)
: image-based text decoder에서 작용하는 loss
decoder에서 텍스트 설명을 생성할 때 텍스트의 가능성을 최대화하도록 모델을 training한다, cross entropy loss가 쓰인다.
multi-task learning을 활용하여 효율적인 pre-training을 수행하기 위해 text encoder와 text decoder는 SA(Self-Attention) 레이어를 제외한 모든 파라미터를 공유한다.
👉 SA 레이어를 제외한 이유는 인코딩 및 디코딩 작업 간의 차이가 SA 레이어에 가장 잘 나타나기 때문 (각각의 작업에서 공통된 특징을 학습하면서도, 인코딩 및 디코딩 작업 간의 차이를 반영하기 위함)
CapFilt
최근에는 인간이 수동으로 캡션을 생성하는 고품질 데이터셋을 이용하기보다 웹에서 수집되는 대규모 데이터셋을 사용하는 추세이다.
그러나 웹에서 수집된 대체 텍스트는 vision-language alignment를 학습하기에는 부적절한(이미지의 시각적 내용을 정확하게 설명하지않는) noise가 많이 포함되어 있다.
논문에서는 이러한 text corpus의 품질을 향상시키기 위해 CapFilt(Captioning and Filtering)라는 새로운 방법을 도입한다.
아래와 같이 두가지 기능으로 구성된다.
- captioner : image-based text decoder로서 이미지에 대한 캡션 생성
- filter : image-based text encoder로서 ITC 및 ITM objectives를 사용하여 생성된 텍스트로부터 텍스트가 이미지와 일치하는지 확인하고 노이즈가 있는 이미지-텍스트 쌍을 제거
👉 마지막으로 이렇게 필터링된 이미지-텍스트 쌍을 사람이 주석을 매긴 쌍과 결합하여 새로운 데이터셋을 형성하게 된다.
Experiments
CapFilt의 효과
아래 표를 보면 captioner(C)와 filter(F) 둘다 사용했을 때 효과가 상호 보완되어 원본 웹 텍스트를 사용하는 것보다 성능이 향상되는 것을 볼 수 있다.
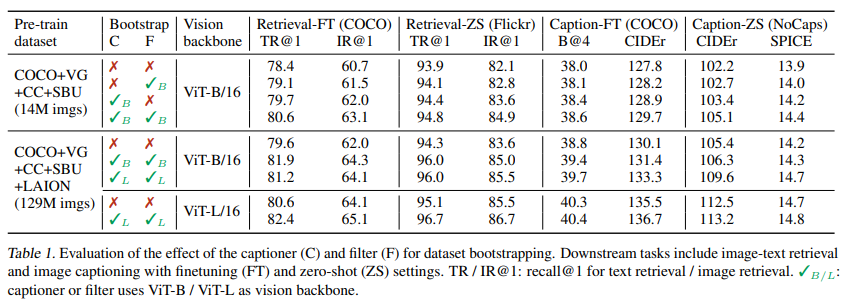
parameter sharing 전략
Self attention layer를 제외하고 파라미터를 공유했을 때 가장 높은 성능을 보임을 알 수 있다.
SA 레이어를 공유하면 인코딩 작업과 디코딩 작업 간의 충돌로 인해 모델 성능이 저하된다.
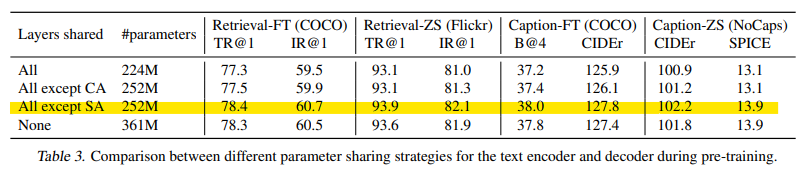
Image-Text Retrieval
14M pretrained 이미지에서 BLIP은 COCO의 평균 R@1에서 이전 SOTA모델 ALBEF보다 +2.7% 더 높은 성능을 달성했다.
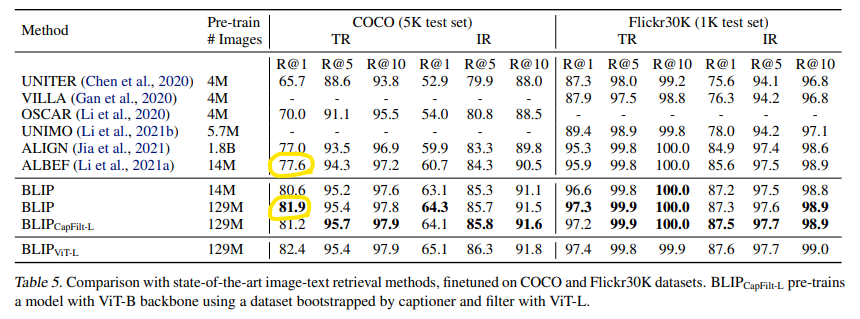
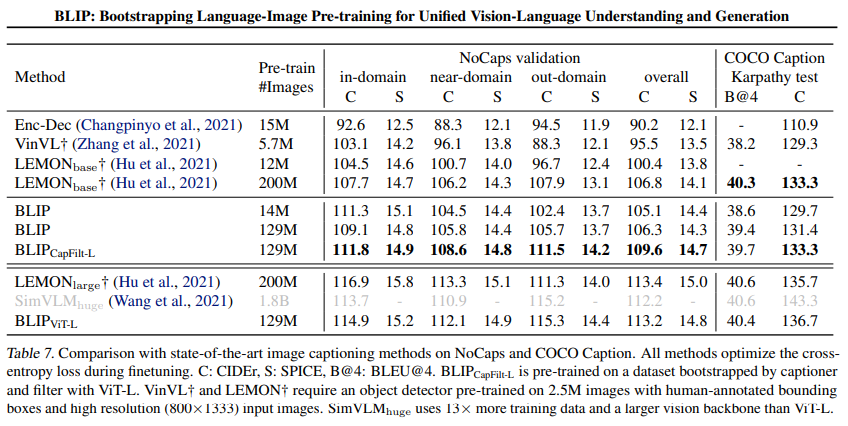
Image Captioning
129M 이미지의 BLIP은 200M 이미지의 LEMON과 같은 성능을 발휘하는데, LEMON에는 계산량이 많은 pretrained object detector와 더 높은 resolution(800×1333) 입력 이미지가 필요하므로 BLIP보다 추론 시간이 상당히 느리다.
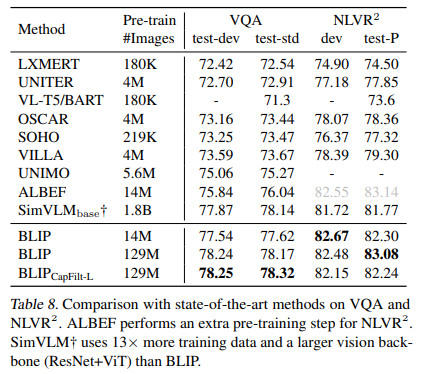
Visual Question Answering (VQA)
주어진 이미지와 질문에 대한 답변을 예측해야 하는 task에서도 14M 이미지셋에서BLIP이 테스트 세트에서 ALBEF보다 +1.64% 더 나은 성능을 보인다.
129M 이미지셋으로 pretrained된 BLIP은 13배 더 많은 사전 훈련 데이터(1.8B)와 더 큰 비전 백본을 사용하는 SimVLM보다도 더 나은 성능을 달성하는 것을 볼 수 있다.
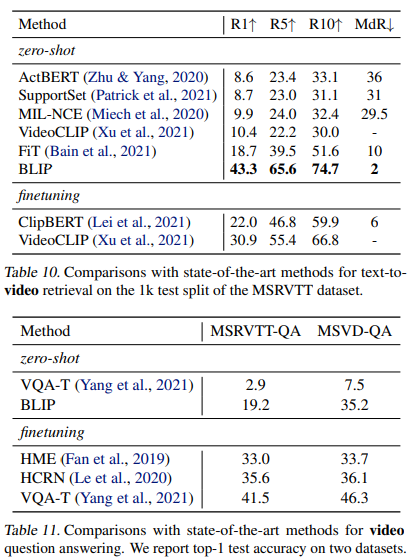
Zero-shot Transfer to Video-Language Tasks
BLIP 모델은 텍스트-비디오 검색과 비디오 질문 답변의 video-language task에 대해서도 일반화 성능을 보여줬다.

감사합니다ㅎ! 어떻게 이렇게 잘 정리하세요?? 완전 도움이 됐어요!