
📌Ensemble
여러 모델의 예측값을 결합하여 최종적으로 예측을 진행하는 모델
- weak learners 를 결합하여(편향 또는 분산을 줄여) strong learner를 만드는 것
Ensemble
분산이 낮고, 편향이 높은 경우
├── Bagging
분산이 높고, 편향이 낮은 경우
└── Boosting
📌오차
편향 오차 : 지나치게 단순한 모델로 인한 오차로, underfitting이 될 수 있음
분산 오차 : 지나치게 복잡한 모델로 인한 오차로, overfitting이 될 수 있음
noise는 모델을 만들며 조작할 수 없는 오차
편향-분산 Trade-off
- 모델 복잡도가 올라가면 편향(Bias)은 줄어드나 (↓) 분산(Variance)은 올라감(↑)
- 모델 복잡도가 낮아지면 편향(Bias)은 올라가나 (↑) 분산(Variance)은 줄어듬(↓)
편향과 분산은 trade-off 관계에 있다.
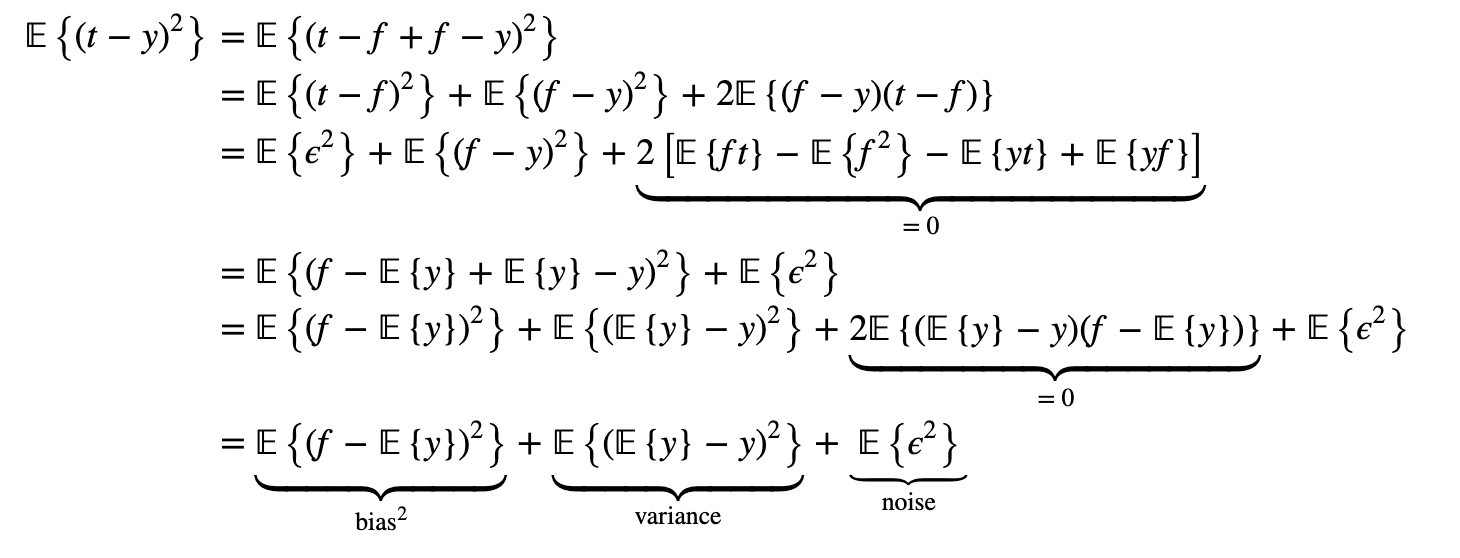
위에서 noise에 해당하는 𝔼{ϵ2} 항은 우리가 학습시키고자 하는 모델 y와는 독립적이기 때문에 학습을 통해 최소화하는 것이 불가능하다. 따라서 MSE를 최소화하기 위해서는 bais와 variance를 최소화해야 한다.
그러나 bias를 최소화하기 위해 𝔼{y}=f가 되도록 모델을 학습시킨다면, variance는 noise ϵ의 variance인 𝔼{ϵ2}가 된다. 반대로 variance를 최소화하기 위해 모델 y가 입력 데이터에 상관없이 특정 상수 a만을 반환한다면 𝔼{(𝔼{y}−y)2}=𝔼{(a−a)2}=0이 되겠지만, bias는 크게 증가할 것이다. (Trade-off)
📌앙상블 성립 조건
- 개별 모델은 random guessing보다 높은 예측 성능을 가져야 함
- 개별 모델의 결과는 독립적이고 다양하게 나와야 함
- 이때 개별 모델의 다양성을 위해 작은 변화에도 변동이 큰 모델이 효과적
과적합 된 Decision Tree을 weak(base) learners로 사용
📌Voting
voting : 서로 다른 알고리즘 기반의 모델을 같은 train set으로 학습시킨 결과를 결합
- Hard Voting : 각 모델(분류기)의 결과를 취합하여 가장 많이 예측된 클래스로 최종 예측
- Soft Voting : 모델(분류기)들의 클래스당 예측 확률 값을 평균 내어 가장 높은 확률을 갖는 클래스로 예측
ex)
Hard Voting
Classifier 1 : (A:0.7, B:0.3) -> A
Classifier 2 : (A:0.1, B:0.9) -> B
Classifier 3 : (A:0.6, B:0.4) -> A
-> (A:2, B:1)
-> A
Soft Voting
Classifier 1
Classifier 2
Classifier 3
->
-> B
📌Bagging
Bootstrap : 복원추출
Baggig(Boostrap Aggregating) : 같은 알고리즘을 사용하되 train set에서 중복을 허용하여 샘플링하는 방식
장점
- 편향과 분산 모두 감소
- 개별 모델 병렬 학습 가능
oob(out-of-bag) 평가
선택되지 않은 나머지 샘플(평균적으로 37%)을 가지고 검증세트처럼 사용하여 모델을 평가하는 것
📌Random Forest
여러 개의 decision tree를 형성한 후 개별 tree의 prediction을 구하여 가장 많이 득표한 결과를 최종 분류 결과로 선택하는 것
장점
과대적합 문제 최소화하여 모델의 정확도 향상
- 결측치 다루기 쉬움
- 특성 중요도 측정
-> 어떤 특성을 사용한 Node가 평균적으로 Impurity를 얼마나 감소시키는가?- overfitting을 방지하여 모델 정확도를 향상시킴
단점
- 메모리 사용량이 많아 시간이 오래 걸림
-> XGB의 경우 boosting을 사용한 성능 향상과 속도 향상까지 잡음
📌Boosting
Boosting : sequential(연속적)인 weak learner, 바로 직전 weak learner의 error를 반영하여 현재 weak learner를 개선하는 것
- Additive model(비모수 회귀, 함수 형태를 가정하지 않는 회귀) 모델이다.
ex) AdaBoost(adaptive boosting), gradient boosting
📌Bagging vs Boosting
| Bagging | Boosting | |
|---|---|---|
| 추출 방법 | 전체에서 랜덤 복원추출 | 가중치를 다르게 하여 랜덤 복원추출 |
| 개별 weaklearner 관계 | 독립적 | 의존적(Sequential) |
| Ensemble 방법 | 모든 weak learners 균등한 비중으로 앙상블 | 성능 좋은 weak learners에 가중치 두어 앙상블 |
| 속도 | 빠름 | 느림 |
| 성능 | 적은 데이터로 준수한 일반화 가능 | 좋음 |
📌AdaBoosting
adaboost : 이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높여서 예측기를 만드는 방법(DT 기반)
1. 전체 데이터에서 random sampling
2. 모든 sample 데이터 가중치 초기화
3. 첫번째 weak learner 만들고 학습 후 결과에 따라(맞음 or 틀림) 각 데이터에 가중치(C)와 해당 weak learner의 모델 가중치(w) 출력
4. 3번에서 구한 데이터 가중치(C)로 데이터를 update
5. update된 데이터로 두 번째 weak learner를 만들고 학습한다. 3~5 과정을 N번 반복한다.
6. N번의 iteration 후, N개의 weak learner들에 각각 모델 가중치(w)를 줘서 최종 모델을 만든다.
📌Gradient Boosting
adaboost : 샘플의 가중치를 수정하는 대신 이전 예측기가 만든 잔여 오차를 사용해 학습하는 것
loss function
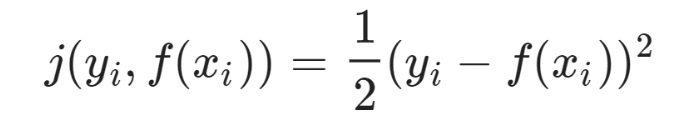
gradient
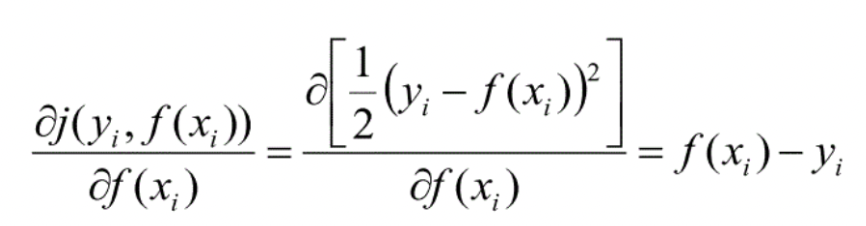
loss function을 MSE로 정의했을 때, negative gradient는 residual과 같다. 따라서 residual을 줄이는 것이 목표이고, 이는 * ResNet의 작동원리와 같다.
gradient boosting의 특징
- AdaBoost와 같이 이전 모델의 결과에 영향을 받음
- 이전 모델이 학습하지 못한 잔차에 초점을 두고 학습하기 때문에 학습되지 않아야 되는 모집단의 오차까지 학습되어 과적합되기 쉬움
overfitting을 막기 위한 방법
- subsampling: 모집단 전체 데이터를 사용하지 않고 일부 샘플링하여 학습
- shrinkage: 나중에 학습된 모델의 가중치를 줄여 영향력을 감소시키는 방법, 모델의
학습이 진행될수록 데이터 오차를 학습하기 때문에 가중치 감소시킴- early stopping: validation set에 대한 성능 개선이 없을 때 학습 중단
📌Stacking
Stacking : base learners의 결과를 취합하는 방법으로 간단한 함수(voting, 평균)대신 간단한 모델을 사용하여 훈련하는 것. base learners의 결과를 사용하여 최종 예측하는 모델을 블렌더 또는 메타 학습기(meata learner)로 부르고 훈련 진행
1) 학습 데이터 셋을 두개로 나눔
2) 하나의 데이터 셋에 대해 base learners 학습
3) 학습된 base learners를 사용해 다른 데이터셋 예측
4) 예측된 값을 input으로 넣고 최종값을 예측하도록 meta learner 학습
