Q. What is Kmeans?
A. a unsupervised machine learning algorithm used for clustering similar data points together.
- It groups data points into a fixed number of clusters based on their similarity.
- The algorithm tries to minimize the distance between each data point and the centroid (center) of its assigned cluster.
- It is an iterative algorithm that updates the centroid and cluster assignments until convergence.
- Kmeans is sensitive to the initial placement of centroids, so it is often run multiple times with different initializations.
- It can be used for a variety of applications, including customer segmentation, image compression, and anomaly detection.
Q. How do you determine the optimal number of clusters in Kmeans?
A.
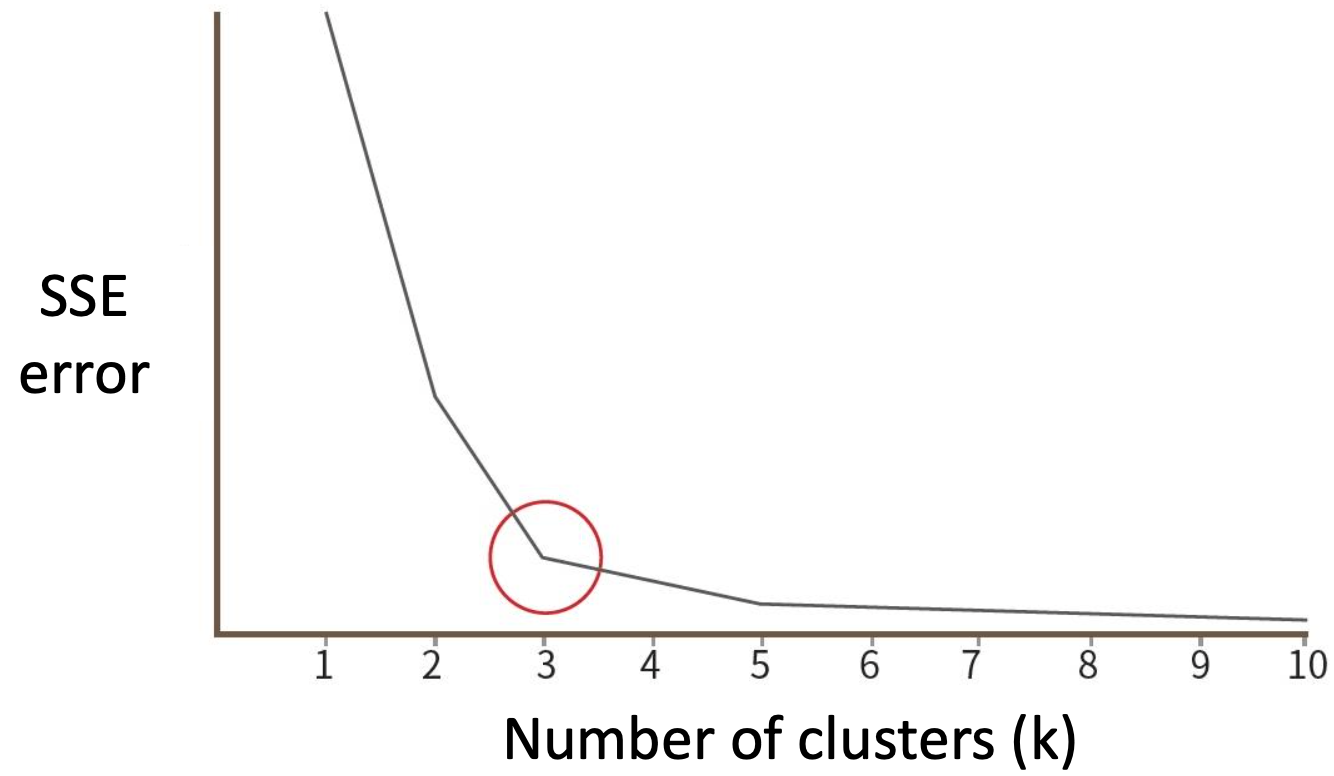
- Elbow method: Plot the sum of squared distances of data points to their assigned cluster centroids against the number of clusters, and look for an "elbow" point where the reduction in distortion begins to level off.
-: Calculate the silhouette coefficient for each data point, which measures how similar it is to its own cluster compared t
o other clusters. Choose the number of clusters that maximizes the average silhouette coefficient.
Kmeans는 비지도학습(unsupervised learning)의 한 종류로
Label이 없는 데이터셋을 K개의 군집으로 나누는(Clustering) 것이다.
이 때 각 군집의 Centroid를 개별 데이터와의 거리의 평균(Means)으로 구한다.
동작 순서
1. N개의 데이터셋 에서 K개의 데이터를 무작위로 뽑고 이를 각 cluster의 centroid로 Initailize.
2. 개별 데이터와 각 Centroid의 거리를 계산하고 가장 가까운 Centroid의 cluster로 분류한다.
3. 각 Cluster 별로 Centroid를 다시 계산해 새로운 Centroid를 지정한다.
4. 이 과정을 Cluster가 수렴할 때까지 반복한다.
질문 1. Kmeans의 장단점은 무엇일까?
장점
1. 간단하고 이해하기 쉽다.
2. 수렴을 보장한다.
3. Large Dataset을 다룰 때 유용하다.
단점
1. Initial Value에 민감하다.
-> 시작 위치에 따라 매번 Cluster가 바뀐다.
2. Outlier에 민감하다.
-> L2 거리를 사용하면 불가피한 것 같다.

막상 하면 모르니까 일단 하자.