
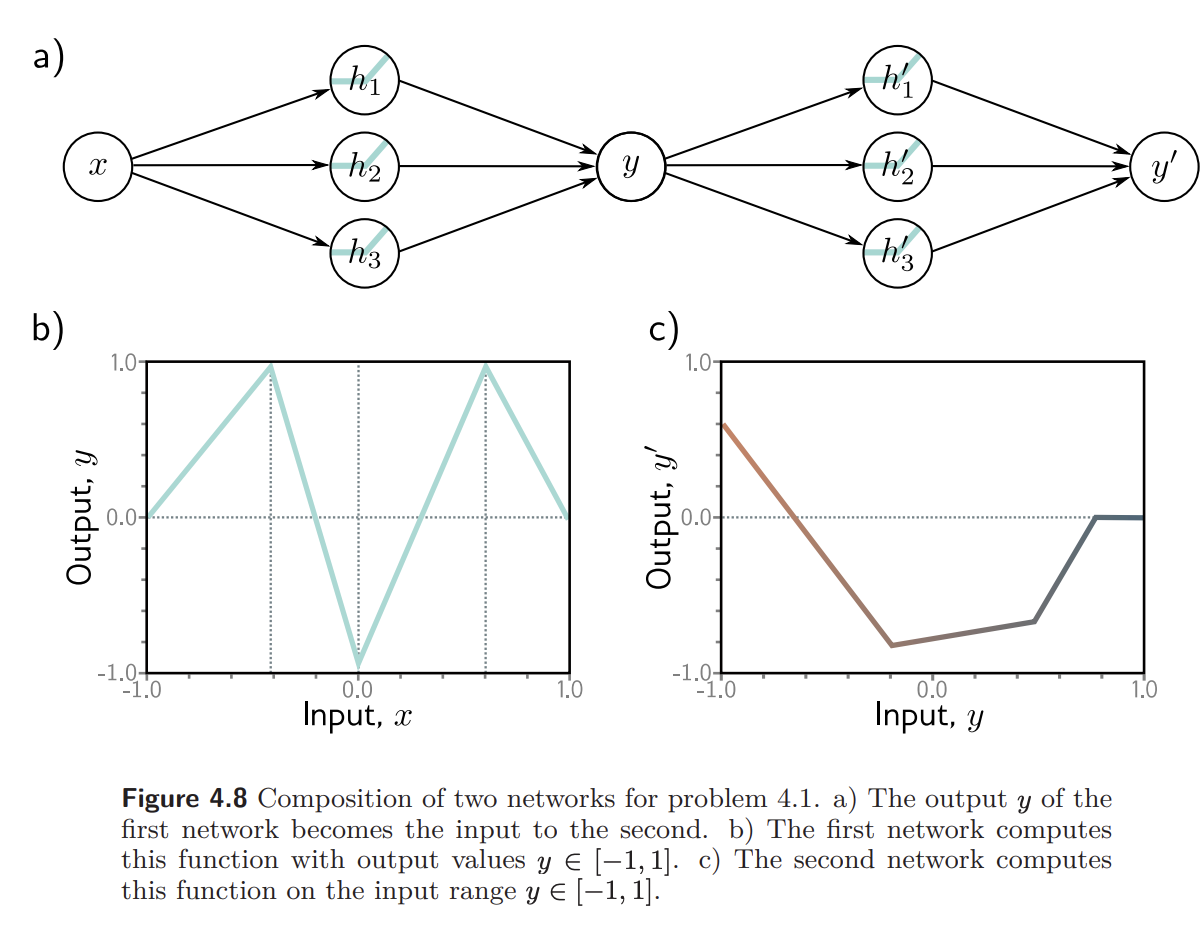
Problem 4.1 Consider composing the two neural networks in figure 4.8. Draw a plot of the relationship between the input and output for
figure 4.8:
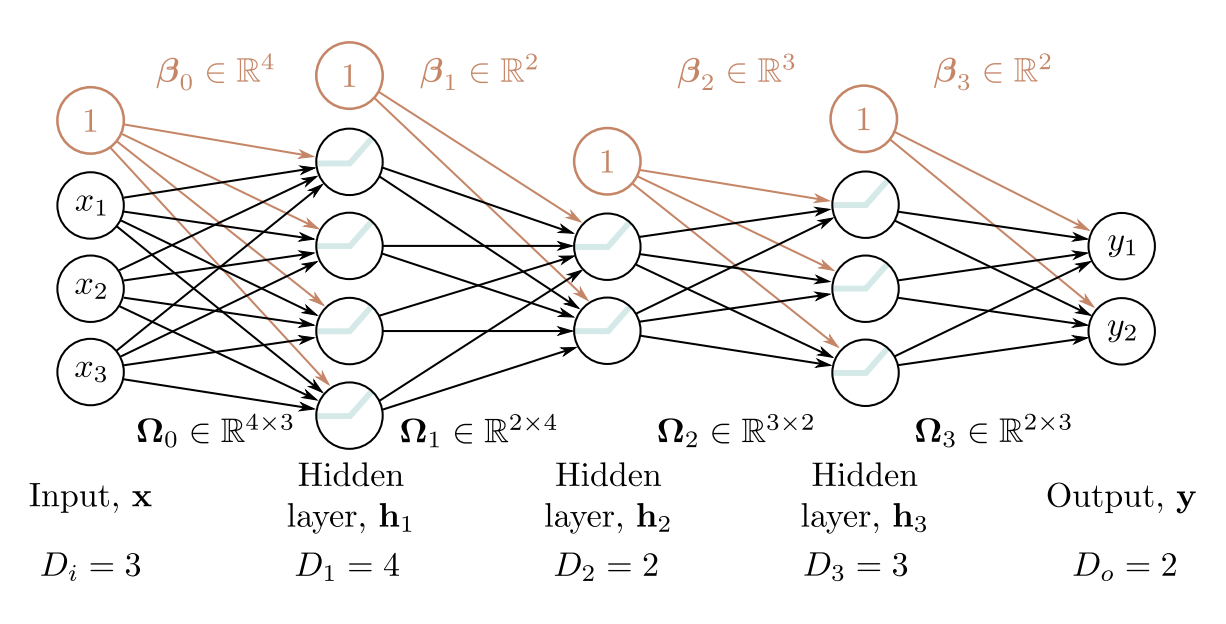
Problem 4.2 Identify the four hyperparameters in figure 4.6.
figure 4.6 :
Problem 4.3 Using the non-negative homogeneity property of the ReLU function (see problem 3.5), show that:
where and are non-negative scalars. From this, we see that the weight matrices can be rescaled by any magnitude as long as the biases are also adjusted, and the scale factors can be re-applied at the end of the network.
where .
이 문제의 핵심은 ReLU의 non-negative homogeneity 성질이다.
즉, ReLU 내부에 있는 음이 아닌 스칼라 배수를 바깥으로 꺼낼 수 있다.
먼저 내부 ReLU를 보면,
이므로 ReLU의 성질을 적용하면,
이다.
이를 원래 식에 대입하면,
즉,
이 된다.
이제 바깥쪽 전체에서 을 묶으면,
따라서 다시 ReLU의 성질을 적용하면,
를 얻는다.
이 식이 의미하는 바는 다음과 같다.
- weight matrix에 곱해진 양수 스케일 은
- bias를 적절히 나누어 조정하면
- 네트워크 마지막의 전체 스케일 로 옮겨서 표현할 수 있다.
즉, ReLU 네트워크에서는 가중치의 크기를 내부적으로 재조정(rescaling) 해도,
적절히 bias를 함께 바꾸면 같은 형태의 함수를 나타낼 수 있다.
ReLU의 non-negative homogeneity 성질을 두 번 적용하면, 네트워크 내부의 양수 스케일을 바깥으로 이동시킬 수 있다.
따라서 ReLU 네트워크는 weight의 스케일을 자유롭게 재배치할 수 있는 표현상의 유연성을 가진다.
Problem 4.4 Write out the equations for a deep neural network that takes inputs = 4 outputs and has three hidden layers of sizes , , and , respectively, in both the forms of equations 4.15 and 4.16. What are the sizes of each weight matrix Ω. and bias vector ?
equation 4.15 :
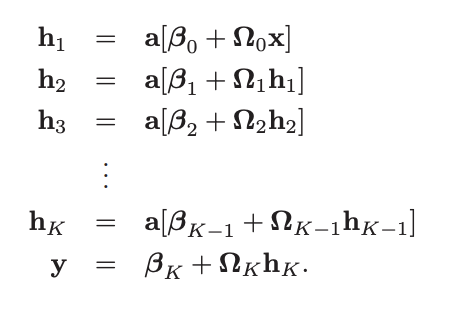
equation 4.16 :
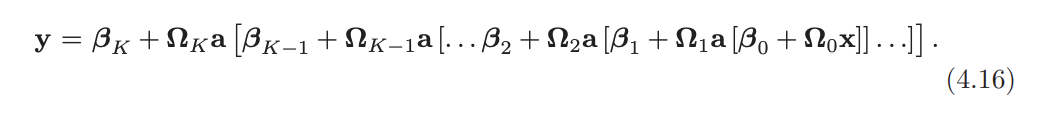
입력 차원이 , 출력 차원이 인 deep neural network를 생각하자.
이 네트워크는 3개의 hidden layer를 가지며, 각 hidden layer의 크기는 각각
이다.
즉,
- 입력층: 5차원
- 첫 번째 은닉층: 20개 유닛
- 두 번째 은닉층: 10개 유닛
- 세 번째 은닉층: 7개 유닛
- 출력층: 4차원
으로 이루어진 신경망이다.
1. Equation 4.15 형태
은닉층이 3개이므로 이고, 각 층의 식은 다음과 같이 쓸 수 있다.
2. Equation 4.16 형태
위 식을 한 줄의 중첩된 형태로 쓰면 다음과 같다.
3. Weight matrix와 bias vector의 크기
입력 벡터 의 크기는
이다.
각 층의 차원을 따라가면 weight matrix와 bias vector의 크기는 다음과 같다.
(1) 입력층 첫 번째 은닉층
입력은 5차원이고, 첫 번째 은닉층은 20차원이므로
(2) 첫 번째 은닉층 두 번째 은닉층
첫 번째 은닉층은 20차원, 두 번째 은닉층은 10차원이므로
(3) 두 번째 은닉층 세 번째 은닉층
두 번째 은닉층은 10차원, 세 번째 은닉층은 7차원이므로
(4) 세 번째 은닉층 출력층
세 번째 은닉층은 7차원, 출력층은 4차원이므로
4. 최종 정리
따라서 각 weight matrix와 bias vector의 크기는 다음과 같다.
Problem 4.5 Consider a deep Neural Network with input, output, and layers, with hidden units in each. Would the number of weights increase more if we increased the depth by one or the width by one? Provide your reasoning.
이 문제는 깊이를 1 늘릴 때와 너비를 1 늘릴 때 중 어느 쪽이 weight 수를 더 많이 증가시키는지 비교하는 문제이다.
현재 네트워크 구조는 다음과 같다.
- 입력: 1차원
- 출력: 1차원
- hidden layer: 10개
- 각 hidden layer의 hidden unit: 10개
1. 현재 weight 수
입력층에서 첫 번째 hidden layer로 가는 weight 수는
hidden layer가 10개이므로, hidden layer 사이의 연결은 총 9번 있고,
각 연결마다 weight 수는
이므로 전체 hidden-hidden weight 수는
마지막 hidden layer에서 output으로 가는 weight 수는
따라서 전체 weight 수는
2. depth를 1 증가시키는 경우
depth를 1 늘린다는 것은 hidden layer를 1개 더 추가하는 것이다.
새 hidden layer도 unit이 10개이므로 추가되는 연결은 hidden layer 사이 연결 1개이고,
추가되는 weight 수는
이다.
즉, depth를 1 늘리면 weight는 100개 증가한다.
3. width를 1 증가시키는 경우
width를 1 늘린다는 것은 각 hidden layer의 unit 수가
로 바뀌는 것이다.
그러면 새로운 weight 수는
-
입력층 첫 hidden layer:
-
hidden layer 사이:
-
마지막 hidden layer output:
따라서 전체 weight 수는
증가량은
이다.
4. 결론
depth를 1 증가시키면 weight는 100개 증가하고,
width를 1 증가시키면 weight는 191개 증가한다.
따라서 이 문제에서는 width를 1 증가시키는 경우가 weight 수를 더 많이 증가시킨다.
그 이유는 depth를 늘리면 새로운 연결이 1개만 추가되지만, width를 늘리면 모든 hidden layer 사이의 weight matrix 크기가 함께 커지기 때문이다.
Problem 4.6 Consider a network with input, output, and layers, with hidden units in each. Would the number of weights increase more if we increased the depth by one
Pass
Problem 4.7 Chosse values for the parameters for the shallow neural network in equation 3.1 (with ReLU activation functions) that will define an identity function over a finite range
equation 3.1 :
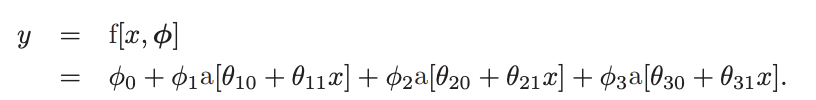
[a, b]에서 RELU가 모든 구간에서 활성화가 되고,
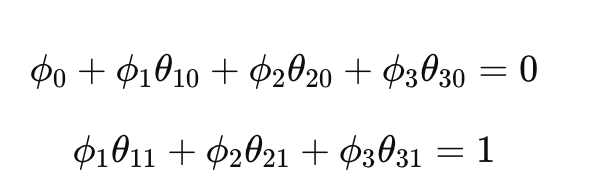
이것을 만족하면 된다.
Problem 4.8 Figure 4.9 shows the activations in the three hidden units of a shallow network (as in figure 3.3). The slopes in the hidden units are , , and , respectively, and the "joints" in the hidden units are at positions , , and . Find values of and that will combine the hidden unit activations as to create a function with four linear regions that oscillate between output values of zero and one. The slope of the leftmost region should be positive, the next one negative, and so on. How many linear regions will we create if we compose this network with itself? How many will we create if we compose it with itself times?
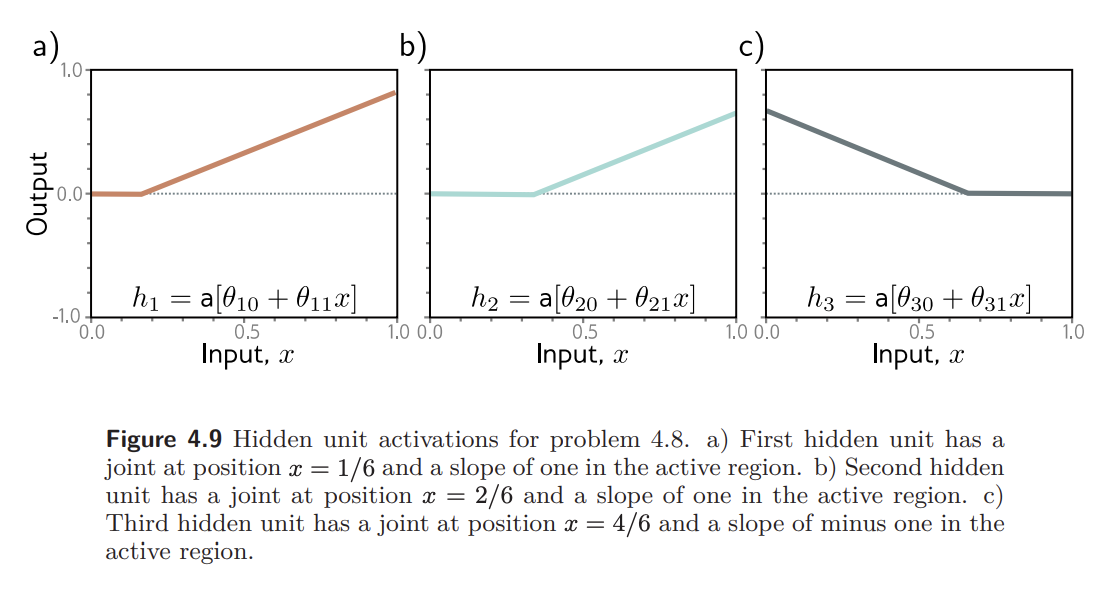
주어진 세 hidden unit의 joint는 x=1/6, 2/6, 4/6 이므로
전체 함수는 총 4개의 linear region을 가진다.
우리는 출력층
f(x)=φ0+φ1h1(x)+φ2h2(x)+φ3h3(x)
를 적절히 선택하여, 각 구간의 기울기 부호가
+, -, +, -
가 되도록 해야 한다.
즉, 각 구간에서 활성화되는 hidden unit들의 기여를 더한 전체 기울기가
번갈아 양수, 음수, 양수, 음수가 되도록
φ1, φ2, φ3를 정한다.
또한 함수값이 0과 1 사이를 오가도록
각 joint에서의 함수값이
0 → 1 → 0 → 1 → 0
형태가 되게 맞추며,
이를 위해 절편 항 φ0를 함께 조정한다.
이렇게 얻은 함수는 4개의 linear region을 가지는
oscillating piecewise linear function이다.
Problem 4.9 Following Problem 4.8, is it possible to create a function with three linear regions that oscillates back and forth between output values of zero and one using a shallow network with two hidden units? Is it possible to create a function with five linear regions that oscillates in the same way using a shallow network with four hidden units?
figure 4.9 :
답안
네, 두 경우 모두 가능하다.
1차원 입력을 가지는 shallow ReLU network에서는 hidden unit이 개일 때, 입력축 위에 최대 개의 선형 구간(linear regions)을 만들 수 있다.
따라서 hidden unit이 2개이면 최대 3개의 선형 구간을 만들 수 있고, hidden unit이 4개이면 최대 5개의 선형 구간을 만들 수 있다.
또한 출력층에서 hidden unit들의 출력을 적절히 선형결합하면, 전체 함수의 기울기를 구간마다 바꿀 수 있다.
그래서 함수가 단순히 증가하거나 감소하는 형태뿐 아니라,
처럼 올라갔다가 다시 내려오는 형태나,
처럼 여러 번 번갈아 진동하는 형태도 만들 수 있다.
따라서,
- hidden unit이 2개인 경우, 3개의 선형 구간을 가지면서 출력이 0과 1 사이를 왕복하는 함수를 만들 수 있다.
- hidden unit이 4개인 경우, 5개의 선형 구간을 가지면서 출력이 0과 1 사이를 번갈아 오가는 함수를 만들 수 있다.
즉, 문제에서 제시한 두 경우는 모두 가능하다.
Problem 4.10 Consider a Deep Neural Network with a single input, a single output, and hidden layers, each of which contains hidden units. Show that this network will have a total of parameters.
이해 완료
Problem 4.11 Consider two Neural Networks that map a scalar input to a scalar output . The first Network is shallow and has hidden units. The second is deep and has layers, each containing hidden units. How many parameters does each network have? How many linear regions can each network maek (see equation 4.17)? Which would run faster?
두 네트워크의 파라미터 수는 거의 비슷하게 설계되어 있다.
하지만 deep network는 여러 층을 순차적으로 통과해야 하므로, 실행 속도는 보통 shallow network가 더 빠르다.
반면 deep network는 같은 수준의 파라미터 수로도 더 많은 linear regions를 만들 수 있어 표현력이 더 크다.
