
Abstract
- 이 모델은 이질적인 다양한 작업에 대한 co-training을 통해 광범위한 일반화를 가능하게 함
- π0.5 시스템은 이미지 관찰, 언어 명령, 객체 탐지 등을 결합한 hybrid multi modal example들과 공동 학습 방식을 사용함
Introduction
기존 문제점
- open world generalization은 physical intelligence 분야에서 가장 큰 미해결 문제다.
로봇이 실제 세계에서 마주할 상황의 다양성은 단순한 데이터 scale만으로는 해결되지 않음 - 충분히 다양한 장면과 객체가 데이터에 포함 되어있으면 쉽게 일반화 될 수 있지만, 또 다른 동작들은 기존 기술을 새로운 방식이나 순서로 응용하거나 수정해야 됨, 아니면 이전 지식에 기반해서 이해해야 됨.
사람들도 경험을 모두 직접적으로 겪거나 반복학습만으로 얻어지는게 아님. 그래서 일반화 가능한 로봇 학습 시스템도 이렇게 경험과 지식을 transfer할 수 있어야함
그래서 이질적인 데이터는 장애물이 되긴 하지만, vla는 이를 co-training framework을 통해 해결 할 수 있음.
π0.5
π0.5는 π0을 기반으로 해서 다양한 데이터를 이용해서 훈련 중 한번도 본적 없는 집에서도 작업을 수행 할 수 있도록 함.
이 모델은 이러한 출처로부터 경험을 수집함
- 실제 가정 환경에서 다양한 이동형 로봇으로 수집한 약 400시간 분량의 중간 규모 데이터셋
- 고정형 로봇으로부터의 데이터
- 실험실 환경에서 수집된 관련 작업 데이터
- 로봇 관찰을 바탕으로 고수준 의미론적 작업 예측을 요구하는 훈련 예시
- 사람으로부터 로봇에 제공된 언어 명령
- 웹 기반 멀티모달 데이터에서 생성된 이미지 captioning, 질문 응답, 객체 위치 예측 등의 예시
즉, 이렇게 97.6%가 실제 가정에서 이동형 로봇이 수행한 데이터가 아니라 다양한 출처로부터의 데이터이다. 그럼에도 불구하고 새로운 가정 환경에서도 mobile manipulator들을 제어하고 섬세한 작업들 (침대 정리, 수건 걸기) 뿐만 아니라 10~15분에 걸친 장기 조작 작업(주방 전체 청소)도 high-level prompt만으로 수행 가능함.
π0.5의 설계
π0.5은 단순한 hierarchical 구조를 따름
1. 이질적인 학습 데이터들로 pretrain 수행
2. 저수준/고수준 행동 예시를 통해 mobile manipulation에 맞춘 fine-tuning함
3. 실시간 추론 시, 의미 기반 subtask를 예측하고 적절한 행동을 결정한 후, low-level 로봇 행동 시퀀스를 예측함
=> 복잡한 장기 작업을 단계적으로 수행하는데 필요한 추론 능력과 고수준/저수준에서 다양한 출처를 활용할 수 있는 유연성을 동시에 제공함
완전히 새로운 환경에서 장기적이며 섬세한 조작 기술을 수행할 수 있는 end-to-end learning robotic system을 제안한건 처음이다.!
Preliminaries
VLA 모델은 일반적으로 다양한 로봇 시연 데이터셋에 대해 imitation learning을 통해 학습함
주어진 관측값 o_t와 자연어 작업 지시 l에 대해 행동 a_t의 log-likelihood를 최대화하는 방식이다.
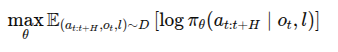
modality에 특화된 tokenizer를 이용해서 입력과 출력을 토큰 표현으로 변환하며, autoregressive transformer backbone이 이러한 입력 토큰을 출력 토큰으로 mapping하도록 훈련됨
policy의 입력과 출력을 토큰화된 표현으로 인코딩해서 next-token prediction 문제로 전환 될 수 있음, action에 대해서는 compression-based tokenization이 효과적임
이 모델은 post-training 단계에서 행동 분포를 flow matching 방식으로 표현함
The π0.5 Model and training recipe
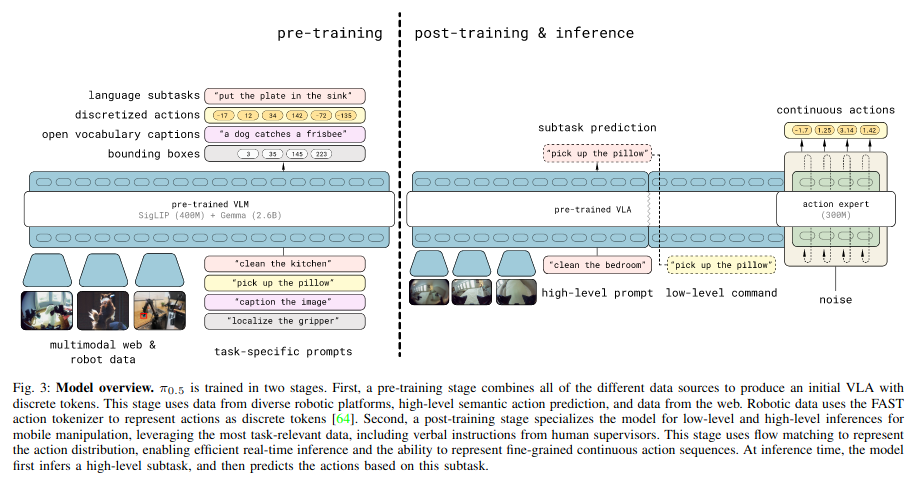
훈련은 pre-training와 post-training 단계로 진행된다.
- pre-training: 다양한 로봇 task에 적응하도록 학습시킴, 모든 작업이 discrete token으로 표현됨
단순, 확장 가능, 효율적인 학습 가능 - post-training: action expert를 모델에 도입, 더 정밀한 행동 표현 가능
- inference: 로봇은 고수준 subtask를 생성하고 이를 조건으로 action expert를 통해 low-level 로봇 행동 생성함
(부엌 정리하기 명령이면, 고수준 subtask는 도마 집기, 서랍 열기, 접시를 선반에 두기 등등, 그런 다음 해당 subtask를 condition으로 해서 정밀한 action chunk를 생성하는 식이다)
The π0.5 architecture
-
모델이 학습하는 확률 분포
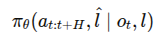
o_t: 모든 카메라에 대한 이미지들+ 로봇 상태 정보 (joint angle, base velocity 등등..)
l: 주어진 text prompt (ex. 접시를 정리하라)
l_^: 모델이 예측한 text prompt (접시를 집어라)
a_t:t+H: 예측된 action chunk -
이 논문에서는 분포를 다음처럼 두 부분으로 나눠서 표현한다.
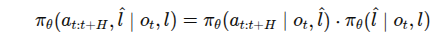
우측의 뒤의 항은 high level inference이고 앞의 항은 그 결과에 따른 실제 행동 생성으로 low level inference이다.
모델은 transformer 구조로 구성되어 있으며, 입력은 총 N개의 multimodal 입력 토큰이고 출력으론 transformer를 거쳐야함.
-
입력
각 입력의 토큰은 텍스트, 이미지, 행동 토큰 중 하나이고, 각각 다 다른 encoder, 다른 expert weight를 적용할 수 있음. -
Attention Matrix A(x_1:N)
어느 토큰이 어느 토큰에 attention을 둘 수 있는지를 나타냄, 일반적인 llm의 attention은 왼쪽만 보는데 π0.5은 양방향 attention 사용해서 상호 정보 공유 가능함 -
출력
text token logit과 action output token으로 나뉨.
처음부터 M개까지가 text token logit (고수준 subtask 예측)이고, M+1부터 M+H번까지가 행동 출력으로 action output token들이다. 이렇게 행동 출력은 action expert을 통해 생성되고 linear mapping을 통해서 연속적인 행동 벡터로 변환됨.
모든 output들을 loss 계산에 사용하는 건 아님.
Combining discrete & continuous action representations
기존에는 autoregressive 방식을 사용해서 행동을 토큰으로 만들고 하나씩 순차적으로 예측함
flow matching 기법을 사용해서 연속적인 행동을 예측함.
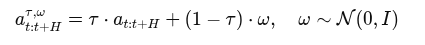
위는 flow matching 식으로, 실제 행동 시퀀스 a_t:t+H를 noise와 섞어서 행동(좌측 항)을 만듦
그 다음 이 좌측 항을 모델에 넣고 진짜 행동쪽으로 flow vector를 예측하게 함
즉 노이즈에서 진짜 행동으로 가는 방향 벡터 (ω − a_t:t+H)를 학습 하는 것이다.
(diffusion model과 비슷해보이지만, 이는 one shot inference도 가능하며, 추론 속도도 훨씬 빠름. 또 diffusion모델은 noise 추가하고 복원하는 과정을 markov chain으로 수백 step을 돌리지만, flow matching은 deterministic한 flow vector 예측만으로 수십 step이내에 동작함)
행동을 discrete token으로 표현하면 VLA 모델 훈련 속도가 훨씬 빨라지지만, discrete token은 real-time inference에 맞지 않고 autoregressive decoding(한 token씩 순차적으로 예측)을 요구하므로 연산이 비쌈
=> 그래서 train할 때는 FAST tokenizer(discrete token)와 flow matching(continuous action) 모두 사용하고, inference할 때는 flow matching 방식만 사용해서 빠르게 연속적인 행동을 생성한다.
이렇게 두 행동 표현 방식(discrete, continuous)이 서로 영향을 주지 않도록, attention matrix을 조정해서 서로 간섭하지 않도록 함.
-
Loss
모델은 다음과 같은 combined loss을 최소화함
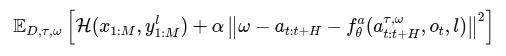
H는 text와 discrete 행동 토큰에 대한 cross entropy loss이고, 제일 뒤에 달린 f() 식은 action expert에서 예측한 연속 행동 출력이다. -
학습 전략
pre-train 단계에서는 α를 0으로 설정하고 모든 행동을 text token화 된 형태로만 학습해서 standard VLM transformer model처럼 학습함
post-train 단계에선 α>0으로 설정하고 action expert 가중치를 추가해서 연속 행동 예측이 가능하도록 학습함, 이때는 non-autogressive 방식으로 동작해서 빠름
추론 단계에서는 text token에 대해서 standard autoregressive decoding 사용하고 이후 행동 예측은 flow matching 기반 10 step denoising 수행해서 최종적인 action을 만듦.
Pre-training

standard auto-regressive transformer 구조로 train됨, next-token prediction을 수행함.
사용된 데이터 종류
1. Diverse Mobile Manipulator data (MM)
- 400시간의 데이터
- 약 100개의 실제 가정환경에서 수집
- 실제 inference task와 가장 유사한 데이터
- Diverse Multi-Environment non-mobile robot data (ME)
- 집에 고정된 형태(non mobile)의 팔이 하나나 두개인 로봇
- mobile 로봇과 embodiment가 다름
- Cross-Embodiment laboratory data (CE)
- 실험실에서 간단한 책상 위에서의 다양한 작업 (셔츠 접기)을 수행한 데이터
- 여러 형태의 로봇으로 수집
- 오픈 소스 OXE 데이터셋도 포함함
- High-Level subtask prediction (HL)
- "침실 정리하기" -> "이불 정리하기", "베개 줍기"
- Chain-of-thought prompting처럼 고수준 명령어를 더 작은 subtask로 분해함
- 위의 3가지 데이터에 대해 수동으로 semantic subtask label을 주고 모델보고 이를 텍스트로 예측하고 해당 subtask에 맞는 행동 예측까지 학습하게 함
=> 이를 통해 highlevel policy랑 lowlevel policy까지 둘다 수행 가능한 모델로 train함
- Multi-modal Web Data (WD)
- 다양한 웹 기반 데이터로 구성함 (image captioning, question answering, object localization)
- 모델이 언어와 시각 정보로부터 의미 이해를 학습하는데 활용함
=> 모든 action data는 target joint(목표 관절)와 end-effector pose(말단 위치)를 예측하게끔 train함.
Post-training
π0.5는 pretraining에서 28만 step동안 discrete token을 사용해서 학습한 후에 post-train 단계로 넘어감.
목적
- 가정환경에서의 mobile manipulation task에 모델을 특화하기 위해
- action expert를 추가해서 flow matching을 통해 continuous action chunk를 생성하기 위해
post-training에서도 next-token prediction을 수행하면서 동시에 새로 추가된 action expert도 random 초기화 해서 flow matching 방식으로 연속 행동을 예측함
데이터는 위에꺼랑 거의 동일하게 사용하는데 Verbal Instruction (VI)을 추가적으로 수집해서 사용함.
VI는 expert user들이 로봇한테 언어 명령을 실시간으로 주면서 teleoperation함(high level subtask를 text로 단계별로 명시하고 그 명령에 따라 로봇이 학습된 low level policy로 동작함)
=> 고수준 명령어를 정확히 생성하는 능력을 더 잘 갖추게 함 (어떤 상황에서 어떤 highlevel subtask 출력을 생성해야 하는지를 학습할 수 있도록 지원)
쉽게 말하자면, "청소해" 같은 추상적인 명령을 상황에 맞는 구체적인 subtask "이불 개기"로 분해하는 능력을 배울 수 있게끔 하는 것
Robot system details

위에서 보이는 그림과 같이 두가지 종류의 mobile manipulator platform을 사용해서 모든 실험을 수행하였음.
하드웨어 구성
- 팔 - 양팔 시스템, 6자유도 (DoF)+ Parallel-jaw gripper
- 카메라 - 4개의 RGB 카메라
완전한 end-to-end 제어 시스템으로 모든 제어를 직접 생성함
Experimental Evaluation
-
π0.5는 실제 가정에서도 일반화할 수 있는가?
=> multi-stage task들을 간단한 high-level command만으로 high-level inference를 통해 적절한 하위 행동들을 스스로 결정함. -
일반화 성능은 장면 수에 따라 어떻게 확장되는가?
mobile manipulation 데이터를 포함한 환경수를 달리해서 학습을 수행함. 환경 수는 총 3,12,22,53,82,104개의 장소로 조절함.
학습 단계 수는 4만(40k)으로 고정해서 데이터 샘플의 개수는 모두 같고 모두 학습시에 보지 못한 mock환경에서 평가함
=>
