AI
1.파이토치 딥러닝 마스터 - Tensor

딥러닝은 데이터를 하나의 형태에서 다른 형태로 변환하는 시스템을 구축하는 과정을 포함한다.\-> 입력을 부동소수점 수로 변환하는 것부터 시작심층 신경망Deep Neural Network 는 여러 단계 거쳐 데이터 변환 학습,그래서 각 단계 사이의 일부 변환된 데이터들
2.파이토치 딥러닝 마스터 - 학습기법

앞으로 다루는 모델은 특정한 범위에 한정된 작업을 수행하기 위해 만들어진 모델이 아니라,입출력 쌍을 활용한 다양한 유사 작업에 대해 스스로를 최적화하기 위해 자동으로 적응하는 모델.즉 특정 작업에 대한 데이토러 학습한 일반화된 모델이다.이 포스팅은 일반 함수의 적합fi
3.파이토치 딥러닝 마스터 - 신경망 활용한 데이터 적합

뉴런은 입력에 대한 선형 변환과 활성 함수activation function라 부르는 고정된 비선형 함수를 적용하는 역할을 한다.여러 차원으로 가중치와 편향값을 가진 여러 개의 뉴런을 나타내므로 이 표현식은 뉴런 계층layer이라 한다.이전의 선형 모델과 앞으로 사용할
4.파이토치 딥러닝 마스터 - 이미지 학습

순방향 신경망 만들기 Dataset, DataLoader 사용한 데이터 로딩 분류 손실 CIFAR-10 > - 32 x 32, RGV, 6만 개, 1부터 10까지 Label 인자 : 데이터 받을 위치, 훈련셋인지 검증셋인지 지정, 데이터 찾지 못할 경우 데이터 내려
5.나만봄 - 경사하강법
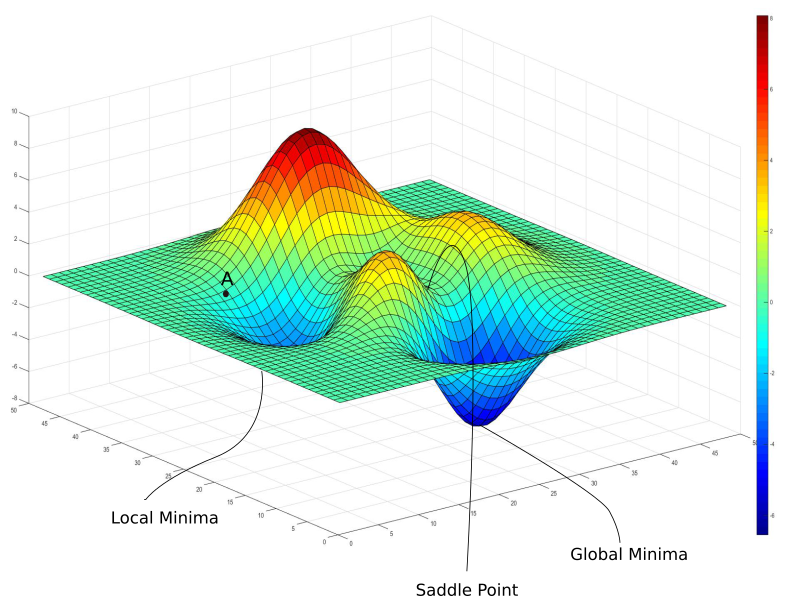
경사하강법. 머신러닝, 딥러닝을 공부하기 시작하면 자주 마주하게 되는 단어다. 글로 정리하기 전 chatgpt에게 물어봤다. > 우리말로 요약하자면 경사하강법이란, loss function을 최적화하기 위한 알고리즘. 손실 함수 기울기 계산 후steepest de
6.나만봄 - 선형 회귀 (Linear Regression)

대표를 뽑는 것은 중요하다.모두의 의견을 일일이 다 반영할 수 없기 때문이다.이번 포스팅의 주제인 선형 회귀가 하는 역할이다.이번에도 chatgpt에게 먼저 물어봤다.요약하자면,종속 변수(Dependent variable)와 독립 변수(Independent variab
7.나만봄 - MLP(Multi-Layer Perceptron)

이번 포스팅은 조금 길어질 것 같다.MLP를 설명하며 중간중간에 추가적으로 다른 개념에 대해 설명할 예정이기 때문이다.이번에도 본격적으로 시작하기 전 ChatGPT에게 질문했다.Multi-Layer Perceptron.말 그대로 여러 층이 있는 퍼셉트론이다.하나하나 개
8.나만봄 - 역전파가 뭐야

이전 포스팅이 너무 길어질 것 같아서나눠서 포스팅을 한다.chatGPT의 답변이번에도 말이 많아 요약하면,in order to minimize the difference between the predicted output and the actual output.the
9.나만봄 - CNN이 뭐야
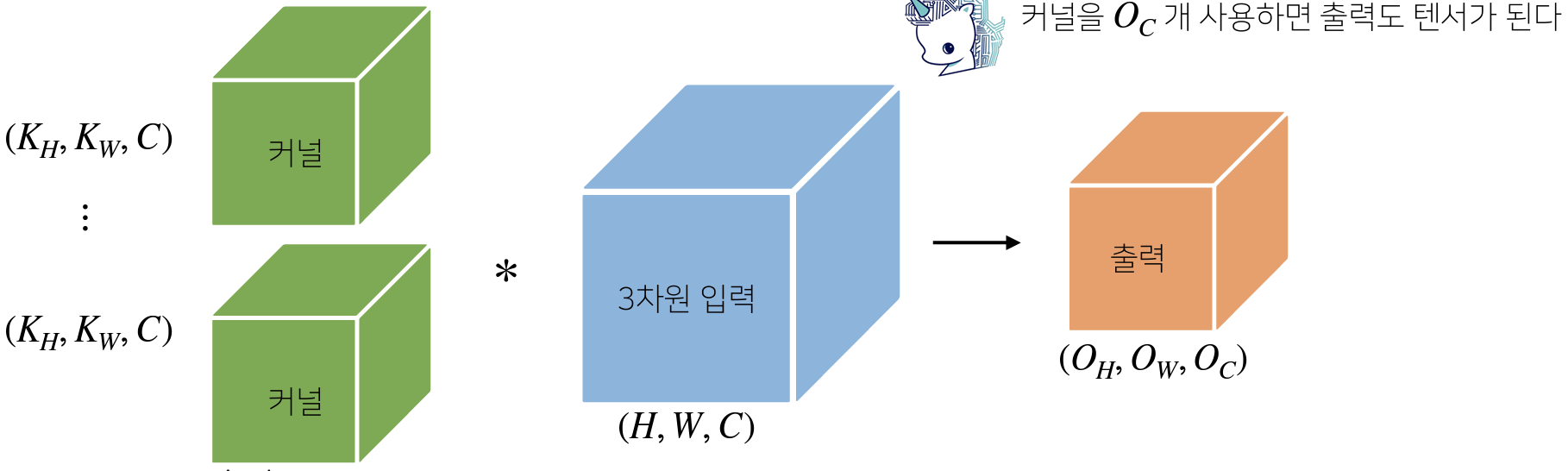
오늘도 ChatGPT에게 먼저 질문했다.이제는 답변을 정리해서 쓰기로 했다.좋은 답을 내놓긴 하지만 장황하게 대답하는 경우가 많아서.use of convolutional layers, which perform a series of convolutions on the i
10.나만봄 - SGD (Stochastic Gradient Descent)
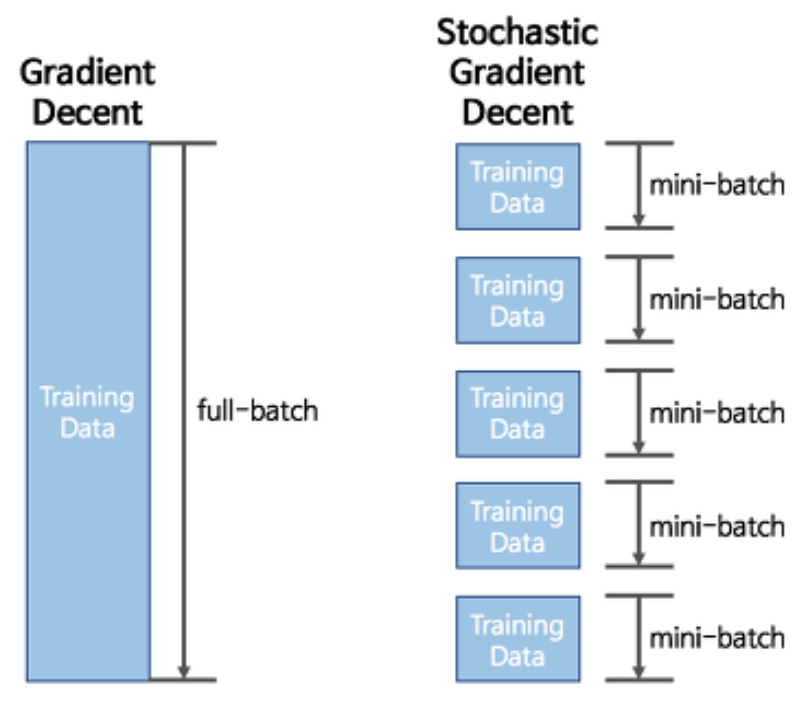
3월 15일 기준으로 GPT-4가 공개됐다. 발표에 따르면 GPT-3보디 압도적으로 향상된 성능을 보이는 것 같다. 따라가기 벅찰 정도로 빠르지만 하긴 해야 하잖아. 그래서 또 chatgpt와 먼저 대담을 나눈다. > What is Stochastic Gradient
11.나만봄 - KNN이 뭐야
3월 초에 나온 뉴스이지만,Meta에서 GPT3 보다 성능이 좋다고 알려진 LLAMA를 발표했다.Dalai(https://cocktailpeanut.github.io/dalai/AI 발전 속도가 무시무시한데,그만큼 우위를 차자하기 위한 싸움 구경도 재밌다.Q.
12.나만봄 - Kmeans가 뭐야
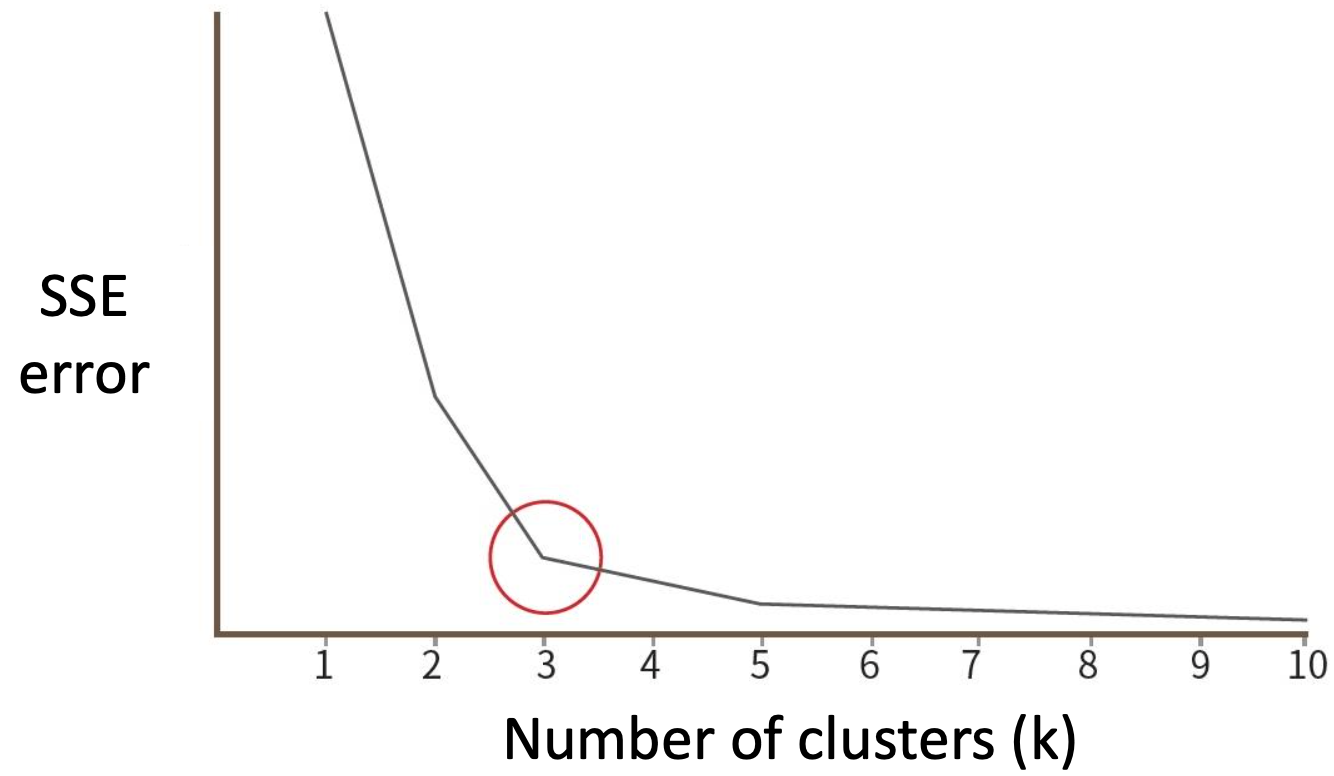
Q. What is Kmeans?A. a unsupervised machine learning algorithm used for clustering similar data points together.It groups data points into a fixed num
13.🎤 [삼시세질문] AI - 1
미니배치 단위로 입력을 정규분포(평균 = 0, 분산 = 1)를 따르도록 정규화한다.스케일(scale)과 시프트(shift) 변환 가능하다.효과 1 : 기울기 소실/폭발 문제가 해결되어 큰 학습률을 설정해 학습속도를 증가시킬 수 있다.효과 2 : 일반화(Regulazat
14.🎤 [삼시세질문] AI - 2
Convolution Layer는 이미지의 작은 지역에 대해서만 뉴런이 연결되며 이 과정에서 필터(커널)를 사용한다. 이는 공간 정보를 직접적으로 유지하면서 영역의 중요한 패턴을 처리할 수 있도록 해준다. 반면에 FC Layer는 모든 뉴런이 서로 연결되며 이미지를 일
15.🎤 [삼시세질문] AI - 3
Q.
16.🔥 논문리뷰 - Attention Is All You Need

이전 시퀀스 변환 모델은 RNN이나 인코더-디코더 포함한 CNN 기반한계 많아 ex) 병렬화 X, Sequence 길어지면 처리 힘들어본 논문은 오로지 Attention 기반병렬화 및 일반화 성능 뛰어남(Abstract에 나온 내용 보충 설명)기존 RNN, LSTM,
17.🔥 논문리뷰 - LoRA: Low-Rank Adaptation of Large Language Models

Simple Summary LLM을 적은 시간, 비용으로 finetune시키기 위해 등장한 방법 기존의 pre-trained weights를 freeze시키고 dense layer의weight를 Low-rank 로 decomposition한 Matrices만을 학습한다
18.🕵️♂️ Survey - Low Rank Compression

A Survey on Model Compression and Acceleration for Pretrained...Low rank FactorizationDecomposing Linear Layers대표적으로 SVD2021년 이후 논문Compressing Pre- tr
19.🔥 논문 리뷰 - VGG ( VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION)

깊이 증가시키며(16-19 Layers) 성능 향상모든 Conv LAYER에서 3x3 filter 사용 → 파라미터수 줄여 연산량 감소Depth로 Accuracy를 향상시키는 방법최소 크기의 Filter(3x3)을 사용하면서 Depth를 증가시켜 성능 향상이 때 De
20.🔥 논문 리뷰 - word2vec (Efficient Estimation of Word Representations in Vector Space)
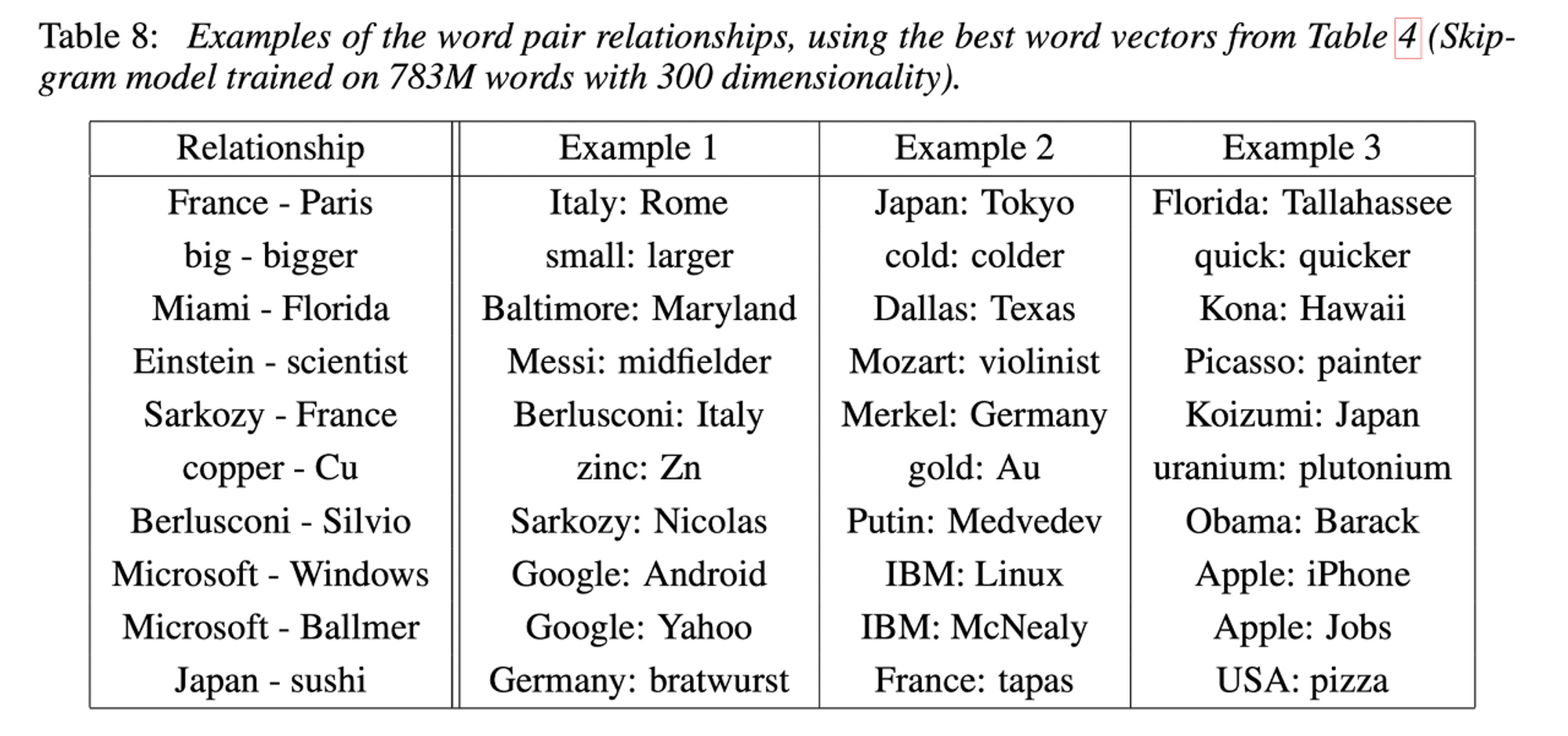
computing continuous vector representations of words from very large data sets 하는 두 가지 모델 구조 제시CBOW & SKIP-GRAMword similarity task에서 성능 측정better accu
21.🔥 논문 리뷰 - seq2seq
LM문장에 확률 부여하는 모델→ 특정 상황에서 적절한 문장 단어 예측 가능.하나의 문장은 여러개의 단어로 구성joint probability고정된 크기의 Context Vector 사용Context Vecotr로부터 디코더가 번역 결과 추론긴 문장 처리 용이인코더 마지
22.🔥 논문 리뷰 - EfficientNet
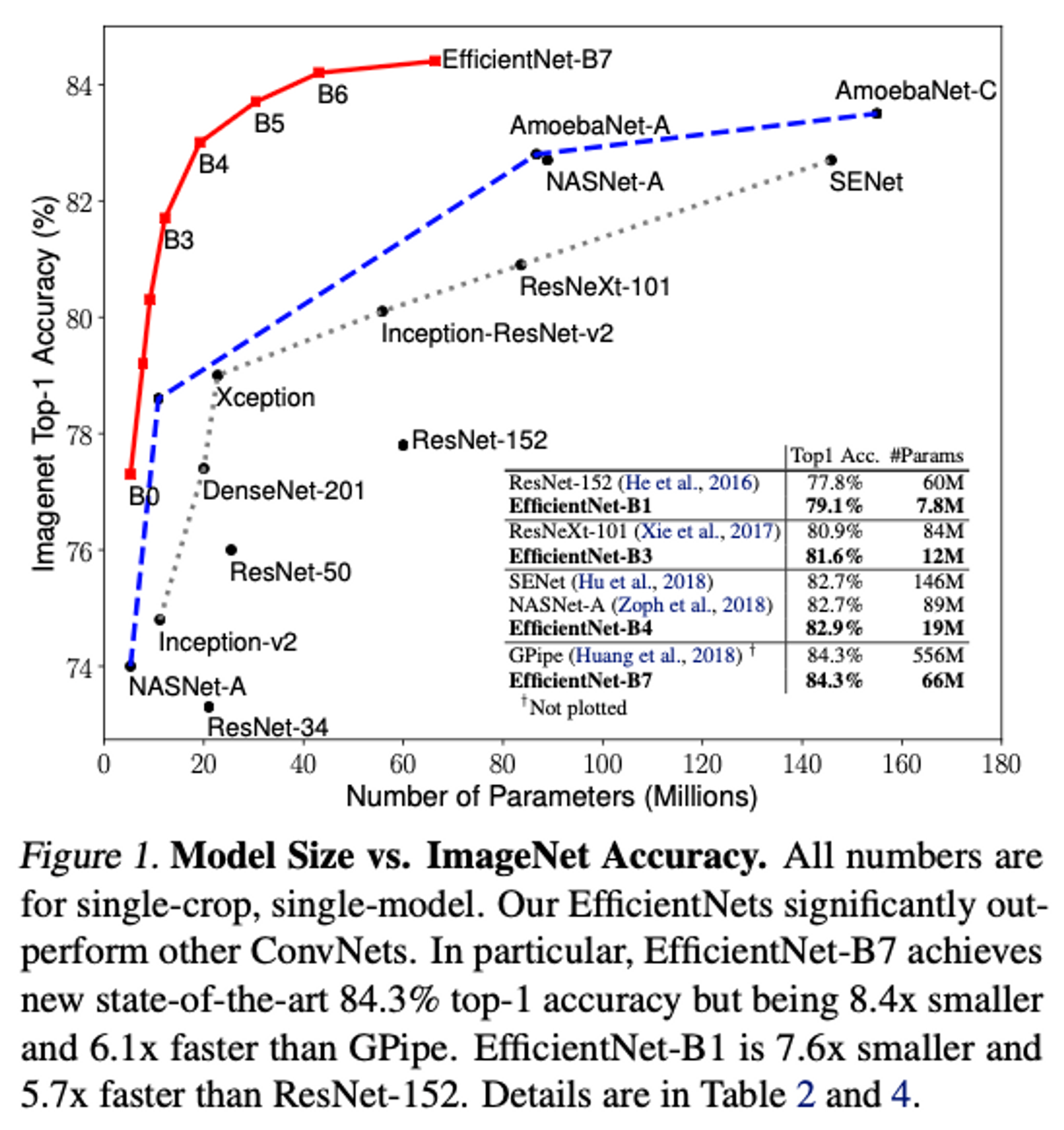
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networksefficientnet.pdf모델의 성능과 효율성을 균형있게 조정하기 위해 네트워크의 규모(scale)를 조절하는 방법을 제시→ Compou