self-supervised learning 이란 무엇일까.
두가지 갈래로 이를 설명할 수 있다.
-
constructing supervised learning tasks for unlabeled data
unlabeled data를 가지고 학습을 하는데 어떻게 supervised로 학습하는지 의문이 들 수 있는데, 그러기 위해서는 unlabeled 데이터를 가지고 어떤 "task"를 만들어야한다.
unlabeld data를 가지고 어떠한 task를 만드는데 이를 "pretext task" 라고 한다.
우리가 임의적으로 이 pretext를 만들어 줄 수 있고 사용자가 만들어준 임의의 task 이기 때문에 self supervised learning 이라는 말이 붙는다.
그래서 이 pretext task를 가지고 self-supervised learing을 진행하게 된다. -
a special type of representation learning
여기서 representation learning 이라는 것은 feature extractor를 학습을 한다라는 것
그렇다면 왜 좋은 feature extractor가 필요한가? 좋은 representation (feature)가 있으면 어떠한 downstream task를 학습하는데 유용하게 활용 할 수 있기 때문이다.
(좋은 feature extractor로 학습된 knoledge를 이용해 transfer learning을 쉽게 할 수 있다.)
++
기존의 ML에서는 feature extractor를 hand-crafted로 만들었고 이 feature를 predictor에 넣어서 학습하는 방식이고, DL에서는 feature extractor와 predictor의 학습이 end-to-end로 이루어졌다.
사실은 feature extractor만 학습하는게 self-supervised learning이라고 볼 수 있다.
ML에서 DL으로 학습 패러다임이 바뀌었지만, 오히려 이제는 self-supervised learning을 통해 다시 기존 머신러닝이 하던 학습방식으로 회기하는 듯한 뉘앙스가 있는 점이 신기하다.
Self-supervised Learning
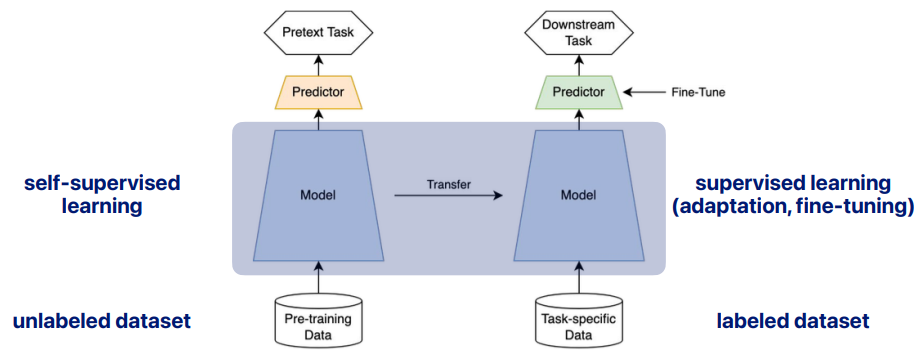
왼쪽이 self-supervised learning으로 학습하는과정, 오른쪽이 그것을 활용한 transfer learning (또는 adaptation, fine-tuning) 의 과정이라고 보면 된다.
왼쪽 편을 보면,
우리가 정의한 pretext task가 있다 생각하고 학습한다. 여기서 model은 feature extractor의 역할을 한다.
이렇게 해서 self-supervised learning이 끝나면 오른쪽에서는,
왼쪽의 모델 (Feature Extractor)부분만 가져와서 Fine tuning이라는 작업을 통해서 downstream task를 학습하게 되는것!
오른편 부분에서는 task에 대한 labeled data가 주어지고 모델(feature extractor)는 재활용 된다. 오른쪽 초록색의 predictor만 주어진 task에 맞게 학습된다.
Self-supervised learning의 pretext task를 어떻게 정의하는가?
어떻게 pretext task를 정의할 수 있나?
크게 두가지 방식이 있다.
-
- Self-prediction
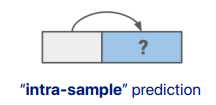
싱글 데이터의 일부를 보고서 나머지를 예측한다.
같은 sample안에서 예측하기 때문에 "intra-sample prediction"이라고 부른다.
데이터의 일부를 모른다고 가정을 한다.
- Self-prediction
-
- Contrastive learning

여러 데이터를 고려하여 그것들 간의 관계를 고려한다.
(e.g. 비슷한 애들은 가까워지고 다른애들은 멀어지는 컨셉)
샘플든 간의 관계를 학습하는 것이라서 "inter-sample prediction" 이라고 부른다.
- Contrastive learning
Self-prediction
1. autoregressive generation
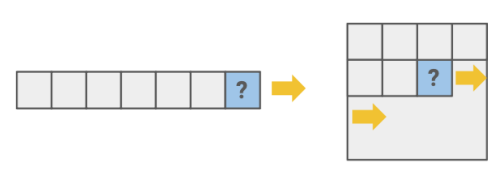
과거를 바탕으로 현재를 예측하는 것
sequence data에서 사용되나 이미지 데이터에서도 사용 가능한데,
이미지 데이터에서는 raster scan order로 2D를 1D로 변환 시킨 후에 순서를 Autoregressive 하게 예측한다.
2. masked generation
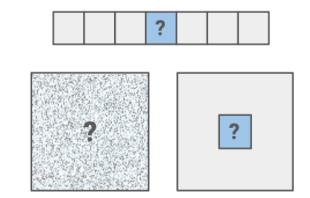
꼭 미래가 아니라 데이터의 아무 부분이나 예측하는 것
3. innate relationship prediction
순서를 일부러 뒤집어서 복원한다든지
jigsaw puzzle 처럼 이미지를 random하게 위치 바꿔서 복원 시키는 형태로 task 정의
데이터의 성질을 이용함
사람의 prior knowledge가 적용됨
Contrastive Learning
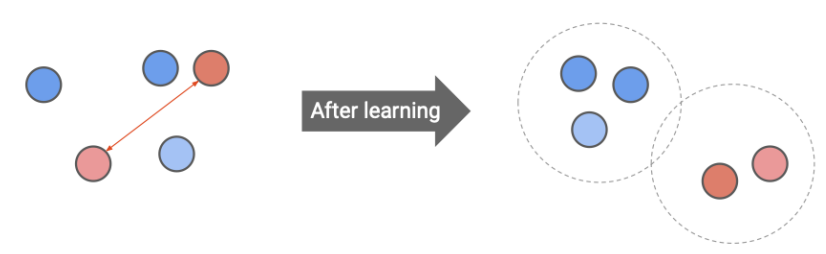
contrastive learning 후에는 비슷한 샘플끼리는 가까워지고, 다른 샘플끼리는 멀어지는 방향으로 학습된다.
이 학습은 feature/embedding/representation level에서 이루어진다.
1. inter-sample classification
제일 많이 쓰이는 방법.
기준이 되는 anchor data point가 있을 때 positive (similar) candidates와 neagative (dissimilar) candidates를 정의하도록 학습된다.
unlabeled data에서 학습을 진행하는 것인데, 그렇다면 어떻게 positive와 negative를 정의할 수 있는가 ?
positive: anchor data 의 augmented 버전을 positive로 정의
negative: anchor data가 아닌 데이터를 negative로 정의
어떻게 loss를 optimize 하는가
-
contrastive loss [Chopra et al., 2005]

여기서 는 feature extractor 인데 feature들끼리의 거리를 줄이거나 늘려준다.
i. anchor와 포인트의 관계가 , positive이면 distance를 줄여줌
ii. anchor와 포인트의 관계가 , negative이면 distance를 증가시켜줌
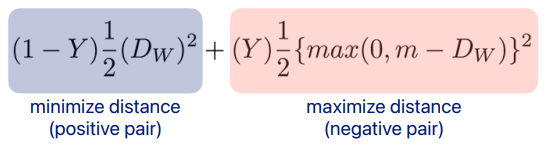
왼쪽 파란 텀은 positive pair에 대해 distance를 minimize, 오른쪽 빨간 텀은 distance를 maximize 해줌 -
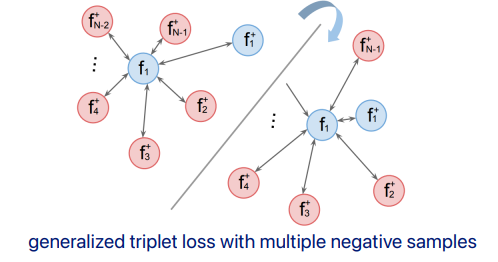
triplet loss [Schroff et al., 2015]
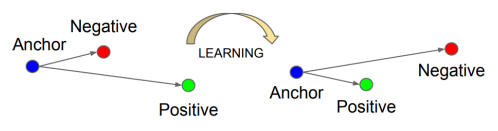
위에서는 negative랑 positive pair중 하나만 optimize하는 방식
그런데 여기서는 neg와 pos 같이 고려함
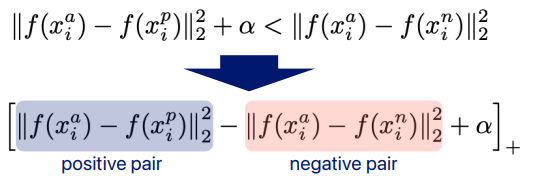
어떤 조건을 만듬
는 margin이라하고 이것이 있는 이유는 이 margin을 두고서 차이가 있도록 해야 학습이 더 잘 되기 때문이다. -
N-pair loss [Sohn et al., 2016]
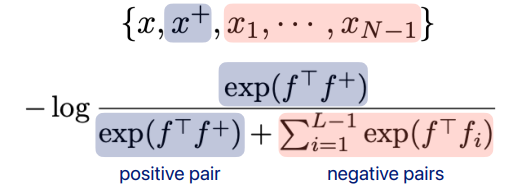
가 original 데이터, 가 positive 데이터, 나머지 가 negative 데이터
positive pair의 거리와 nagative pair의 거리를 구해서 마치 softmax 처럼 loss 구함
-
InfoNCE [van den Oord et al., 2018]
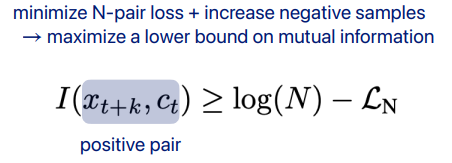
정보이론적인 접근해보면,
Negative sample 이 많아질 수록 학습이 더 잘 될 것이다라는 접근방법
2. feature clustering
-
DeepCluster [Caron et al., 2018]
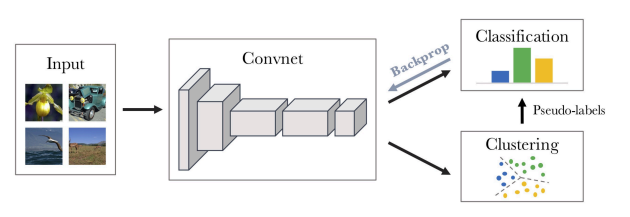
input으로 부터 feature 뽑고 clustering을 진행 -> 그 clustering 결과를 pseudo label로 사용해 학습 진행
-> 학습 후 featue extractor 다시 업데이트
-> 그거에 맞춰서 다시 clustering 진행하고 ... 이런식으로 반복하다 보면 좋은 representation 학습할 수 있게 된다. -
InterCLR [Xie et al., 2021]

- intra-cluster
한 cluster 안에서의 상황
contrastive learning 할 때 일부러 어려운 데이터들로 학습 (hard negative) - inter-cluster
여러 cluster 끼리의 상황 고려
이미 멀리 있는 데이터 들이므로, contrastive learning 할때 좀더 쉬운 데이터들로 스마트하게 학습 (easy negative)
3. multi-view coding
-
AMDIM [Bachman et al., 2019]
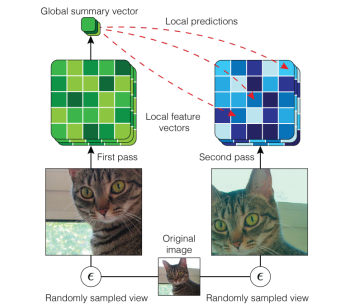
같은 input인데 다른 view에서 본것을 positive sample로써 이용
하나의 이미지를 다르게 croping 해서 다른 view 만듬
한 view에 대해 global한 feature 찾고, 다른 view의 local이랑 같도록 학습
이렇게 하면 representation 안의 global featrue 뿐만 아니라 local feature의 특징이 반영되도록 학습이 됨 -
CMC [Tian et al., 2021]
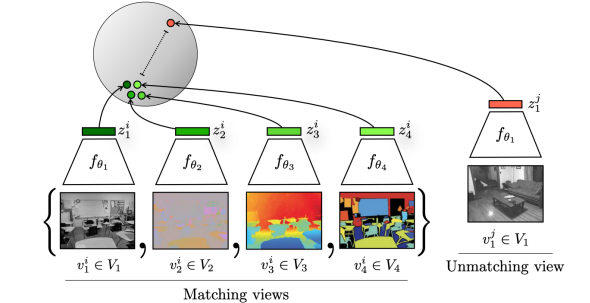
같은 scene인데 다른 type의 data를 positive sample로써 이용
하나의 scene에 대해서 다양한 modality 가질 수 있음, 그것들을 input으로 여러개 들어감
그것들을 각자의 modality에 맞는 feature extractor로 학습하고, 그 feature를 뽑되 그것들이 가깝도록 학습
그냥 다른 scene에 대해서는 멀어지게 끔 학습 -
CLIP [Radford et al., 2021]
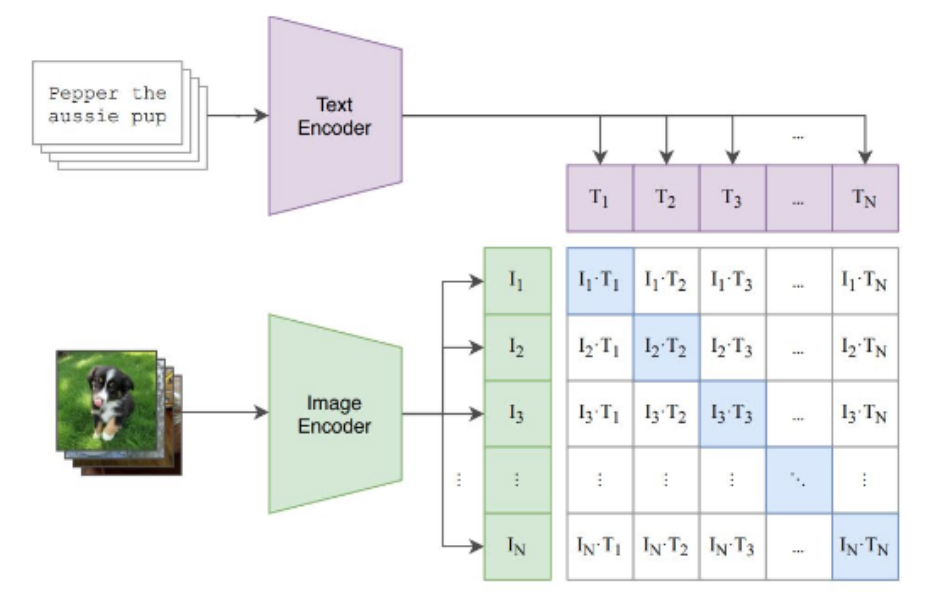
많이 사용됨
이미지에서 나온 feature가 있고 text가 있음
이 데이터가 pairwise (text-image)로 존재
같은 pair끼리는 positive, 다른 pair끼리는 negative로써 이용
Challenges in Self-Supervised Learning Tasks
positive samples
-
Positive Samples
data augmentation (label-invariant transformation)
different models (momentum / noise) -
Negative Samples
hard negative = different labels + similar context
use some labels / sort samples by similarity
use many negative samples (increase mini-batch size) -
High-Quality Large Dataset
unbiased / diverse data
more data, better performance -
Pretext Tasks
how to design and combine
combine with supervised learning ,positive sample과 negative sample을 잘 만드는것도 중요하고
데이터가 다양해야 generalization 성능이 좋고
pretext task는 다양한 것 복합적으로 쓸 수 있고 label 있는 것과 같이 써도 된다.
