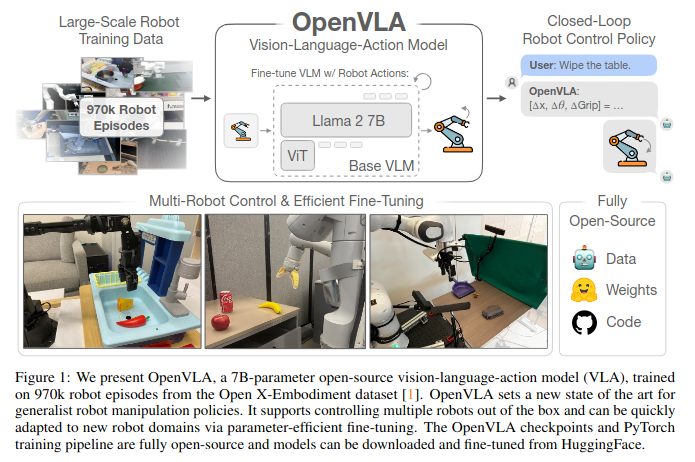
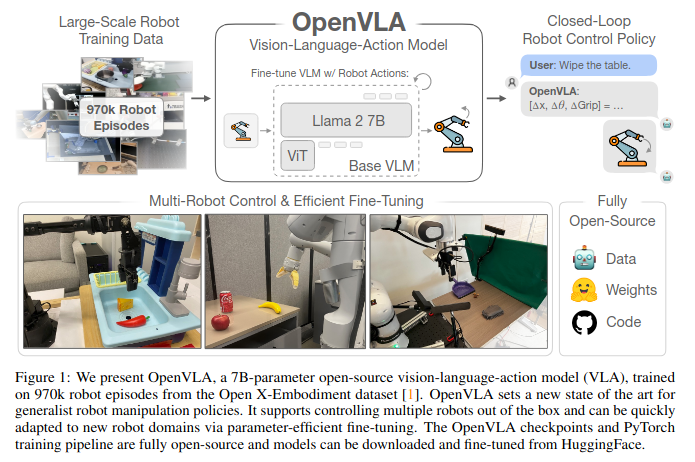
Abstract
OpenVLA는 970,000개의 로봇 에피소드를 기반으로 학습된 7B 파라미터의 오픈 소스 비전-언어-행동 모델(VLA)이다. 이는 Llama 2 언어 모델 및 DINOv2 및 SigLIP의 사전 학습된 기능을 융합한 visual encoder를 결합해서 동작한다. 또, 새로운 환경에서 효과적으로 Fine-tuning이 가능하며, 뛰어난 일반화 성능을 보인다. 이는 기존의 VLA 모델들보다 더 좋아진 성능을 보인다.
Preliminaries: Vision-Language Models
VLM의 architecture
1. 이미지 입력을 Image Patch Embedding으로 mapping하는 Visual Encoder
2. Visual Encoder의 출력 Embedding을 받아 언어 모델의 입력 공간으로 mapping하는 projector
3. VLM 훈련 중, 모델은 Vision과 Language 데이터를 pair 형태로 결합하여 text token 예측 목표로 끝까지 train되는 LLM backbone
Method
1. Visual Language Model Backbone
OpenVLA는 Prismatic-7B VLM을 기본으로 사용한다. 이 VLM은 2개의 visual encoder (SigLIP와 DINOv2)로 구성되어 있으며, 다중 해상도의 이미지 patch를 동시에 처리해서 시각적 특징을 추출한다.
2. OpenVLA Training Procedure
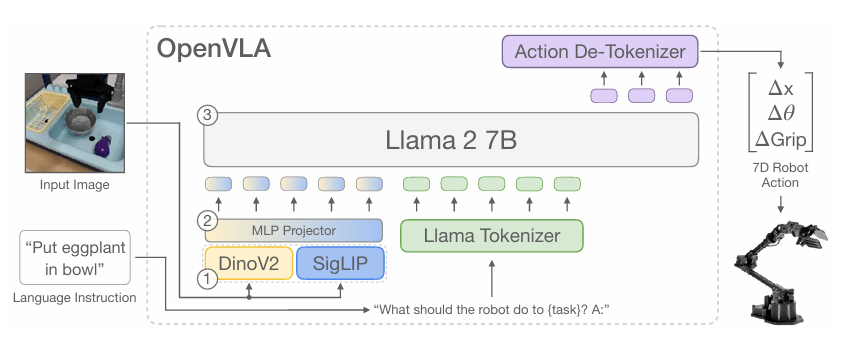
사전 학습된 Prismatic-7B VLM Backbone을 로봇 행동 예측을 위해 Finetune한다. VLM 언어 모델이 로봇 행동을 예측하기 위해, 로봇 행동을 연속적인 값에서 언어 모델의 Tokenizer가 사용되는 discrete token을 매핑해서 llm의 출력 공간에서 행동을 표현한다. 로봇 행동은 각 차원을 개별적으로 256개의 구간 중 하나로 discretize을 quantile을 사용하여 해서 이상치 행동을 무시할 수 있어, action discretization을 효과적으로 할 수 있다.
3. Training Data
Open X-Embodimnet 데이터셋을 기반으로 training data를 구성한다. 이 데이터셋은 70개 이상의 개발 로봇 데이터셋으로 구성되어 있으며, 200만개 이상의 로봇 궤적을 포함하고 있다.
이 데이터를 train할 때 사용하기 위해, data curation을 적용한다.
모든 train 데이터셋에서 일관된 입력과 출력 공간을 보장하기 위해, Open X-Embodiment Collaboration와 Octo Model을 따르며 훈련 데이터셋을 적어도 하나의 3인칭 카메라가 있는 조작 데이터셋만 포함되도록 제한하고, 단일 팔 end effector control만 사용한다.
최종 train에서 구현, 작업, 장면의 균형 잡힌 조합을 보장하기 위해 모든 데이터셋에 대해 Octo와 데이터 혼합 가중치를 사용한다.
