Introduction
배경: 픽셀 이미지만 보고도 게임이나 로봇을 잘 제어할 수 있는 알고리즘들이 많이 나왔지만 여전히 샘플 효율성이 낮다는 문제가 있다. 즉, 환경에서 너무 많은 경험(데이터)을 필요로 한다.
과거 연구들은 이 문제를 해결하려고, agent가 스스로 학습하게 하는 self supervised learning 기법을 도입했지만 대부분은 discrete한 action 공간만 고려하고 연속적인 제어 문제에서는 효과가 떨어진다.
이 논문에서는 TACO (Temporal Action-driven Contrastive Learning) 라는 방법을 제안한다.
현재 상태랑 action sequence를 보고 그 결과로 미래 상태를 예측할 수 있게 상태와 액션을 latent representation으로 바꿔주는 방법을 학습한다. 이걸 contrastive learning을 써서 진짜 set과 가짜 set을 구분하게 만들어서 좋은 representation을 찾는 것이다.
Main Contributions
-
We present TACO, a simple yet effective temporal contrastive learning framework that simultaneously learns state and action representations.
-
The framework of TACO is flexible and could be integrated into both online and offline visual RL algorithms with minimal changes to the architecture and hyperparameter tuning efforts.
-
We theoretically show that the objectives of TACO is sufficient to capture the essential information in state and action representation for control.
-
Empirically, we show that TACO outperforms prior state-of-the-art model-free RL by 1.4x on nine challenging tasks in Deepmind Control Suite. Applying TACO to offline RL with SOTA algorithms also achieves significant performance gain in 4 selected challenging tasks with pre-collected offline datasets of various quality.
Method

위 식에서 Z_t+K는 미래 상태의 표현, U_t+...+U_t+K-1은 현재 상태의 표현이다. 이 둘이 얼마나 관련이 있는지를 수치화해서 보여주는 상호 정보량(Mutual Information)을 나타낸다.
즉, 현재 상태와 행동을 보고 미래 상태 표현이 더 잘 예측되도록 학습하는 것이다.
Theorem 3.1
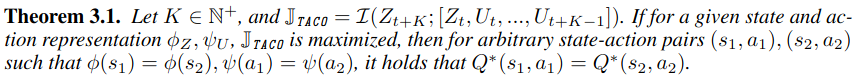
TACO의 mutual information 목적 (위의 2번식)을 최대화하면, 표현만 같으면 Q값도 같아진다.
상태-행동 쌍 (s1,a1), (s2,a2)가 있을 때, 표현이 같으면: ϕ(s1)=ϕ(s2), ψ(a1)=ψ(a2)
=> 최적 Q 함수도 같다. Q∗(s1,a1)=Q∗(s2,a2)
즉, 표현만 같으면 행동 결정도 같아져야 하니깐, 이 표현은 정말 의미있는 Q함수 계산에 필요한 정보를 모두 담도록 만들어진다.
TACO의 3가지 Loss Function
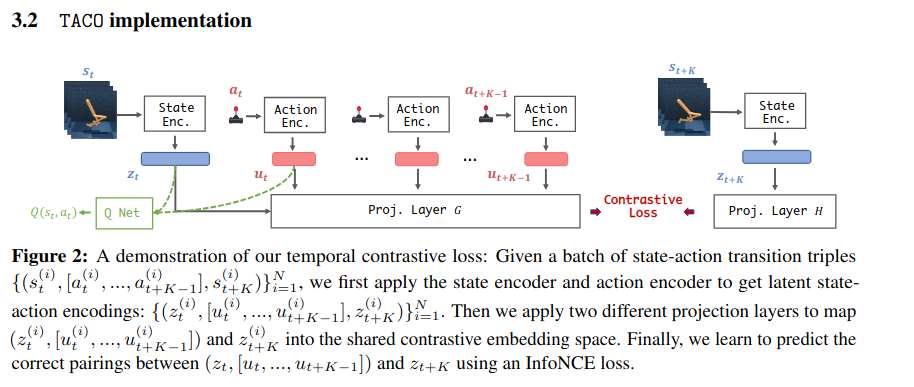
TACO는 기존 강화학습 알고리즘 DrQ-v2에 3개의 loss함수를 추가하여 학습 성능을 향상시키는 방식이다.
- TACO contrastive loss - 현재 상태+현재 행동이 미래 상태를 잘 예측하도록, g(현재 projection)와 h(미래 상태 projection)를 같은 공간으로 보내서 contrastive하게 학습함
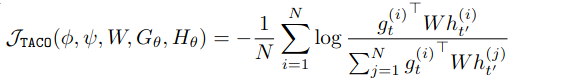
- CURL loss - 같은 이미지에 대해 augmentation을 해도 표현이 비슷하게 나오도록 유도함, h_t는 s_t에 랜덤 shift 같은 augment를 한 상태
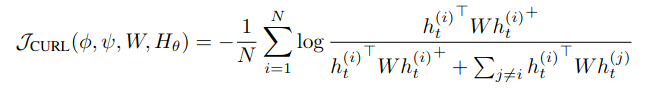
- Reward Prediction - 실제로 받은 보상들의 합과 예측한 총 보상의 차를 이용해서 학습시킴
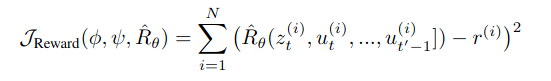
세가지 손실을 모두 동일한 가중치로 합침.
J_total=J_TACO+J_CURL+J_Reward
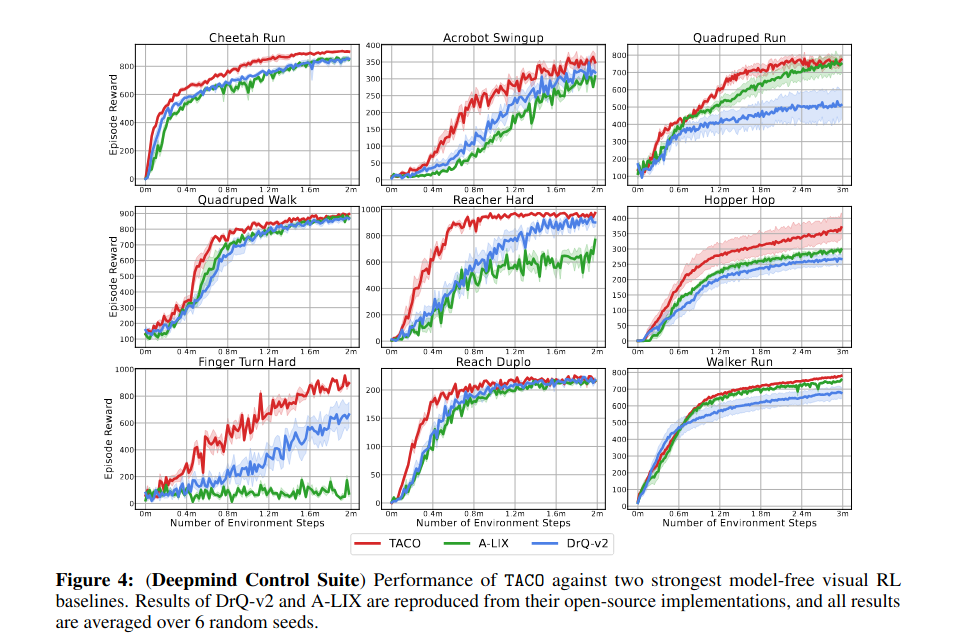
Result
SOTA visual RL 알고리즘에 비해서 sample efficiency랑 performance가 훨씬 좋다.