[논문 리뷰] Octo: An Open-Source Generalist Robot Policy
Abstract
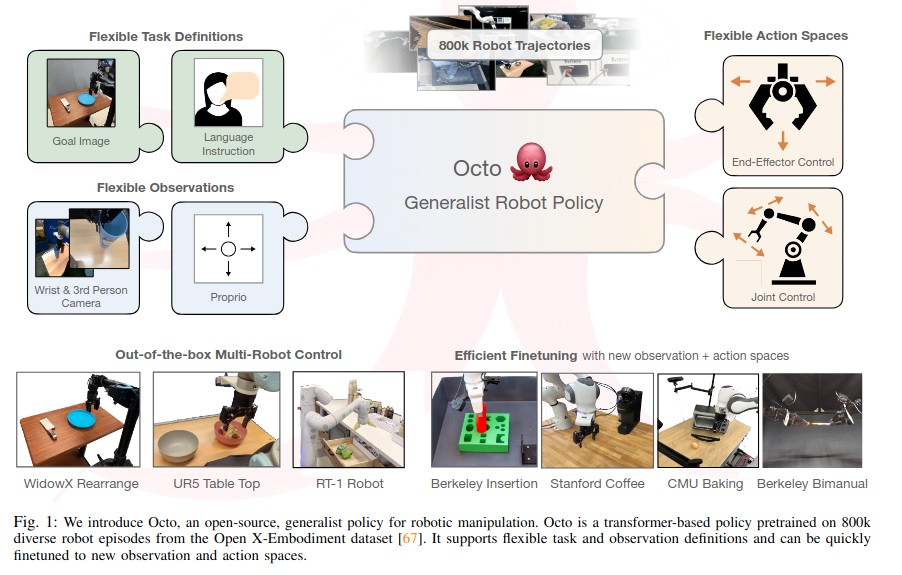
Octo는 Open X-Embodiment에서 수집한 80만개 trajectory로 학습된 대형 transformer 기반 policy model이다. Octo는 자연어 명령이나 목표 이미지를 통해 지시를 받을 수 있으며, finetuning도 효과적으로 할 수 있다. 9종의 로봇 플랫폼을 대상으로 한 실험에서, 서로 다른 환경에서도 finetuning할 수 있는 policy initialization이 된다.
Introduction
Robotic Foundation models - robot observation을 action과 맵핑, 새로운 도메인과 로봇에 zero-shot이나 few-shot generalization를 제공함
=> 이런 모델을 "generalist robot policies (GRPs)"라고 함
(low level visuomotor control을 수행하는데 씀)
기존의 모델들은 input observation 제한 (단일 카메라 stream같이 정해진 입력만 받을 수 있음)이 되어 있거나, finetuning 하기에 어렵고, 공개 라이선스로 배포되지 않아서 쓰기에 어렵다.
그래서 Octo는 downstream robotic application에 잘 맞을 수 있게끔 generalist robot policy를 pretrain 할 수 있게끔 system을 디자인했다.
- input token (observation이랑 task에서 만들어지는)을 output token(action으로 decode됨)에 mapping하는 transformer architecture
- 추가적인 학습 없이도, 다른 camera configuration들을 수용 가능함
- 가장 중요하게도, 새로운 로봇 setup들에 적용 가능함 (즉,더 wider range)
The OCTO Model
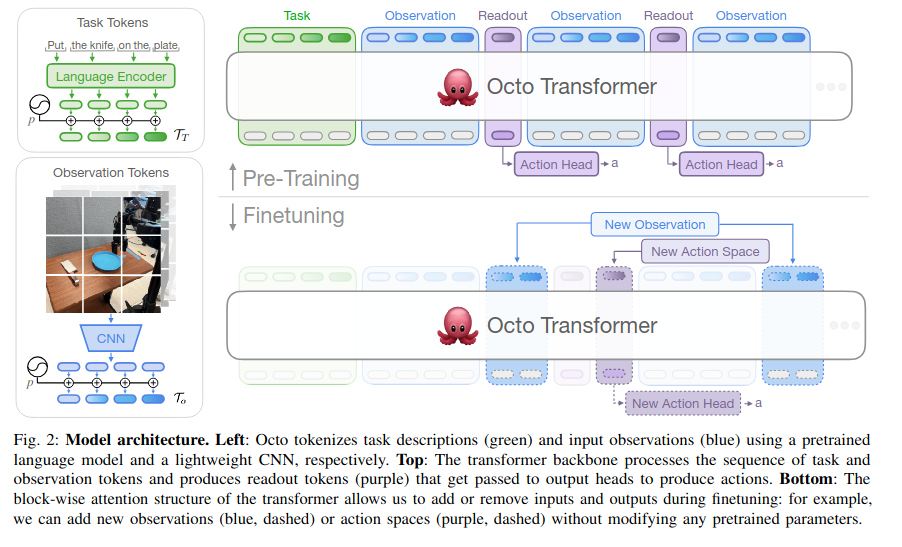
Octo model은 flexibility랑 scale을 강조한다. 또, diffusion decoding으로 자연어 명령어, 목표 이미지, observation history와 멀티모달을 제공한다. 새로운 robot에도 효율적인 finetuning을 할 수 있게끔 한다.
1. Architecture
Octo는 transformer-based policy π이다.
3개의 부분으로 구성되어 있다.
- input tokenizers - language instruction l, goals g, observation sequences o_1,,,o_H를 tokens[T_l,T_g,T_o]로 변환함
위의 그림에서 왼쪽 부분을 보면, language: T5-base 모델로 tokenize 후 embedding sequence 생성, observations, goals: 얕은 CNN → 패치 분할(flattened patch)
=> input sequence 구성: Task token T_T(language, goal)랑 Observation token T_o,,,에 학습 가능한 position embeddings p를 더해서 한줄로 배치함 T_T , T_o,1, T_o,2,
-
transformer backbone - token들을 처리해서 embedding (el, e_g, e_o)을 생성함
e_l, e_g, e_o = T(T_l, T_g, T_o)
Readout token들(T(R,t))을 넣어서 observation이나 task token들을 읽어서 그들에게 영향을 주지 않고 하나의 벡터로 요약함. -
readout heads R(e) - token embedding을 원하는 출력(action)으로 변환함, diffusion 기반 action head가 여러 단계의 동작 chunk를 예측함.
2. Training Data
25개의 OpenX-Embodiment 데이터셋을 조합해서 학습에 사용함, image stream이 없거나 delta end-effector를 사용하지 않거나 너무 낮은 해상도, 너무 특이한 task, 너무 반복적인 데이터셋은 제거함. 더 다양한 데이터셋들은 학습 시 가중치를 2배로 설정하고 반복적인 데이터셋은 가중치를 낮춤.
3. Training Objective
Transformer backbone은 행동 예측 한번당 한번만 forward pass를 수행하고, 나머지 복잡한 denoising 과정은 가벼운 diffusion head 내부에서 처리됨. 이런 policy parameterization 방식이 MSE loss기반 정책보다 zero-shot이나 finetuning 평가에 더 성능이 좋았음.
action을 생성하기 위해, Gaussian Noise를 샘플링하고 K단계 denoising을 수행함, diffusion head를 기존 DDPM 방식에 따라 학습함. (행동 데이터에 gaussian noise 추가하고 원래 행동을 복원하도록 denoising network를 train함)
Experiments
Zero-shot Evaluation(train할 때 본 적 없는 task에 대해 바로 평가): RT-1-X보다 Octo가 훨씬 좋고 RT-2-X랑은 비슷함.
Data Efficient Fine-tuning: 새로운 domain에 대해서 Octo가 scratch나 사전 학습된 VC-1보다 훨씬 파인튜닝을 잘함.
